大規模視覚モデル (LVM) の画像処理アルゴリズムは、画像クリーニング、コンテンツフィルタリング、情報抽出、キャプション生成などの機能を提供します。これらのアルゴリズムを組み合わせることで、画像データをフィルタリングし、テキスト記述を生成できます。これにより、画像生成モデルのトレーニング用の高品質なデータを準備できます。このトピックでは、可視化モデリング (Designer) で画像・テキストフィルタリングのプリセットテンプレートを使用する方法について説明します。
制限事項
画像・テキストフィルタリングのプリセットテンプレートは、中国 (杭州)、中国 (上海)、中国 (北京)、および中国 (深セン) リージョンでのみ利用可能です。
画像データの準備
PAI は、すぐに利用開始できるようサンプルデータを提供しています。
-
画像メタデータファイルと画像ファイルをダウンロードします。
-
画像メタデータファイル: image_meta.jsonl。画像・テキストアルゴリズムの入力として使用されます。
-
画像ファイル: data.zip。一般的な画像処理アルゴリズムの入力として使用されます。
-
-
data.zip ファイルを解凍し、画像を OSS にアップロードします。詳細については、「シンプルアップロード」をご参照ください。
-
画像メタデータファイルを変更します。
画像メタデータファイルで、
oss://bucket_name.oss-cn-hangzhou.aliyuncs.com/image_algorithm_test/image_data/を、画像をアップロードした OSS バケットディレクトリに置き換えます。
-
変更した画像メタデータファイルを、ステップ 2 で使用した OSS バケットにアップロードします。詳細については、「シンプルアップロード」をご参照ください。
ワークフローの作成と実行
-
Designer ページに移動します。
-
PAI コンソールにログインします。
-
左上隅で、目的のリージョンを選択します。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。[ワークスペース] ページで、ご利用のワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、Model Training > Visualized Modeling (Designer) を選択して Designer ページを開きます。
-
-
ワークフローを作成します。
-
Preset Templates タブで、[ビジネス分野] > [マルチモーダル LLM] を選択し、[画像・テキストフィルタリング] テンプレートカードの Create をクリックします。

-
ワークフローパラメーターを設定 (またはデフォルト設定を維持) し、Confirm をクリックします。
-
ワークフローリストで、作成したワークフローを選択し、Open をクリックします。
-
-
ワークフローを設定します。
-
[OSS データの読み込み] コンポーネントの設定: [OSS データの読み込み] コンポーネントをクリックします。右側のペインの [フィールド設定] タブで、[OSS データパス] を画像データファイルを含む OSS バケットディレクトリに設定します。
-
LLMDataProcessGroup1 グループの設定: 設定アイコン
 をクリックし、[データ出力 OSS ディレクトリ] を設定します。このディレクトリには、後続のワークフロー実行による結果ファイルが保存されます。LVM 画像前処理アルゴリズムコンポーネントの詳細については、「画像前処理オペレーター」をご参照ください。
をクリックし、[データ出力 OSS ディレクトリ] を設定します。このディレクトリには、後続のワークフロー実行による結果ファイルが保存されます。LVM 画像前処理アルゴリズムコンポーネントの詳細については、「画像前処理オペレーター」をご参照ください。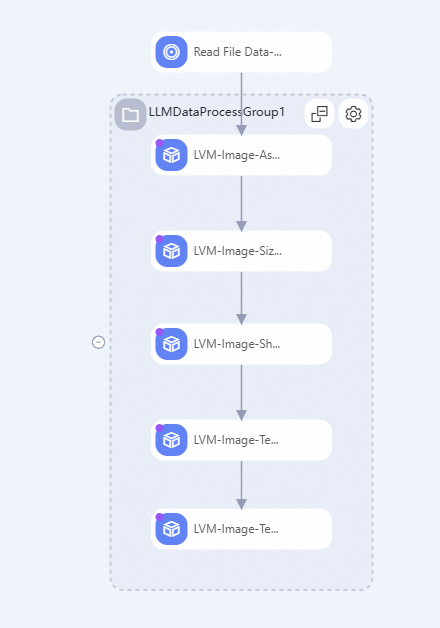
-
-
ワークフローを実行します。実行が完了したら、生成されたファイルを表示します:
-
meta.jsonl ファイル: 実行中、ワークフローは [画像データの OSS パス] に指定されたパスの親ディレクトリに、meta.jsonl という名前の画像メタデータファイルを生成します。
-
結果ファイル: このファイルは、[出力ファイルの OSS パス] に指定されたディレクトリで表示します。
結果ファイルの詳細については、「画像前処理オペレーター」の [出力ファイルの OSS パス] パラメーターの説明をご参照ください。
-