Responsible AI ツールボックスを Platform for AI (PAI) の Data Science Workshop (DSW) インスタンスに統合し、AI モデルの公平性分析を実行します。この例では、FairnessDashboard を使用して、性別と人種間での収入予測のバイアスを評価します。
仕組み
公平性分析は、AI システムにおけるバイアスを特定および軽減し、すべてのユーザーに対して公平な結果を保証します。主要な原則は次のとおりです。
-
バイアスの回避:データとアルゴリズムのバイアスを減らし、AI システムが性別、人種、年齢に基づいて不公平な決定を下さないようにします。
-
代表的なデータ:モデルがマイノリティを含むすべてのユーザーグループに対応できるように、代表的なデータセットで訓練します。
-
透明性と解釈可能性:ユーザーと意思決定者がモデルがどのようにして出力を導き出すかを理解できるように、説明可能な AI (XAI) 技術を適用します。
-
継続的なモニタリングと評価:AI システムを定期的に監視し、時間とともに現れるバイアスを検出して修正します。
-
多様性と包括性:AI システムの設計と開発を通じて、多様なチームを構築し、複数の視点を考慮します。
-
コンプライアンスと倫理原則:適用される法律、規制、倫理基準に従い、危害や不正を防止します。
次の例では、PAI DSW の Responsible AI ツールボックスを使用して、収入予測モデルが性別や人種のグループを公平に扱っているかどうかを評価します。
前提条件
-
次の設定の DSW インスタンス。作成方法については、「DSW インスタンスの作成」をご参照ください。
-
インスタンスタイプ:ecs.gn6v-c8g1.2xlarge (推奨)
-
ランタイムイメージ:Python 3.9 以降。この例では、tensorflow-pytorch-develop:2.14-pytorch2.1-gpu-py311-cu118-ubuntu22.04 を使用します。
-
モデル:Responsible AI ツールボックスは、Sklearn、PyTorch、TensorFlow の回帰モデルと二項分類モデルをサポートしています。
-
-
訓練データセット。サンプルデータセットを使用するには、「ステップ 3:データセットの準備」をご参照ください。
-
アルゴリズムモデル。サンプルモデルを使用するには、「ステップ 5:モデルの訓練」をご参照ください。
ステップ 1:DSW Gallery を開く
-
PAI コンソールにログインします。
-
左上で、リージョンを選択します。
-
左側のナビゲーションペインで、QuickStart > [Notebook Gallery] を選択します。「Responsible AI-Fairness Analysis」を検索し、カードの Open in DSW をクリックします。
-
DSW インスタンスを選択し、Open Notebook をクリックします。「Responsible AI-Fairness Analysis」ノートブックが開きます。
ステップ 2:依存関係のインポート
Responsible AI ツールボックスに必要な raiwidgets パッケージをインストールします。
!pip install raiwidgets==0.34.1ステップ 3:データセットの準備
この例では、OpenML 1590 データセットをロードします。
from raiutils.common.retries import retry_function
from sklearn.datasets import fetch_openml
class FetchOpenml:
def __init__(self):
pass
# data_id = 1590 の OpenML データセットを取得します。
def fetch(self):
return fetch_openml(data_id=1590, as_frame=True)
fetcher = FetchOpenml()
action_name = "Dataset download"
err_msg = "Failed to download openml dataset"
max_retries = 5
retry_delay = 60
data = retry_function(fetcher.fetch, action_name, err_msg,
max_retries=max_retries,
retry_delay=retry_delay)代わりに独自の CSV データセットをロードするには、次のようにします。
import pandas as pd
# 独自のデータセットを CSV 形式でロードします。
# pandas を使用して CSV ファイルを読み込みます。
data = pd.read_csv(filename)ステップ 4:データの前処理
特徴量と目的変数の取得
目的変数は、モデルが予測する結果です。特徴量は、インスタンスごとの、目的変数以外のすべての変数です。この例では、目的変数は "class" で、関連する特徴量には "sex"、"race"、"age" が含まれます。
-
class:年間収入が 50K を超えるかどうか。
-
sex:性別。
-
race:人種。
-
age:年齢。
データを X_raw に読み込み、プレビューします:
# 目的変数を含まない特徴量を取得します。
X_raw = data.data
# 目的変数を含まない特徴量の最初の 5 行を表示します。
X_raw.head(5)目的変数を設定します。"1" は収入が 50K 超、"0" は収入が 50K 以下を示します。
from sklearn.preprocessing import LabelEncoder
# 目的変数を二項分類のターゲットに変換します。
# data.target は目的変数 "class" です。
y_true = (data.target == '>50K') * 1
y_true = LabelEncoder().fit_transform(y_true)
import matplotlib.pyplot as plt
import numpy as np
# 目的変数の分布を表示します。
counts = np.bincount(y_true)
classes = ['<=50K', '>50K']
plt.bar(classes, counts)センシティブな特徴量の取得
性別 (sex) と人種 (race) をセンシティブな特徴量として設定します。Responsible AI ツールボックスは、モデルがこれらの特徴量に対してバイアスを示しているかどうかを評価します。必要に応じて、独自のセンシティブな特徴量を設定してください。
# "sex" と "race" をセンシティブな情報として定義します。
# まず、データセットからセンシティブな情報に関連する列を選択し、新しい DataFrame `sensitive_features` を作成します。
sensitive_features = X_raw[['sex','race']]
sensitive_features.head(5)X_raw から機密性の高い特徴量を削除します。
# 特徴量からセンシティブな特徴量を削除します。
X = X_raw.drop(labels=['sex', 'race'],axis = 1)
X.head(5)特徴量エンコーディングと標準化
Responsible AI ツールボックスで使用するためにデータを標準化します。
import pandas as pd
from sklearn.preprocessing import StandardScaler
# ワンホットエンコードします。
X = pd.get_dummies(X)
# データセット X の特徴量を標準化 (スケーリング) します。
sc = StandardScaler()
X_scaled = sc.fit_transform(X)
X_scaled = pd.DataFrame(X_scaled, columns=X.columns)
X_scaled.head(5)訓練データとテストデータの分割
データの 20% をテストセットに分割します。残りは訓練に使用されます。
from sklearn.model_selection import train_test_split
# `test_size` の比率に従って、特徴量 X と目的変数 y を訓練セットとテストセットに分割します。
X_train, X_test, y_train, y_test = \
train_test_split(X_scaled, y_true, test_size=0.2, random_state=0, stratify=y_true)
# 上記の分割と一貫させるため、同じランダムシードでセンシティブな特徴量も分割します。
sensitive_features_train, sensitive_features_test = \
train_test_split(sensitive_features, test_size=0.2, random_state=0, stratify=y_true)訓練セットとテストセットのサイズを表示します。
print("訓練データセットのサイズ:", len(X_train))
print("テストデータセットのサイズ:", len(X_test))両方のセットのインデックスをリセットします。
# インデックスエラーを防ぐために DataFrame のインデックスをリセットします。
X_train = X_train.reset_index(drop=True)
sensitive_features_train = sensitive_features_train.reset_index(drop=True)
X_test = X_test.reset_index(drop=True)
sensitive_features_test = sensitive_features_test.reset_index(drop=True)ステップ 5:モデルの訓練
訓練データを使用してロジスティック回帰モデルを訓練します。タブには、Sklearn、PyTorch、および TensorFlow の実装が表示されます。
Sklearn
from sklearn.linear_model import LogisticRegression
# ロジスティック回帰モデルを作成します。
sk_model = LogisticRegression(solver='liblinear', fit_intercept=True)
# モデルを訓練します。
sk_model.fit(X_train, y_train)PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
# ロジスティック回帰モデルを定義します。
class LogisticRegression(nn.Module):
def __init__(self, input_size):
super(LogisticRegression, self).__init__()
self.linear = nn.Linear(input_size, 1)
def forward(self, x):
outputs = torch.sigmoid(self.linear(x))
return outputs
# モデルをインスタンス化します。
input_size = X_train.shape[1]
pt_model = LogisticRegression(input_size)
# 損失関数とオプティマイザ。
criterion = nn.BCELoss()
optimizer = optim.SGD(pt_model.parameters(), lr=5e-5)
# モデルを訓練します。
num_epochs = 1
X_train_pt = X_train
y_train_pt = y_train
for epoch in range(num_epochs):
# 順伝播。
# DataFrame を Tensor に変換します。
if isinstance(X_train_pt, pd.DataFrame):
X_train_pt = torch.tensor(X_train_pt.values)
X_train_pt = X_train_pt.float()
outputs = pt_model(X_train_pt)
outputs = outputs.squeeze()
# ndarray を Tensor に変換します。
if isinstance(y_train_pt, np.ndarray):
y_train_pt = torch.from_numpy(y_train_pt)
y_train_pt = y_train_pt.float()
loss = criterion(outputs, y_train_pt)
# 逆伝播と最適化。
optimizer.zero_grad()
loss.backward()
optimizer.step()TensorFlow
import tensorflow as tf
from tensorflow.keras import layers
# ロジスティック回帰モデルを定義します。
tf_model = tf.keras.Sequential([
layers.Dense(units=1, input_shape=(X_train.shape[-1],), activation='sigmoid')
])
# モデルをコンパイルします。 バイナリクロスエントロピー損失と確率的勾配降下法オプティマイザを使用します。
tf_model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
# モデルを訓練します。
tf_model.fit(X_train, y_train, epochs=1, batch_size=32, verbose=0)ステップ 6:モデルの評価
FairnessDashboard をインポートして、テストデータセットから公平性評価レポートを生成します。
FairnessDashboard は、予測結果と真の結果をセンシティブな変数でグループ化し、グループ間の予測パフォーマンスを比較します。
"sex" 特徴量については、"Male" と "Female" の選択率や適合率などのメトリックを計算して比較します。
次のいずれかのフレームワークを使用してモデルを評価します。
Sklearn
from raiwidgets import FairnessDashboard
import os
from urllib.parse import urlparse
# テストデータセットで予測を生成します
y_pred_sk = sk_model.predict(X_test)
# Responsible AI ツールボックスを使用して、各センシティブなグループの公平性メトリックを計算します
metric_frame_sk = FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_sk, locale='en')
# リダイレクト用の URL を設定します
metric_frame_sk.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_sk.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_sk.config['baseUrl'])PyTorch
from raiwidgets import FairnessDashboard
import torch
import os
from urllib.parse import urlparse
# モデルをテストし、公平性を評価します
pt_model.eval() # モデルを評価モードに設定します
X_test_pt = X_test
with torch.no_grad():
X_test_pt = torch.tensor(X_test_pt.values)
X_test_pt = X_test_pt.float()
y_pred_pt = pt_model(X_test_pt).numpy()
# Responsible AI ツールボックスを使用して、各センシティブなグループのメトリックを計算します
metric_frame_pt = FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_pt.flatten().round(),locale='en')
# URL リダイレクトリンクを設定します
metric_frame_pt.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_pt.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_pt.config['baseUrl'])TensorFlow
from raiwidgets import FairnessDashboard
import os
from urllib.parse import urlparse
# モデルをテストし、公平性を評価します。
y_pred_tf = tf_model.predict(X_test).flatten()
# Responsible AI ツールボックスを使用して、各センシティブなグループのデータ情報を計算します。
metric_frame_tf = FairnessDashboard(
sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_tf.round(),locale='en')
# URL リダイレクトリンクを設定します。
metric_frame_tf.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_tf.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_tf.config['baseUrl'])主要なパラメーター:
-
sensitive_features:センシティブな特徴量。
-
y_true:正解ラベル。
-
y_pred:モデルの予測結果。
-
locale (オプション) :パネルの表示言語。簡体字中国語 ("zh-Hans") と繁体字中国語 ("zh-Hant") をサポートしています。デフォルトは英語 ("en") です。
ステップ 7:評価レポートの表示
評価が完了したら、URL をクリックしてレポートを表示します。

[Fairness dashboard] ページで、[Get started] をクリックします。センシティブな特徴量、パフォーマンスメトリック、公平性メトリックを選択して、グループ間の結果を比較します。
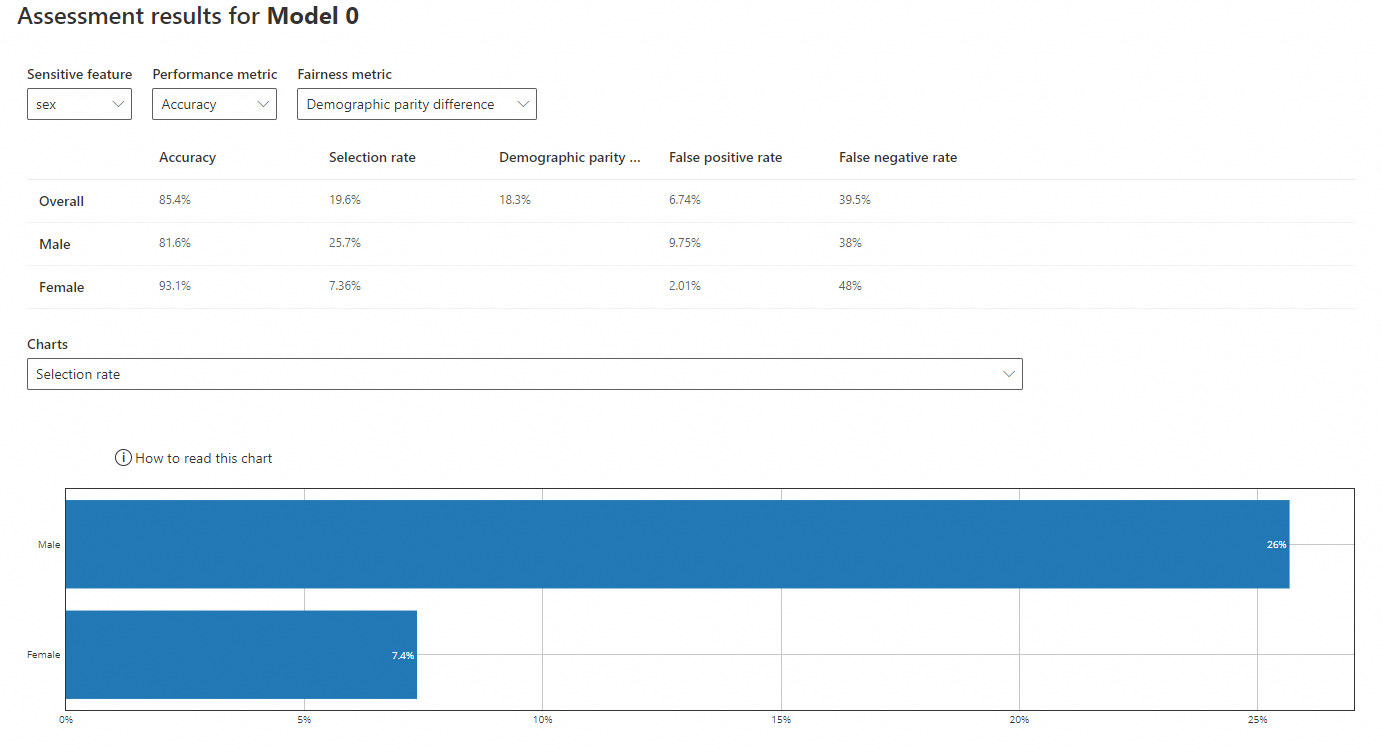
センシティブな特徴量が "sex" の場合
-
センシティブな特徴量:
sex -
パフォーマンスメトリック:
Accuracy -
公平性メトリック:
Demographic parity difference
-
正解率:正しい予測の総サンプルに対する比率。モデルの正解率は、男性 (81.6%) が女性 (93.1%) よりも低いですが、どちらも全体的な正解率 (85.4%) に近いです。
-
選択率:モデルが収入 > 50K と予測する確率。男性の選択率 (25.7%) は女性 (7.36%) よりも高く、女性の選択率は全体のレート (19.6%) を大きく下回っています。
-
人口統計学的パリティ差:保護されたグループ間の陽性予測確率の差。0 に近い値ほどバイアスが少ないことを示します。全体の差は 18.3% です。
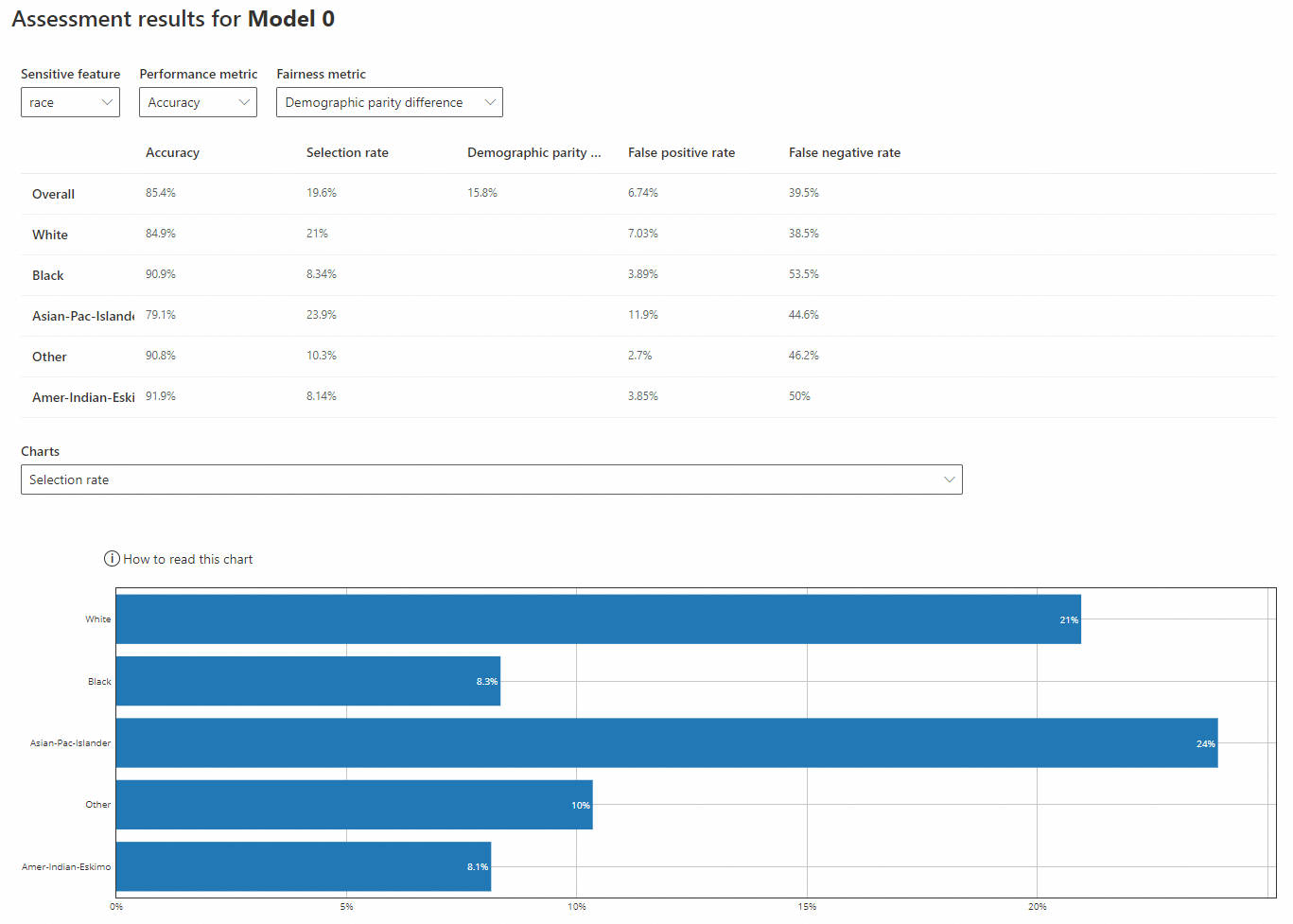
センシティブな特徴量が "race" の場合
-
センシティブな特徴量:
race -
パフォーマンスメトリック:
Accuracy -
公平性メトリック:
Demographic parity difference
-
正解率:正しい予測の総サンプルに対する比率。"White" (84.9%) と "Asian-Pac-Islander" (79.1%) の正解率は、"Black" (90.9%)、"Other" (90.8%)、"Amer-Indian-Eskimo" (91.9%) よりも低いですが、すべてのグループが全体的な正解率 (85.4%) に近いです。
-
選択率:モデルが収入 > 50K と予測する確率。"White" (21%) と "Asian-Pac-Islander" (23.9%) は、"Black" (8.34%)、"Other" (10.3%)、"Amer-Indian-Eskimo" (8.14%) よりも高いレートですが、後者のグループはすべて全体のレート (19.6%) を大きく下回っています。
-
人口統計学的パリティ差:保護されたグループ間の陽性予測確率の差。0 に近い値ほどバイアスが少ないことを示します。全体の差は 15.8% です。