詐欺師は単独で行動することはめったにありません。彼らはアカウント、アドレス、デバイス、連絡先を共有するネットワーク内で活動します。従来のルールベースシステムは、各個人を独立して評価するため、これらの隠れた関係性を見逃します。グラフアルゴリズムは、個々の属性だけでなく、人々の間の関係性を分析することで詐欺を検出します。
このチュートリアルでは、PAI Designer の金融リスク管理パイプラインテンプレートを使用して、関係性ネットワーク内の各人の詐欺確率スコアを計算する方法を示します。
パイプラインによる詐欺の検出
パイプラインは、人々を頂点として、その関係性をエッジとして表現します。各エッジには近接度を測定する count 値があり、値が高いほど関係性が強いことを意味します。
3つのグラフアルゴリズムコンポーネントが順次実行されます。
[最大連結部分グラフ] — 関係グラフ内の人物を 2 つのグループに分類し、各グループに ID を割り当てます。その後、SQL スクリプト コンポーネントおよび JOIN コンポーネントと連携して、最も多くの相互接続された人物を含む集合を特定し、関係のない人物を削除します。
単一ソース最短経路 — Enoch が目的の人物に到達するために連絡する必要がある人数を測定します。出力
distanceフィールドは、このホップ数を記録します。ラベル伝播分類 — 既知のケース (例: 詐欺師である Evan) から不正ラベルをネットワーク全体に伝播させます。 ラベルは、ラベル付けされた頂点から隣接する頂点へと伝播します。 出力
weightフィールドには、各人が詐欺師である確率が記録されます。
データセット
パイプラインは、以下のフィールドを持つ関係性データセットを使用します。
| フィールド | タイプ | 説明 |
|---|---|---|
start_point | STRING | エッジの開始頂点。人物の名前。 |
end_point | STRING | エッジの終了頂点。人物の名前。 |
count | DOUBLE | 2人の間の近接度。値が高いほど、より密接な関係性を示します。 |
次の図は、パイプラインで使用されるサンプルデータを示しています。 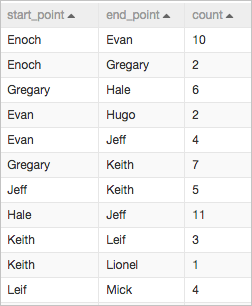
前提条件
開始する前に、以下があることを確認してください。
PAIワークスペース。セットアップ手順については、PAIドキュメントをご参照ください。
Designerを使用するための権限を持つPAIコンソールへのアクセス。
パイプラインの構築と実行
ステップ1: Designerを開く
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。[ワークスペース] ページで、ワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、[モデル学習] > [可視化モデリング (Designer)] を選択します。
ステップ2: テンプレートからパイプラインを作成する
ビジュアルモデリング (Designer) ページで、[プリセットテンプレート] タブをクリックします。
Financial Risk Management テンプレートを見つけ、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、パラメーターを確認します。[データストレージ] パラメーターは、パイプラインがランタイム中に一時データおよびモデルを格納する Object Storage Service (OSS) バケットパスを設定します。このチュートリアルでは、デフォルト値で問題ありません。
[OK] をクリックします。パイプラインの作成には約 10 秒かかります。
[パイプライン] タブで、[Financial Risk Management] パイプラインをダブルクリックして、キャンバス上で開きます。
キャンバスには、3つのセクションを持つパイプラインが表示されます。 ![]()
| セクション | コンポーネント | 目的 |
|---|---|---|
| ① | Maximum Connected Subgraph → SQL Script → JOIN | 人々を2つのグループに分類し、各グループにIDを割り当てます。その後、相互リンクされた人々が最も多いセットを見つけることによって、無関係な人々を削除します。 |
| ② | Single-Source Shortest Path | Enochが目的の人々に到達するために連絡する必要がある人数を計算します。出力の distance フィールドには、この値が記録されます。 |
| ③ | Data Source → Label Propagation Classification → SQL Script | ラベル付けされたデータ (ここで weight = 詐欺確率) をインポートし、既知の詐欺師からネットワーク全体に詐欺ラベルを隣接する頂点に伝播し、結果をフィルタリングして各人の詐欺確率を表示します。 |
ステップ3: パイプラインを実行し、結果を表示する
キャンバスの左上隅で、
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。実行が完了したら、キャンバス上の [SQL] を右クリックし、[データの表示]を選択します。
出力テーブルには、各人が詐欺師である確率が表示されます。
グラフアルゴリズムがルールベースシステムが見逃す詐欺を検出する理由
次の図は、関係性グラフの例を示しています。矢印は、同僚や親族などの関係性を表します。このグラフでは、Enochは信頼できる顧客であり、Evanは詐欺師です。 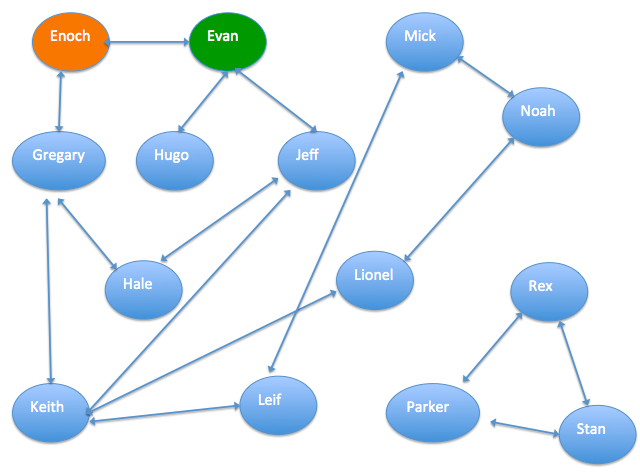
Machine Learning Platform for AI (PAI) は、K-Core、Maximum Connected Subgraph、Label Propagation Classification など、相関分析のためのいくつかのグラフアルゴリズムコンポーネントを提供します。これらのコンポーネントは、関係性構造を分析して、個人レベルのモデルが見逃すリスクシグナルを表面化させます。
ラベル伝播の仕組み: Label Propagation Classification は半教師あり分類アルゴリズムです。関係性グラフとラベル付けされたデータを入力として使用し、ラベル付けされた頂点のラベルに基づいて、ラベル付けされていない頂点のラベルを予測します。ラベル伝播は、各頂点のラベルをそれに隣接する頂点に伝播します。