1 年分の北京の気象データを使用してヘイズ予測モデルを構築し、PM 2.5 レベルに最も大きな影響を与える汚染物質を特定します。
データセット
この実験では、2016 年の北京の 1 時間ごとの大気質データを使用します。フィールドの説明を次の表に示します。
|
フィールド名 |
型 |
説明 |
|
time |
STRING |
日付、日にちまで正確。 |
|
hour |
STRING |
データ収集の時間。 |
|
pm2 |
STRING |
PM 2.5 インデックス。 |
|
pm10 |
STRING |
PM 10 インデックス。 |
|
so2 |
STRING |
二酸化硫黄インデックス。 |
|
co |
STRING |
一酸化炭素インデックス。 |
|
no2 |
STRING |
二酸化窒素インデックス。 |
ヘイズ予測
-
Machine Learning Designer ページに移動します。
-
PAI コンソールにログインします。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。ワークスペースページで、管理するワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、 を選択します。
-
-
ワークフローを構築します。
「[Designer]」ページで、[プリセットテンプレート] タブをクリックします。
-
テンプレートリストの [ヘイズ予測] セクションで、[作成] をクリックします。
[New Workflow] ダイアログボックスで、パラメーターを設定します。デフォルト値を使用できます。
[ワークフロー データ ストレージ] は、ワークフローが実行中に生成される一時データおよびモデルを格納するための OSS バケット パスに設定されています。
[OK] をクリックします。
ワークフローは約 10 秒で作成されます。
-
ワークフローリストで、[Haze Prediction] ワークフローをダブルクリックします。
-
次の図に示すように、ワークフローはプリセットテンプレートに基づいて自動的に構築されます。
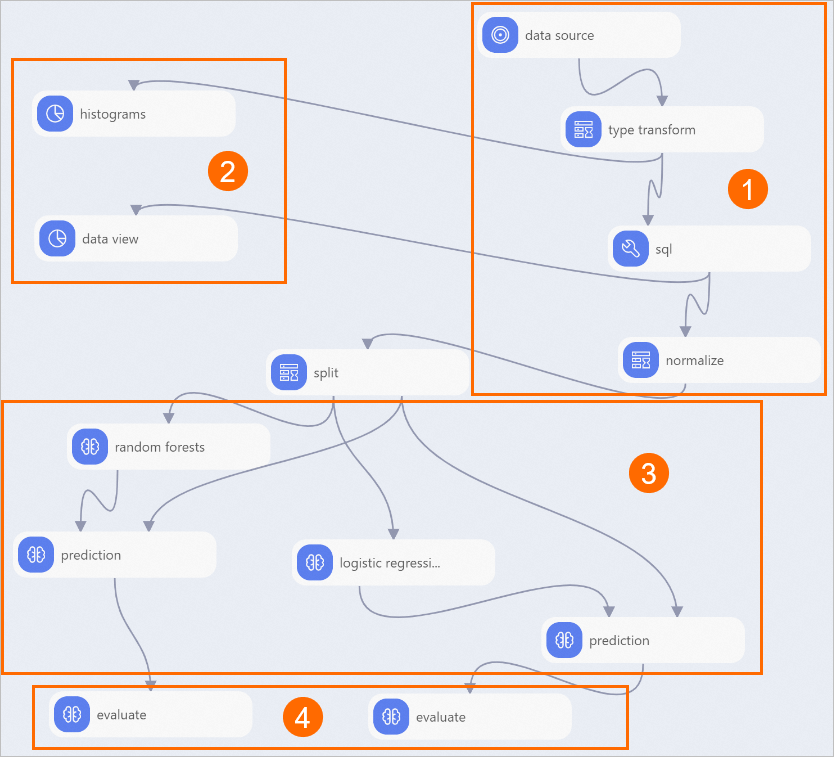
エリア
説明
①
データのインポートと前処理:
-
[Read Table] コンポーネントは、データソースをインポートします。
-
[Type Transform] コンポーネントは、STRING 型のデータを DOUBLE 型に変換します。
-
SQL スクリプト コンポーネントは、ターゲット列をバイナリ型(0 および 1)に変換します。この実験では、pm2 列がターゲットです。200より大きい値は重度のもやを示し、値 1 が割り当てられます。それ以外では 0 が割り当てられます。SQL ステートメント:
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1}; -
[正規化] コンポーネントは、さまざまな汚染物質指標の単位を統一し、ディメンションの違いを除去します。
②
統計分析:
-
[ヒストグラム] コンポーネントは、各汚染物質の分布を可視化します。
PM2.5 の場合、最も頻繁に出現する値の範囲は 11.74 から 15.61 で、発生数は 430 回です。次の図に示します。
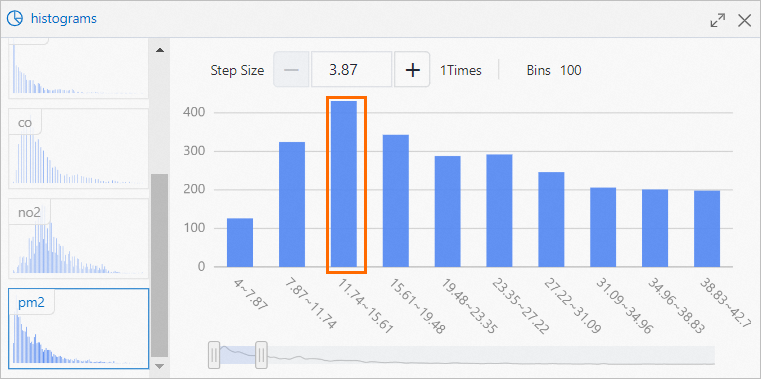
-
[Data View] コンポーネントは、異なる汚染物質の間隔が結果に与える影響を可視化します。
[no2] の場合、112.33~113.9 の間隔では、次の図に示すように、値が 0 のターゲットが 7 個、値が 1 のターゲットが 9 個生成されました。[no2] の値が 112.33~113.9 の範囲内にある場合、重度の煙霧が発生する確率が高くなります。エントロピーとジニは、この特徴量の間隔がターゲット値に与える影響を、情報理論の観点から定量化します。値が大きいほど、影響が大きいことを示します。
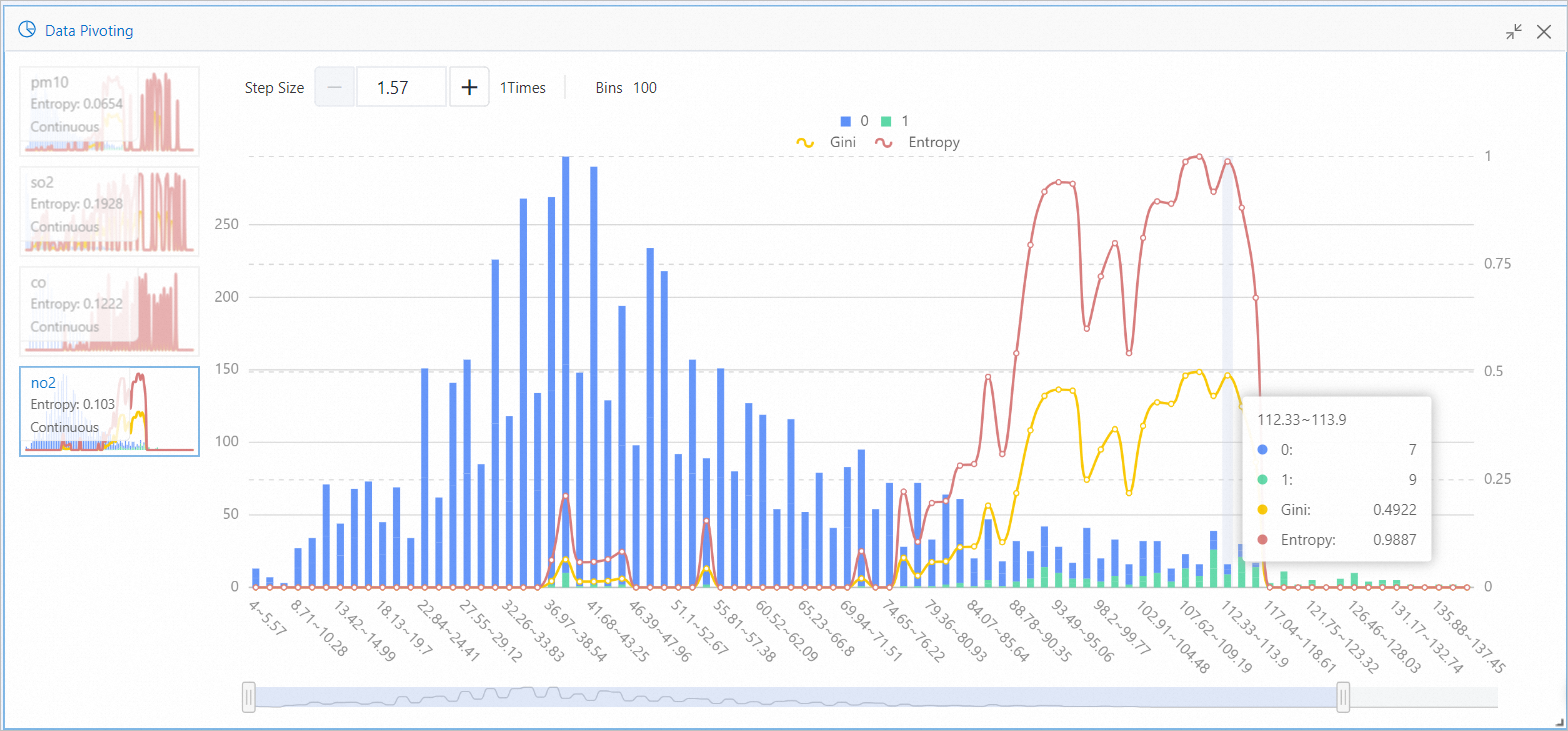
③
モデルの学習と予測。この実験では、[ランダムフォレスト] および [バイナリロジスティック回帰] コンポーネントを使用してモデルを学習します。
④
モデルの評価。
-
-
ワークフローを実行し、モデルのパフォーマンスを表示します。
-
キャンバスの上にある実行ボタン
 をクリックします。
をクリックします。 -
ワークフローが完了したら、キャンバス上の[ランダムフォレスト]コンポーネントの下流にある[二値分類評価]コンポーネントを右クリックします。ショートカットメニューから[ビジュアル分析]を選択します。
-
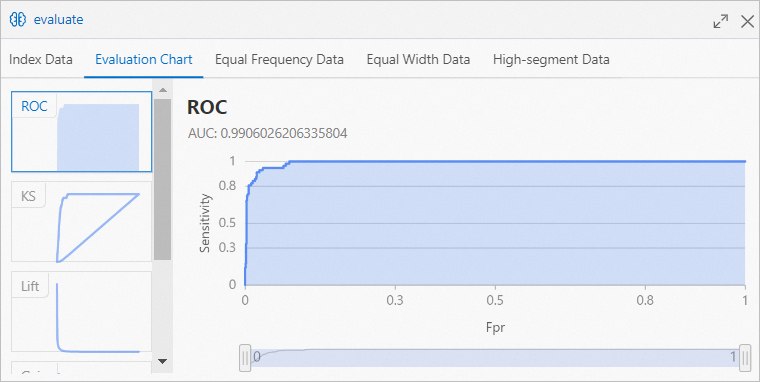
[評価チャート] タブを [2値分類評価] ダイアログボックスでクリックして、[ランダムフォレスト] コンポーネントで学習されたモデルの予測性能を表示できます。
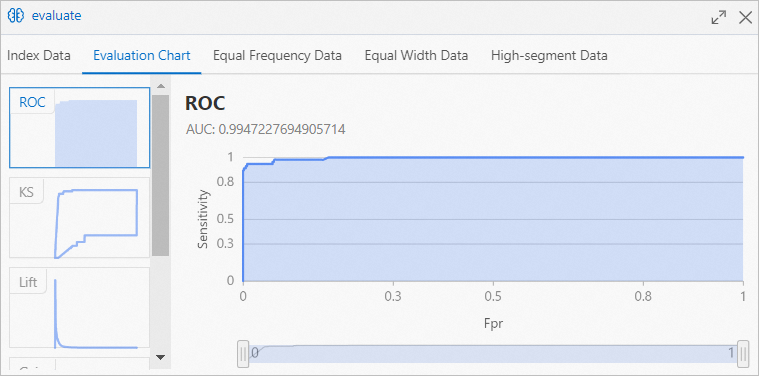 曲線下面積 (AUC) の値は、[Random Forest] コンポーネントでトレーニングされたヘイズ予測モデルの精度が 99% を超えていることを示しています。
曲線下面積 (AUC) の値は、[Random Forest] コンポーネントでトレーニングされたヘイズ予測モデルの精度が 99% を超えていることを示しています。 -
キャンバスで、[二項ロジスティック回帰] コンポーネントの下流にある [二項分類評価] コンポーネントを右クリックします。ショートカットメニューから [ビジュアル分析] を選択します。
-
[二項分類評価]ダイアログボックスで、[評価チャート]タブをクリックして、[二項ロジスティック回帰]コンポーネントによってトレーニングされたモデルの予測性能を表示します。
 AUC値は、[ロジスティック回帰] コンポーネントで学習された霧状の天気予測モデルの精度が98%を超えていることを示します。
AUC値は、[ロジスティック回帰] コンポーネントで学習された霧状の天気予測モデルの精度が98%を超えていることを示します。
-