はじめに
3月6日、Alibaba Cloud は Qwen ファミリーの推論モデルである QwQ-32B をオープンソース化しました。大規模な強化学習に基づき、数学、コーディング、および汎用能力において画期的な向上を実現しています。その全体的なパフォーマンスは DeepSeek-R1 に匹敵し、デプロイコストを大幅に削減します。
数学の AIME24 ベンチマークおよびコーディングの LiveCodeBench において、QwQ-32B は DeepSeek-R1 と同等の性能を発揮し、同程度のサイズの o1-mini および R1-distilled モデルを大幅に上回ります。
Meta のチーフサイエンティストである Yann LeCun 氏が主導する「最も困難な LLM 評価リーダーボード」である LiveBench、指示追従のための IFEval (Google などが提案)、および関数呼び出しの精度を測る BFCL テスト (UC Berkeley などが提案) において、QwQ-32B は DeepSeek-R1 を上回るスコアを記録しています。
QwQ-32B はエージェント機能を統合しており、ツールを使用しながら批判的に思考し、環境からのフィードバックに基づいて推論プロセスを調整することが可能です。
PAI-Model Gallery は、QwQ-32B のワンクリックデプロイ、ファインチューニング、評価を完全にサポートしており、デプロイには 96 GB の GPU メモリを搭載した GPU が必要です。QwQ-32B-GGUF や QwQ-32B-AWQ などの量子化バージョンもサポートされており、単一の A10 カードなどの低コスト GPU にデプロイできます。
モデルのデプロイ
PAI-Model Gallery ページに移動します。
PAI コンソールにログインし、左上でリージョンを選択します。リージョンを切り替えて、利用可能なコンピューティングリソースを見つけることができます。
左側のナビゲーションペインで Workspaces を選択し、ワークスペース名をクリックしてワークスペースに移動します。
左側のナビゲーションペインで、QuickStart > [Model Gallery] を選択します。
PAI-Model Gallery ページで QwQ-32B モデルカードを見つけてクリックし、モデル詳細ページを開きます。
右上の [Deploy] をクリックします。デプロイフレームワークを選択し、推論サービスの名前を設定し、デプロイ用のリソースを指定します。これにより、モデルは Elastic Algorithm Service (EAS) にデプロイされます。プラットフォームは、SGLang、vLLM、および BladeLLM (PAI が開発した高性能推論フレームワーク) など、さまざまなデプロイフレームワークをサポートしています。
デプロイ方法として、[Single-Node - Standard Instance] または [Single-Node - GP7V Instance] を選択できます。サービス作成では、[New Service] または [Update Existing Service] を選択し、そのグループとタグを設定できます。サポートされているリソースタイプには、[Public Resources]、[EAS Resource Group]、および [Resource Quota] があります。
推論サービスの使用:デプロイが成功したら、サービスページに移動し、[View Call Information] をクリックしてエンドポイントとトークンを取得します。サービスの呼び出し方法については、事前学習済みモデルのリンクをクリックしてモデル詳細ページに戻り、手順を確認してください。
サービス作成中に、[Status] フィールドの横にある [View Deployment Events] をクリックして、デプロイの進行状況をモニタリングできます。ステータスメッセージには
Waiting task server to be readyと表示されます。また、デプロイされた QwQ-32B モデルサービスは、EAS でオンラインデバッグすることもできます。
[Online Debugging] ページで、[Chat] タブを選択します。HTTP メソッドは POST で、リクエストパスは
/api/predict/quickstart_qwq32b/v1/chat/completionsです。Body の JSON 例では、modelはQwQ-32Bに設定され、messagesにはrole: userとcontent: Please introduce yourselfが含まれ、max_tokensは1024に設定されています。[Send Request] をクリックすると、ステータスコード 200 が返り、レスポンスボディにはchat.completionタイプの推論結果と、アシスタントロールのコンテンツ内に<think>タグで囲まれた思考プロセスが含まれます。
モデルのファインチューニング
PAI-Model Gallery は、QwQ-32B 用の教師ありファインチューニング (SFT) アルゴリズムを提供します。LoRA ファインチューニングとフルパラメータファインチューニングの両方をサポートしているため、すぐにモデルをファインチューニングできます。
トレーニングデータの準備:SFT アルゴリズムは、JSONL などの形式のトレーニングデータセットをサポートしています。フォーマット要件の詳細については、モデルのドキュメントをご参照ください。以下は、JSONL 形式のトレーニングデータセットの例です。
{"messages": [{"role": "system", "content": "You are a helpful and harmless assistant."}, {"role": "user", "content": "Who are you?"}, {"role": "assistant", "content": "私はPAIによってトレーニングされたAIアシスタントの「パイ」です。私の目標は、ユーザーに役立つ正確でタイムリーな情報を提供し、さまざまな方法で効果的にコミュニケーションできるよう支援することです。何かお手伝いできることはありますか?"}]} {"messages": [{"role": "system", "content": "You are a helpful and harmless assistant."}, {"role": "user", "content": "Who are you!"}, {"role": "assistant", "content": "こんにちは! 私はPAIによって開発されたAI言語モデルの「パイ」です。ご質問への回答、情報提供、会話、問題解決のお手伝いができます。ご質問やサポートが必要な場合は、お気軽にお知らせください!"}]}トレーニングパラメータの設定:データを準備した後、Object Storage Service (OSS) のバケットにアップロードします。32B モデルはサイズが大きいため、アルゴリズムには少なくとも 96 GB の GPU メモリを搭載した GPU リソースが必要です。リソースクォータに十分なコンピューティングリソースがあることを確認してください。
アルゴリズムは以下のハイパーパラメータをサポートしています。データセットやコンピューティングリソースに応じて調整するか、デフォルト値を使用できます。
パラメータ
説明
詳細情報
learning_rate
学習率。モデルの重み調整の大きさを制御します。
学習率が高すぎるとトレーニングが不安定になり、損失値が激しく変動して収束しなくなります。低すぎると損失の減少が遅くなり、収束に時間がかかります。適切な学習率を設定することで、モデルは迅速かつ安定して最適解に収束します。
num_train_epochs
トレーニングデータセットを走査する回数。
エポック数が少なすぎるとアンダーフィッティング、多すぎるとオーバーフィッティングを引き起こすことがあります。サンプルサイズが小さい場合は、エポック数を増やしてアンダーフィッティングを回避できます。通常、学習率が小さいほど多くのエポック数が必要になります。
per_device_train_batch_size
1 回のトレーニングイテレーションで各 GPU が処理するサンプル数。
バッチサイズを大きくするとトレーニング速度は向上しますが、GPU メモリの使用量も増加します。理想的なバッチサイズは、通常、GPU メモリのオーバーフローを引き起こさない最大値です。GPU メモリの使用状況は、トレーニング詳細のタスクモニタリングページで確認できます。
gradient_accumulation_steps
勾配蓄積のステップ数。
バッチサイズが小さいと、勾配推定の分散が大きくなり、収束速度に影響します。勾配蓄積により、指定されたバッチ数から勾配を蓄積した後にモデルが重みを更新できます。
gradient_accumulation_stepsが GPU 数の倍数であることを確認してください。max_length
1 回のトレーニングステップでモデルが処理する入力データの最大トークン長。
トークナイザがトレーニングデータを処理してトークンシーケンスを生成します。トークン推定ツールを使用して、トレーニングデータ内のテキスト長を推定できます。
lora_rank
LoRA の次元。
lora_alpha
LoRA の重み。
LoRA のスケーリング係数で、通常は
lora_rank * 2に設定されます。lora_dropout
LoRA トレーニングのドロップアウト率。トレーニング中にニューロンをランダムに無効化することで、オーバーフィッティングを防ぎます。
lorap_lr_ratio
LoRA+ の学習率比 (λ = ηB/ηA)。ここで、ηA と ηB はそれぞれアダプタ行列 A と B の学習率です。
LoRA と比較して、LoRA+ はプロセスの主要部分に異なる学習率を使用することで、計算要件を増やすことなく、より良いパフォーマンスと高速なファインチューニングを実現できます。
lorap_lr_ratioを 0 に設定すると、トレーニングでは LoRA+ ではなく標準の LoRA が使用されます。advanced_settings
上記のパラメータに加えて、このフィールドで
--key1 value1 --key2 value2形式を使用して他のパラメータをカスタマイズできます。不要な場合は、このフィールドを空白のままにします。save_strategy:モデルチェックポイントの保存戦略。 オプションはsteps、epoch、noです。 デフォルトはstepsです。save_steps:モデルの保存間隔。 デフォルトは 500 です。save_total_limit:保存するチェックポイントの最大数。システムは、この制限内に収まるように古いチェックポイントを削除します。 デフォルトは 2 です。Noneの場合、システムはすべてのチェックポイントを保存します。warmup_ratio:学習率ウォームアップフェーズを制御するハイパーパラメータ。この初期フェーズでは、学習率は小さな値から初期設定値まで徐々に増加します。warmup_ratioは、トレーニングプロセス全体におけるこのフェーズの割合を決定します。 デフォルトは 0 です。
[Train] ボタンをクリックしてトレーニングを開始します。トレーニングジョブのステータスとログを表示できます。また、ファインチューニングされたモデルをオンラインサービスとしてデプロイすることもできます。
モデルの評価
PAI-Model Gallery には評価アルゴリズムが組み込まれており、事前学習済みモデルとファインチューニング済みモデルをすぐに評価できます。評価はモデルのパフォーマンスを査定するのに役立ち、また、ユースケースに最も適したモデルの選択に役立つサイドバイサイド比較もサポートします。
モデル評価は 2 つの場所から開始できます。
事前学習済みモデルを直接評価する | PAI-Model Gallery のモデル詳細ページで、右上の [Evaluate] ボタンをクリックします。 |
トレーニングタスク詳細ページからファインチューニング済みモデルを評価する | 右上の [Evaluate] ボタンをクリックします。 |
モデル評価は、カスタムデータセットと公開データセットの両方をサポートしています。
[New Evaluation Task] ページで、ページタイトルの横にある [Switch to professional mode] をクリックしてプロフェッショナルモードに入ります。このモードでは、ジャッジモデル評価などの高度な機能がサポートされています。フォームで、[Task Name]、[Model]、[Output Path]、[Dataset Source]、[Resource Type]、[Resource Group Type]、[Resource Configuration Method]、[Task Resources]、[VPC Configuration]、および [Internet gateway] パラメータを設定します。
カスタムデータセットの評価
モデル評価は、BLEU や ROUGE などの一般的な NLP テキストマッチングメトリクス、およびジャッジモデル評価をサポートしています。この機能は [professional mode] でのみ利用可能で、ジャッジ LLM を使用して別の LLM を評価し、スコアと理由を提供します。シナリオ固有のデータを使用して、選択したモデルが適切かどうかを判断できます。
評価には JSONL 形式の評価セットファイルが必要です。各行は JSON オブジェクトです。質問列は
questionで、回答列はanswerで識別します。ファイル例:evaluation_test.jsonl。公開データセットの評価
ドメイン別にグループ化されたオープンソースの評価データセットを使用して、大規模モデルの包括的な評価を提供します。PAI は現在、CMMLU、GSM8K、TriviaQA、MMLU、C-Eval、TruthfulQA、および HellaSwag などのデータセットを管理しており、数学、知識、推論など複数のドメインをカバーしています。より多くの公開データセットが定期的に追加されます。注:GSM8K、TriviaQA、HellaSwag データセットでの評価には時間がかかります。必要な場合にのみ選択してください。
次に、評価結果の出力パスを選択し、推奨されるコンピューティングリソースを選択して、評価タスクを送信します。タスクが完了したら、タスクページで評価結果を表示します。複数のデータセットを選択した場合、モデルはそれらの評価を順次実行するため、待機時間が増加する可能性があります。ログでタスクの進捗状況を確認できます。
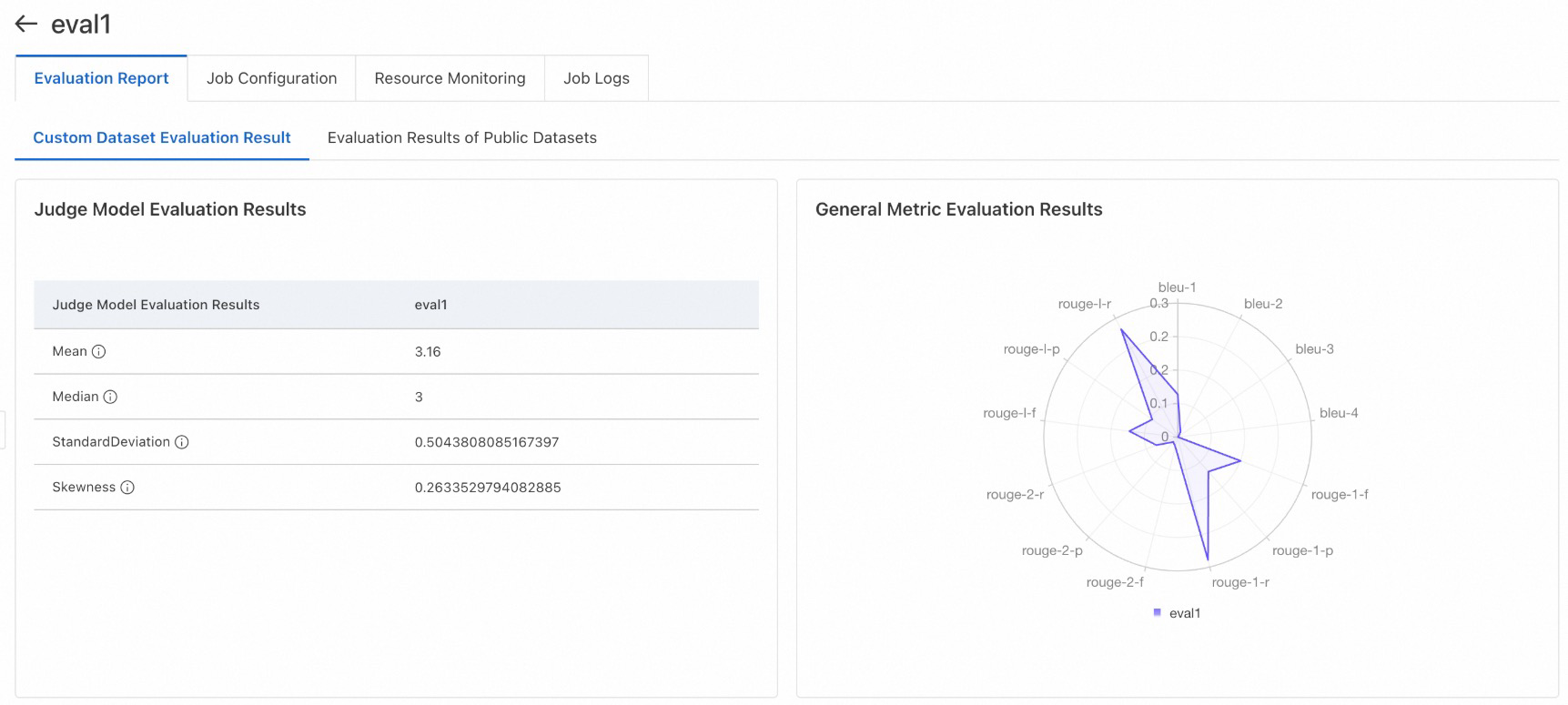
評価レポートの表示:以下の画像は、カスタムデータセットと公開データセットの評価結果の例です。

お問い合わせ
PAI-Model Gallery をぜひフォローしてご活用ください。プラットフォームは、継続的に SOTA モデルで更新されます。モデルに関するご要望がございましたら、お気軽にお問い合わせください。DingTalk グループ 番号 79680024618 を検索して、PAI-Model Gallery ユーザーコミュニティに参加できます。