LLM データ処理アルゴリズムを使用すると、データを編集・変換したり、低品質なサンプルをフィルターしたり、重複サンプルを削除したりできます。要件に基づいてアルゴリズムを組み合わせることで、適切なデータをフィルターし、ニーズに合ったテキストを生成でき、後続の LLM トレーニング用の高品質なデータを生成できます。このトピックでは、PAI が提供する LLM データ処理コンポーネントを使用して、オープンソースの RedPajama Wikipedia データセットの小さなサブセットを用いて Wikipedia データをクリーニングおよび処理する方法を説明します。
データセット
Designer の LLM データ処理-Wikipedia (Web テキストデータ) プリセットテンプレートは、オープンソースの RedPajama プロジェクトの生データから抽出された 5,000 サンプルのデータセットを使用します。
ワークフローの作成と実行
-
Designer ページに移動します。
-
PAI コンソールにログインします。
-
左上隅でリージョンを選択します。
-
左側のナビゲーションウィンドウで、[Workspaces] をクリックし、使用するワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、Model Training > Visualized Modeling (Designer) を選択して Designer ページに移動します。
-
-
ワークフローを作成します。
-
Preset Templates タブで、[Business Area] > [LLM] を選択し、[LLM Data Processing-Wikipedia (web text data)] テンプレートカードの Create をクリックします。
-
ワークフローパラメーターを設定 (またはデフォルト設定を維持) し、Confirm をクリックします。
-
ワークフローリストで、作成したワークフローを選択し、Open をクリックします。
-
-
ワークフローの説明:

以下に、ワークフロー内の主要なアルゴリズムコンポーネントを説明します。
-
LLM-Sensitive Content Mask (MaxCompute)-1
"text" フィールド内の機密情報をマスクします。例:
-
メールアドレスの文字列を
[EMAIL]に置き換えます。 -
電話番号または携帯電話番号を
[TELEPHONE]または[MOBILEPHONE]に置き換えます。 -
ID カード番号を
IDNUMに置き換えます。
-
-
LLM-Clean Special Content (MaxCompute)-1
"text" フィールドから URL を削除します。
-
LLM-Text Normalizer (MaxCompute)-1
"text" フィールド内の Unicode 文字を正規化し、繁体字中国語を簡体字中国語に変換します。
-
LLM-Count Filter (MaxCompute)-1
指定された英数字の数または比率を満たさないサンプルを "text" フィールドから削除します。Wikipedia データセットのほとんどの文字は英数字であるため、このコンポーネントは一部のダーティデータを削除します。
-
LLM-Length Filter (MaxCompute)-1
"text" フィールドの平均行長に基づいてサンプルをフィルターします。平均長は、各サンプルのテキストを改行文字
\nで分割して計算されます。 -
LLM-N-Gram Repetition Filter (MaxCompute)-1
"text" フィールドの文字レベルの N-gram 繰り返し率に基づいてサンプルをフィルターします。このコンポーネントは、テキストに対して文字レベルでサイズ N のスライディングウィンドウを適用し、長さ N のセグメントのシーケンスを形成します。各セグメントはグラムです。すべてのグラムの出現回数をカウントし、フィルターの繰り返し率として
the total frequency of grams with a frequency greater than 1 / the total frequency of all gramsの比率を使用します。 -
LLM-Sensitive Words Filter (MaxCompute)-1
"text" フィールド内で、システムのプリセット禁止用語リストを使用して禁止用語を含むサンプルをフィルターします。
-
LLM-Language Recognition and Filter (MaxCompute)-1
"text" フィールドのテキストの信頼度スコアを計算し、設定された信頼度のしきい値に基づいてサンプルをフィルターします。
-
LLM-Length Filter (MaxCompute)-2
"text" フィールドの最大行長に基づいてサンプルをフィルターします。最大行長は、各サンプルのテキストを改行文字
\nで分割して計算されます。 -
LLM-Perplexity Filter (MaxCompute)-1
"text" フィールドのテキストのパープレキシティを計算し、指定されたパープレキシティのしきい値に基づいてサンプルをフィルターします。
-
LLM-Special Characters Ratio Filter (MaxCompute)-1
指定された特殊文字の比率を満たさないサンプルを "text" フィールドから削除します。
-
LLM-Length Filter (MaxCompute)-3
"text" フィールドの長さに基づいてサンプルをフィルターします。
-
LLM-Tokenization (MaxCompute)-1
"text" フィールドのテキストをトークン化し、結果を新しい列に保存します。
-
LLM-Length Filter (MaxCompute)-4
各サンプルのテキストをスペース (
" ") を区切り文字として単語のリストに分割し、単語数に基づいてサンプルをフィルターします。 -
LLM-N-Gram Repetition Filter (MaxCompute)-2
"text" フィールドの単語レベルの N-gram 繰り返し率に基づいてサンプルをフィルターします。このコンポーネントは、まずすべての単語を小文字に変換します。テキストに対して単語レベルでサイズ N のスライディングウィンドウを適用し、長さ N のセグメントのシーケンスを形成します。各セグメントはグラムです。すべてのグラムの出現回数をカウントし、フィルターの繰り返し率として
the total frequency of grams with a frequency greater than 1 / the total frequency of all gramsの比率を使用します。 -
LLM-MinHash Deduplicator (MaxCompute)-1
MinHash アルゴリズムに基づいて類似サンプルを削除します。
-
-
ワークフローを実行します。
実行が完了したら、[Write To Data Table-1] コンポーネントを右クリックし、View Data > Output を選択して処理済みのサンプルを表示します。
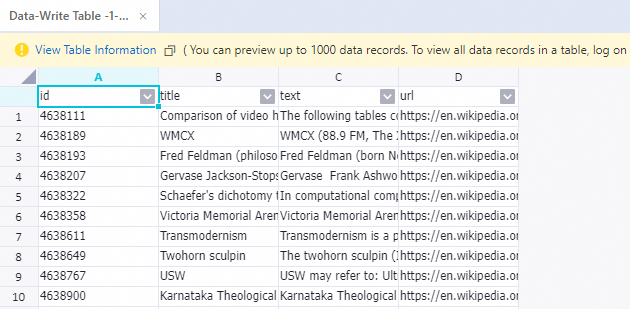
参考
-
LLM アルゴリズムコンポーネントの詳細については、「LLM データ処理 (MaxCompute)」をご参照ください。