LLM データ処理アルゴリズムコンポーネントを使用すると、データサンプルの編集と変換、低品質なサンプルのフィルタリング、重複の削除ができます。ビジネス要件に基づいてさまざまなコンポーネントを組み合わせることで、データをフィルタリングし、ニーズに合ったテキストを生成し、LLM トレーニングに高品質なデータを提供できます。このトピックでは、PAI が提供する LLM データ処理コンポーネントを使用して、オープンソースの Alpaca-CoT プロジェクトの少量のデータを用いて SFT データをクリーニングおよび処理する方法を説明します。
データセット
視覚化モデリング (Designer) の「LLM Data Processing-Alpaca-Cot (SFT Data)」プリセットテンプレートでは、オープンソースの Alpaca-CoT プロジェクトの生データから抽出した 5,000 サンプルのデータセットを使用します。
パイプラインの作成と実行
-
視覚化モデリング (Designer) ページに移動します。
-
PAI コンソールにログインします。
-
左上隅で、要件に基づいてリージョンを選択します。
-
左側のナビゲーションウィンドウで、[Workspaces] をクリックし、ご利用のワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、Model Training > Visualized Modeling (Designer) を選択します。
-
-
パイプラインを作成します。
-
Preset Templates タブで、[ビジネス領域] > [LLM] を選択し、[LLM Data Processing-Alpaca-Cot (SFT Data)] テンプレートカードの Create をクリックします。
-
パイプラインのパラメーターを設定するか、デフォルト設定のままにして、Confirm をクリックします。
-
パイプラインリストで、作成したパイプラインを見つけて Open をクリックします。
-
-
パイプラインの概要:

パイプラインの主要なアルゴリズムコンポーネント:
-
LLM-MD5 重複排除 (MaxCompute)-1
textフィールドのテキストのハッシュを計算し、重複するテキストを削除します。同じハッシュを持つテキストは 1 つのインスタンスのみ保持されます。 -
LLM-数フィルター (MaxCompute)-1
textフィールドから、指定された数値と文字の数または割合を満たさないサンプルを削除します。SFT データセットのほとんどの文字は英数字です。このコンポーネントは、一部のダーティデータの削除に役立ちます。 -
LLM-N-Gram 繰り返し率フィルター (MaxCompute)-1
textフィールドの文字レベルの n-gram 繰り返し率に基づいてサンプルをフィルタリングします。テキストはサイズ N のスライドウィンドウを使用して処理され、グラムと呼ばれる N 文字のフラグメントのシーケンスが作成されます。次に、コンポーネントは各グラムの出現回数をカウントします。サンプルは、次の式で計算される繰り返し率に基づいてフィルタリングされます:(複数回出現するグラムの総出現回数) / (すべてのグラムの総出現回数)。 -
LLM-禁止用語フィルター (MaxCompute)-1
システムが提供する禁止用語ファイルを使用して、
textフィールド内の禁止用語を含むサンプルをフィルタリングします。 -
LLM-長さフィルター (MaxCompute)-1
textフィールドの長さと最大行長に基づいてサンプルをフィルタリングします。最大行長は、サンプルを改行文字\nで分割することによって決定されます。 -
LLM-MinHash 類似度重複排除 (MaxCompute)-1
MinHash アルゴリズムを使用して類似サンプルを削除します。
-
-
パイプラインを実行します。
パイプラインの実行が完了したら、[テーブル書き込み-1] コンポーネントを右クリックし、View Data > Output を選択して、先行するコンポーネントによって処理されたサンプルを表示します。
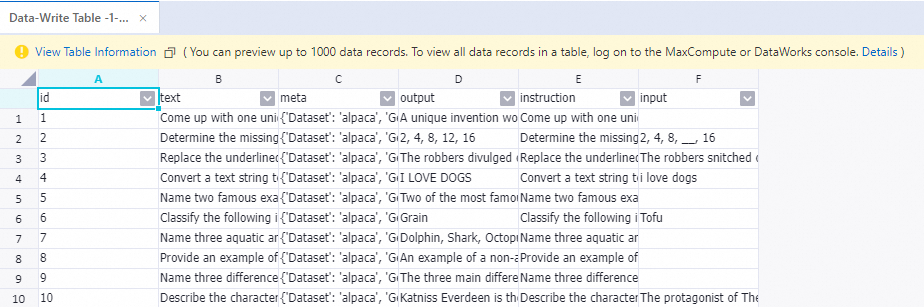
参考
-
LLM アルゴリズムコンポーネントの詳細については、「LLM データ処理 (MaxCompute)」をご参照ください。