CosyVoice 2 は、音声ファイルの管理と音声合成に使用できる API 操作を提供します。このトピックでは、これらの API 操作とその呼び出し方法について説明します。
事前準備
CosyVoice 2 の WebUI サービス、またはフロントエンドとバックエンドが分離されたパフォーマンス専有型サービスをデプロイします。また、アップロードされた音声ファイルを保存するために、Object Storage Service (OSS) または他のストレージサービスをマウントする必要があります。詳細については、「WebUI サービスのクイックデプロイ」または「フロントエンドとバックエンドが分離されたパフォーマンス専有型サービスのクイックデプロイ」をご参照ください。
サービスのエンドポイントとトークンを取得します。
重要フロントエンドとバックエンドが分離されたパフォーマンス専有型サービスの場合、API 呼び出しは Frontend サービス に送信します。
ストレステストには、VPC エンドポイントを使用します。これにより、パブリックエンドポイントよりも大幅に高い処理速度が得られます。
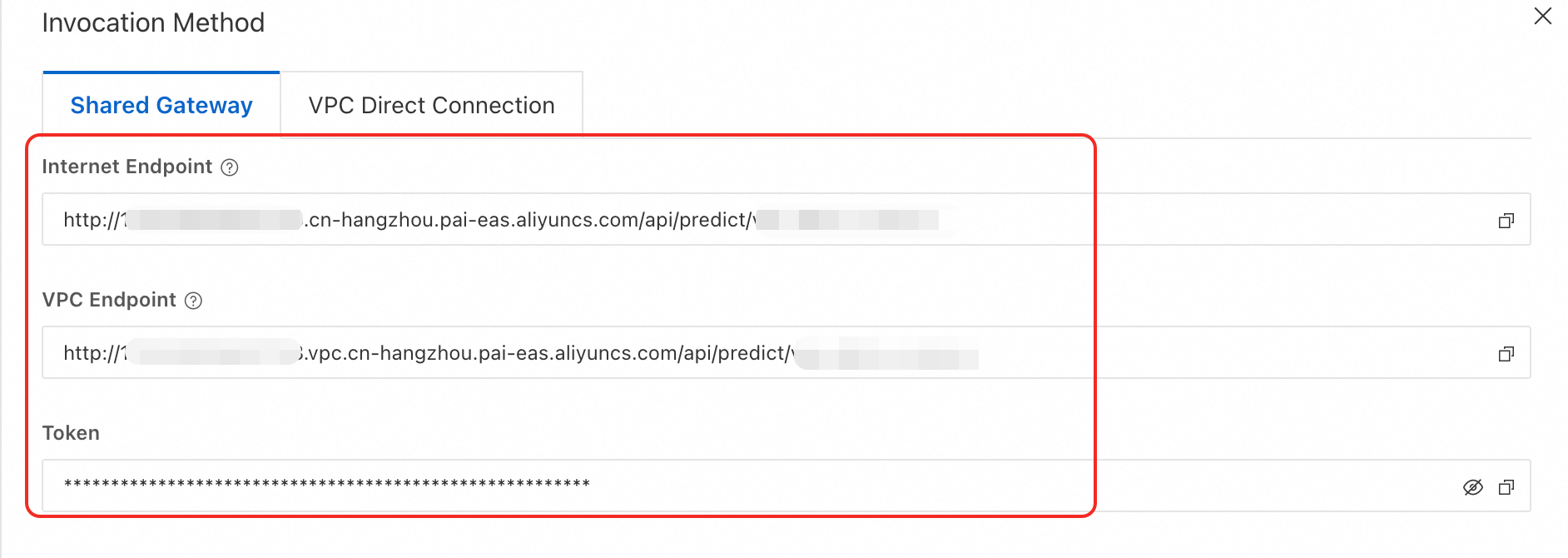
CosyVoice 2 の WebUI サービスまたは Frontend サービスの名前をクリックします。[概要] ページの [基本情報] セクションで、[呼び出し情報の表示] をクリックします。
[呼び出し情報] パネルの [共有ゲートウェイ] タブで、サービスのエンドポイント (EAS_SERVICE_URL) とトークン (EAS_TOKEN) を取得し、エンドポイントの末尾にある
/を削除します。説明パブリックエンドポイントを使用するには、クライアントがパブリックネットワークにアクセスできる必要があります。
VPC エンドポイントを使用するには、クライアントがサービスと同じ Virtual Private Cloud (VPC) 内にある必要があります。
音声ファイルを準備します。
このトピックでは、次のサンプル音声ファイルを使用します:
サンプル WAV 音声ファイル:zero_shot_prompt.wav
サンプル音声テキスト:
将来、あなたが私よりもさらにうまくできることを願っています。
API 操作
参照音声ファイルのアップロード
呼び出しメソッド
エンドポイント
<EAS_SERVICE_URL>/api/v1/audio/reference_audioリクエストメソッド
POST
リクエストヘッダー
Authorization: Bearer <EAS_TOKEN>リクエストパラメーター
file:必須。アップロードする音声ファイル。MP3、WAV、PCM 形式がサポートされています。タイプ:file。デフォルト値:None。
text:必須。音声ファイルに対応するテキストコンテンツ。タイプ:string。
レスポンスパラメーター
参照音声オブジェクトを返します。詳細については、「レスポンスパラメーターリスト」をご参照ください。
リクエスト例
cURL
# <EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。 curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/reference_audio \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --form 'file=@"/home/xxxx/zero_shot_prompt.wav"' \ --form 'text="I hope you can do even better than me in the future."'Python
import requests response = requests.post( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio", # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN> をサービストークンに置き換えます。 }, files={ "file": open("./zero_shot_prompt.wav", "rb"), }, data={ "text": "I hope you can do even better than me in the future." } ) print(response.text)レスポンス例
{ "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "I hope you can do even better than me in the future." }
参照音声ファイルリストの表示
呼び出しメソッド
エンドポイント
<EAS_SERVICE_URL>/api/v1/audio/reference_audio
リクエストメソッド
GET
リクエストヘッダー
Authorization: Bearer <EAS_TOKEN>リクエストパラメーター
limit:任意。返すファイルの最大数。タイプ:integer。デフォルト値:100。
order:任意。created_at タイムスタンプに基づくオブジェクトのソート順。タイプ:string。有効値:
asc:昇順
desc (デフォルト):降順
レスポンスパラメーター
参照音声オブジェクトの配列を返します。詳細については、「レスポンスパラメーターリスト」をご参照ください。
リクエスト例
cURL
# <EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。 curl -XGET <EAS_SERVICE_URL>/api/v1/audio/reference_audio?limit=10&order=desc \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.get( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio", # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN> をサービストークンに置き換えます。 } ) print(response.text)レスポンス例
[ { "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "I hope you can do even better than me in the future." } ]
特定の参照音声ファイルの表示
呼び出しメソッド
エンドポイント
<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>リクエストメソッド
GET
リクエストヘッダー
Authorization: Bearer <EAS_TOKEN>パスパラメーター
reference_audio_id:必須。参照音声ファイルの ID。ID を取得する方法については、「参照音声ファイルリストの表示」をご参照ください。タイプ:String。デフォルト値:None。
レスポンスパラメーター
参照音声オブジェクトを返します。詳細については、「レスポンスパラメーターリスト」をご参照ください。
リクエスト例
cURL
# <EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。 # <reference_audio_id> を参照音声 ID に置き換えます。 curl -XGET <EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id> \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.get( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>", # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN> をサービストークンに置き換えます。 } ) print(response.text)レスポンス例
{ "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "I hope you can do even better than me in the future." }
参照音声ファイルの削除
呼び出しメソッド
エンドポイント
<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>リクエストメソッド
DELETE
リクエストヘッダー
Authorization: Bearer <EAS_TOKEN>パスパラメーター
reference_audio_id:必須。参照音声ファイルの ID。ID を取得する方法については、「参照音声ファイルリストの表示」をご参照ください。タイプ:String。デフォルト値:None。
レスポンスパラメーター
音声オブジェクトへの参照を返します。
リクエスト例
cURL
# <EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。 # <reference_audio_id> を参照音声 ID に置き換えます。 curl -XDELETE <EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id> \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.delete( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>", # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN> をサービストークンに置き換えます。 } ) print(response.text)レスポンス例
{ "code": "OK", "message": "reference audio: c0939ce0-308e-4073-918f-91ac88e3**** deleted.", "data": {} }
音声合成の作成
呼び出しメソッド
エンドポイント
<EAS_SERVICE_URL>/api/v1/audio/speechリクエストメソッド
POST
リクエストヘッダー
Authorization: Bearer <EAS_TOKEN>Content-Type: application/json
リクエストパラメーター
model:必須。モデル名。CosyVoice2-0.5B のみがサポートされています。タイプ:string。デフォルト値:None。
input:必須。入力コンテンツ。タイプ:object。デフォルト値:None。オブジェクトには次のパラメーターが含まれます:
mode:必須。音声合成モード。タイプ:string。有効値:
fast_replication:高速レプリケーション
cross_lingual_replication:クロスリンガルレプリケーション
natural_language_replication:自然言語レプリケーション
text:必須。合成するテキスト。タイプ:string。デフォルト値:None。
reference_audio_id:必須。参照音声ファイルの ID。ID を取得する方法については、「参照音声ファイルリストの表示」をご参照ください。タイプ:string。デフォルト値:None。
instruct:任意。トーン、感情、速度などの音声スタイルを動的に調整するための命令テキスト。このパラメーターは、mode が natural_language_replication に設定されている場合にのみ有効です。タイプ:string。デフォルト値:None。
sample_rate:任意。音声サンプリングレート。デフォルト値:24000。
bit_rate: 任意。ビットレート。タイプ:string。デフォルト値:192k。サポートされている値:16k、32k、48k、64k、128k、192k、256k、320k、384k。
volume:任意。ボリューム。タイプ:float。デフォルト値:1.0。たとえば、3.0 はボリュームが 3 倍、0.8 はボリュームが 0.8 倍であることを意味します。
speed:任意。出力音声の速度。値の範囲は 0.5 から 2.0 です。タイプ:float。デフォルト値:1.0。
output_format:任意。出力音声のフォーマット。サポートされているフォーマット:wav、mp3、pcm。デフォルト値:wav。
stream:任意。ストリーミング出力を有効にするかどうかを指定します。タイプ:boolean。デフォルト値:true。
レスポンスパラメーター
ストリームで音声チャンクオブジェクトを返します。詳細については、「レスポンスパラメーターリスト」をご参照ください。
リクエスト例
非ストリーミング呼び出し
cURL
<EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。
<reference_audio_id> を参照音声 ID に置き換えます。
# <EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。 # <reference_audio_id> を参照音声 ID に置き換えます。 curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/speech \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", "text": "遠方の友人から誕生日プレゼントが届きました。予期せぬサプライズと心温まる祝福に、私の心は甘い喜びに満たされ、自然と笑みがこぼれました。", "speed": 1.0, "output_format": "mp3", "sample_rate": 32000, "bit_rate": "48k", "volume": 2.0, "instruct": "四川方言で話してください" }, "stream": false }'Base64 エンコードされた結果が返されます:
{"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"}Python
次の依存関係をインストールします:
pip install requests==2.32.3 packaging==24.2import json import base64 import requests from packaging import version required_version = "2.32.3" if version.parse(requests.__version__) < version.parse(required_version): raise RuntimeError(f"requests version must >= {required_version}") with requests.post( "<EAS_SERVICE_URL>/api/v1/audio/speech", # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 # 例: "http://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api/v1/audio/speech" headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN> をサービストークンに置き換えます。 "Content-Type": "application/json", }, json={ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", # <reference_audio_id> を参照音声 ID に置き換えます。 "text": "遠方の友人から誕生日プレゼントが届きました。予期せぬサプライズと心温まる祝福に、私の心は甘い喜びに満たされ、自然と笑みがこぼれました。", "output_format": "mp3", "sample_rate": 24000, "speed": 1.0, "bit_rate": "48k", "volume": 2.0, "instruct": "四川方言で話してください" }, "stream": False }, timeout=10 ) as response: if response.status_code != 200: print(response.text) exit() data = json.loads(response.content) encode_buffer = data['output']['audio']['data'] decode_buffer = base64.b64decode(encode_buffer) with open('./http_non_stream.mp3', 'wb') as f: f.write(decode_buffer)ストリーミング呼び出し
cURL
<EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。
<reference_audio_id> を参照音声 ID に置き換えます。
# <EAS_SERVICE_URL> と <EAS_TOKEN> をサービスのエンドポイントとトークンに置き換えます。 # <reference_audio_id> を参照音声 ID に置き換えます。 curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/speech \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", "text": "遠方の友人から誕生日プレゼントが届きました。予期せぬサプライズと心温まる祝福に、私の心は甘い喜びに満たされ、自然と笑みがこぼれました。", "speed": 1.0, "output_format": "mp3", "sample_rate": 32000, "bit_rate": "48k", "volume": 2.0, "instruct": "四川方言で話してください" }, "stream": true }'Base64 エンコードされた結果が返されます:
data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"}Python
Python SSE クライアントをインストールします:
pip install requests==2.32.3 packaging==24.2 sseclient-py==1.8.0 -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.comimport io import json import base64 import wave import requests from sseclient import SSEClient # pip install sseclient-py from packaging import version required_version = "2.32.3" if version.parse(requests.__version__) < version.parse(required_version): raise RuntimeError(f"requests version must >= {required_version}") with requests.post( "<EAS_SERVICE_URL>/api/v1/audio/speech", # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 # 例: "http://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api/v1/audio/speech" headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN> をサービストークンに置き換えます。 "Content-Type": "application/json", }, json={ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", # <reference_audio_id> を参照音声 ID に置き換えます。 "text": "遠くの友人から誕生日プレゼントを受け取り、予期せぬ驚きと深い祝福が私の心を甘い喜びで満たし、私の笑顔は花のように咲きました。", "output_format": "mp3", "sample_rate": 24000, "speed": 1.0, "bit_rate": "48k", "volume": 2.0, "instruct": "四川方言で話してください" }, }, timeout=10 ) as response: if response.status_code != 200: print(response.text) exit() messages = SSEClient(response) with open('./http_stream.mp3', 'wb') as f: for i, msg in enumerate(messages.events()): print(f"Event: {msg.event}, Data: {msg.data}") data = json.loads(msg.data) if data['error'] is not None: print(data['error']) break encode_buffer = data['output']['audio']['data'] decode_buffer = base64.b64decode(encode_buffer) f.write(decode_buffer)Websocket API
次の依存関係をインストールします:
pip install websocket-client==1.8.0 -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.com#!/usr/bin/python # -*- coding: utf-8 -*- import base64 import json import logging import sys import time import uuid import traceback import websocket class TTSClient: def __init__(self, api_key, uri, params, log_level='INFO'): """ TTSClient インスタンスを初期化します。 Parameters: api_key (str): 認証用の API キー。 uri (str): WebSocket サービスエンドポイント。 """ self._api_key = api_key # API キーに置き換えます。 self._uri = uri # WebSocket エンドポイントに置き換えます。 self._task_id = str(uuid.uuid4()) # 一意のタスク ID を生成します。 self._ws = None # WebSocketApp インスタンス self._task_started = False # タスク開始メッセージが受信されたかどうかを指定します。 self._task_finished = False # タスク終了またはタスク失敗メッセージが受信されたかどうかを指定します。 self._check_params(params) self._params = params self._chunk_metrics = [] self._metrics = {} self._first_package_time = None self._last_time = None self._init_log(log_level) self.audio_data = b'' def _init_log(self, log_level): self._log = logging.getLogger("ws_client") log_formatter = logging.Formatter('%(asctime)s - Process(%(process)s) - %(levelname)s - %(message)s') stream_handler = logging.StreamHandler(stream=sys.stdout) stream_handler.setFormatter(log_formatter) self._log.addHandler(stream_handler) self._log.setLevel(log_level) def get_metrics(self): """合成結果のパフォーマンスメトリックを取得します。""" return self._metrics def _check_params(self, params): assert 'mode' in params and params['mode'] in ['fast_replication', 'cross_lingual_replication', 'natural_language_replication'] assert 'reference_audio_id' in params assert 'output_format' in params and params['output_format'] in ['wav', 'mp3', 'pcm'] if params['mode'] == 'natural_language_replication': assert 'instruct' in params and params['instruct'] else: if 'instruct' in params: del params['instruct'] def on_open(self, ws): """ WebSocket 接続が確立されたときのコールバック関数。 run-task 命令を送信して、音声合成タスクを開始します。 """ self._log.debug("WebSocket connected") # run-task 命令を構築します。 run_task_cmd = { "header": { "action": "run-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "task_group": "audio", "task": "tts", "function": "SpeechSynthesizer", "model": "cosyvoice-v2", "parameters": { "mode": self._params['mode'], "reference_audio_id": self._params['reference_audio_id'], "output_format": self._params.get('output_format', 'wav'), "sample_rate": self._params.get('sample_rate', 24000), "bit_rate": self._params.get('bit_rate', '192k'), "volume": self._params.get('volume', 1.0), "instruct": self._params.get('instruct', ''), "speed": self._params.get('speed', 1.0), "debug": True, }, "input": {} } } # run-task 命令を送信します。 ws.send(json.dumps(run_task_cmd)) self._log.debug("run-task instruction sent") def on_message(self, ws, message): """ メッセージを受信したときのコールバック関数。 テキストメッセージとバイナリメッセージを個別に処理します。 """ try: msg_json = json.loads(message) # self._log.debug(f"Received JSON message: {msg_json}") self._log.debug(f"Received JSON message: {msg_json['header']['event']}") if "header" in msg_json: header = msg_json["header"] if "event" in header: event = header["event"] if event == "task-started": self._log.debug("Task started") self._task_started = True # continue-task 命令を送信します。 for text in self._params['texts']: self.send_continue_task(text) # すべての continue-task 命令を送信した後、finish-task 命令を送信します。 self.send_finish_task() self._last_time = time.time() elif event == "result-generated": metrics = msg_json['payload']['metrics'] cur_time = time.time() metrics['client_cost_time'] = cur_time - self._last_time self._last_time = cur_time encode_data = msg_json["payload"]["output"]["audio"]["data"] decode_data = base64.b64decode(encode_data) self._log.debug(f"Received audio data, size: {len(decode_data)} bytes") self.audio_data += decode_data metrics['client_rtf'] = metrics['client_cost_time'] / metrics['speech_len'] self._chunk_metrics.append(metrics) elif event == "task-finished": self._metrics = { 'client_first_package_time': self._chunk_metrics[0]['client_cost_time'], "client_rtf": sum([m["client_cost_time"] for m in self._chunk_metrics]) / sum([m["speech_len"] for m in self._chunk_metrics]), 'client_cost_time': sum([m["client_cost_time"] for m in self._chunk_metrics]), 'speech_len': sum([m["speech_len"] for m in self._chunk_metrics]), 'server_first_package_time': self._chunk_metrics[0]['server_cost_time'], 'server_rtf': sum([m["server_cost_time"] for m in self._chunk_metrics]) / sum([m["speech_len"] for m in self._chunk_metrics]), 'server_cost_time': sum([m["server_cost_time"] for m in self._chunk_metrics]), "generate_time": sum([m["generate_time"] for m in self._chunk_metrics]) } self._log.debug(f"Task finished. Request performance metrics: client_first_package_time: {self._metrics['client_first_package_time']:.3f}, client_rtf: {self._metrics['client_rtf']:.3f}, client_cost_time: {self._metrics['client_cost_time']:.3f}, speech_len: {self._metrics['speech_len']:.3f}, server_cost_time: {self._metrics['server_cost_time']:.3f}, generate_time: {self._metrics['generate_time']:.3f}") self._task_finished = True self.close(ws) elif event == "task-failed": self._log.error(f"Task failed: {msg_json}") self._task_finished = True self.close(ws) except json.JSONDecodeError as e: self._log.error(f"JSON parsing failed: {str(e)}\t{traceback.format_exc()}") def on_error(self, ws, error): """エラーが発生したときのコールバック関数。""" self._log.error(f"WebSocket error: {error}\t{traceback.format_exc()}") self._metrics = {'error': error} def on_close(self, ws, close_status_code, close_msg): """接続が閉じられたときのコールバック関数。""" self._log.debug(f"WebSocket closed: {close_msg} ({close_status_code})") def send_continue_task(self, text): """合成するテキストを含む continue-task 命令を送信します。""" cmd = { "header": { "action": "continue-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "input": { "text": text } } } self._ws.send(json.dumps(cmd)) self._log.debug(f"Sent continue-task instruction, text content: {text}") def send_finish_task(self): """finish-task 命令を送信して、音声合成タスクを終了します。""" cmd = { "header": { "action": "finish-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "input": {} } } self._ws.send(json.dumps(cmd)) self._log.debug("Sent finish-task instruction") def close(self, ws): """接続をアクティブに閉じます。""" if ws and ws.sock and ws.sock.connected: ws.close() self._log.debug("Connection actively closed") def run(self): """WebSocket クライアントを開始します。""" # 認証用のリクエストヘッダーを設定します。 header = { "Authorization": f"Bearer {self._api_key}", } # WebSocketApp インスタンスを作成します。 self._ws = websocket.WebSocketApp( self._uri, header=header, on_open=self.on_open, on_message=self.on_message, on_error=self.on_error, on_close=self.on_close ) self._log.debug("Listening for WebSocket messages...") self._ws.run_forever() # 持続的接続リスナーを開始します。 # 例 if __name__ == "__main__": API_KEY = "<EAS_TOKEN>" # <EAS_TOKEN> をサービストークンに置き換えます。 SERVER_URI = "ws://<EAS_SERVICE_URL>/api-ws/v1/audio/speech" # <EAS_SERVICE_URL> をサービスのエンドポイントに置き換えます。 # 例: "ws://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api-ws/v1/audio/speech" texts = [ "遠方の友人から誕生日プレゼントが届きました。予期せぬサプライズと心温まる祝福に、私の心は甘い喜びに満たされ、自然と笑みがこぼれました。" ] params = { "mode": "natural_language_replication", "texts": texts, "reference_audio_id": "<reference_audio_id>", "speed": 1.0, "output_format": "mp3", "sample_rate": 24000, "bit_rate": "48k", "volume": 2.0, "instruct": "落ち着いたトーンで話してください" } client = TTSClient(API_KEY, SERVER_URI, params, log_level='DEBUG') client.run() with open('./websocket_stream.mp3', 'wb') as wfile: wfile.write(client.audio_data)