このトピックでは、Platform for AI (PAI) が提供するテキスト分析コンポーネントを使用して、プロダクトタグの自動分類のためのシンプルなシステムを構築する方法について説明します。
背景情報
プロダクトの説明には、通常、複数のディメンションからのタグが含まれています。たとえば、靴の説明には「ガーリーなブリティッシュスタイル、レースアップマーティンブーツ、女性用、フロスト加工本革、厚底カジュアルショートブーツ」とあるかもしれません。バッグの説明には「日替わり特別オファーバッグ、2016年秋冬新作、クロスボディバッグ、韓国スタイルハンドバッグ、タッセルシェルバッグ、女性用バッグ、ショルダーバッグ」とあるかもしれません。これらのディメンションには、時間、起源、スタイルなどの属性が含まれます。数万ものプロダクトを特定のディメンションで分類することは、E コマースプラットフォームにとって課題です。最大の課題は、プロダクトの説明からディメンションタグを抽出することです。PAI が提供するテキスト分析コンポーネントは、タグ単語を自動的に学習し、自動タグ分類を実行できます。
前提条件
ワークスペースが作成されていること。詳細については、「ワークスペースの作成と管理」をご参照ください。
MaxCompute リソースがワークスペースに関連付けられていること。詳細については、「ワークスペースの作成と管理」をご参照ください。
データセットの準備
このワークフローのデータセットは、2016 年の独身の日のショッピングリストをキュレーションしたもので、2,000 を超えるプロダクトの説明が含まれています。各行は、単一プロダクトのタグ集約を表します。
DataWorks の DataStudio モジュールで、content という名前の単一列を含むテーブルを作成し、データセットをテーブルにアップロードします。詳細については、「テーブルの作成とデータのアップロード」をご参照ください。
類似タグの自動分類
-
Machine Learning Designer ページに移動します。
-
PAI コンソールにログインします。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。ワークスペースページで、管理するワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、 を選択します。
-
カスタムパイプラインを作成し、パイプラインページを開きます。詳細については、「カスタムパイプラインの作成」をご参照ください。
パイプラインを構築して実行します。
左側のコンポーネントリストの [ソース/デスティネーション] から [テーブルの読み込み] コンポーネントをキャンバスにドラッグし、名前を shopping_data-1 に変更します。
左側のコンポーネントリストから、[単語分割]、[単語カウント]、および [Word2Vec] コンポーネントを からキャンバスにドラッグします。
左側のコンポーネントリストから、[データ前処理] セクションにある [ID 列の追加] コンポーネントと [型変換] コンポーネントをキャンバスにドラッグします。
左側のコンポーネントリストから、[K-Means Clustering] コンポーネントを からキャンバスにドラッグします。
左側のコンポーネントリストから、[カスタムスクリプト] カテゴリの [SQL スクリプト] コンポーネントをキャンバスにドラッグします。
コンポーネントを接続してパイプラインを構築します。次の表で説明されているように、各コンポーネントの主要なパラメーターを設定し、パイプラインを実行します。
キャンバスで、shopping_data-1 コンポーネントをクリックします。右側の [テーブルの選択] タブで、準備済みテーブルの名前を設定します。
キャンバス上で、[Split Word-1] コンポーネントをクリックします。右側の [フィールド設定] タブで、[content] 列を選択します。
まず、shopping_data-1 コンポーネントをクリックし、ショートカットメニューから [Execute Node] をクリックします。コンポーネントの実行が完了したら、同じ方法で [Split Word-1] コンポーネントを実行します。
キャンバスで、[Word Count-1] コンポーネントをクリックします。右側の [フィールド設定] タブで、[ドキュメント ID 列の選択] を [append_id] に、[ドキュメントコンテンツ列の選択] を [content] に設定します。
[Word Count-1] コンポーネントをクリックし、ショートカットメニューから [ノードの実行] をクリックします。
ベクトル距離が小さい 2 つの単語は、類似した意味を持ちます。
異なる単語間の距離の差には、特定 の意味があります。
キャンバス上で、[Word2Vec-1] コンポーネントをクリックします。右側の [フィールド設定] タブで、[単語列の選択] を [word] に設定します。[パラメーター] タブで、[階層的ソフトマックスを使用] を選択します。
[Word2Vec-1] コンポーネントをクリックし、ショートカットメニューから [ノードの実行] をクリックします。
キャンバス上で、[K-Means クラスタリング-1] コンポーネントをクリックします。右側の [フィールド設定] タブで、[特徴量カラム] を [f0] に、[追加カラム] を [word] に設定します。
説明このコンポーネントを実行する場合、アップストリーム入力データテーブルの行数は、コンポーネントのパラメーターで設定されたクラスター数以上である必要があります。
[K-Means Clustering-1] コンポーネントをクリックし、ショートカットメニューから [Execute Node] をクリックします。
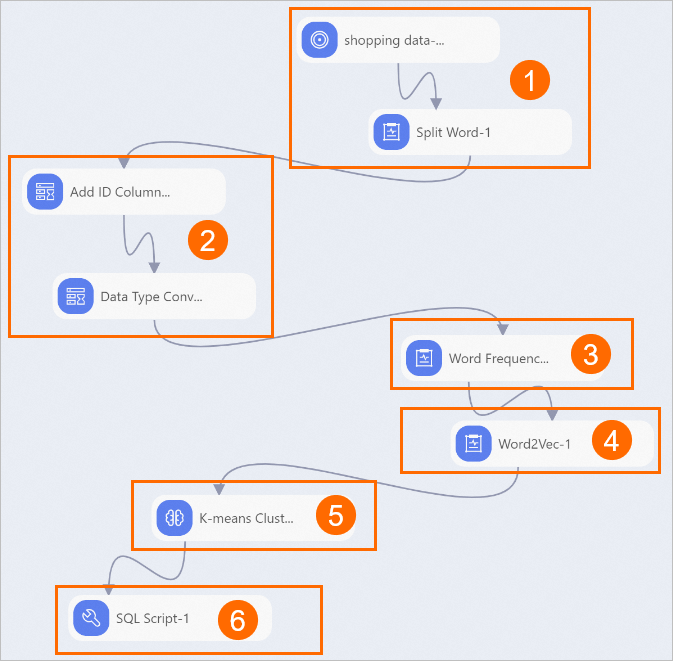
番号
説明
①
shopping_data データをアップロードし、Split Word コンポーネントを使用してデータをトークン化します。手順は次のとおりです。
②
ID 列を追加します。アップロードされたデータにはフィールドが 1 つしかないため、これは必要です。ID 列は、各データ入力のプライマリキーとして機能します。
まず、[ID列の追加-1] コンポーネントをクリックし、ショートカットメニューから [ノードの実行] をクリックします。このコンポーネントの実行が完了したら、同じ方法で [型変換-1] コンポーネントを実行します。
③
単語頻度をカウントして、各プロダクトの説明に表示されるさまざまな単語の数を示します。
④
Word2Vec コンポーネントを使用して、各単語をその意味に基づいてベクトル次元に展開し、単語ベクトルを生成します。単語ベクトルの意味には、次のものが含まれます。
Word2Vec コンポーネーントは、各単語を 100 次元空間にマッピングします。
⑤
単語ベクトルをクラスター化します。k 平均法クラスタリングアルゴリズムを使用して、生成された単語ベクトルに基づいて単語ベクトル間の距離を計算し、意味に基づいてタグ単語を自動分類します。
⑥
結果を確認します。[SQL スクリプト-1] コンポーネントを使用して、クラスターからランダムなカテゴリを選択し、同じカテゴリのタグが自動的にグループ化されるかどうかを確認します。このパイプラインは、10 番目のクラスターグループを選択します。キャンバス上で、[SQL スクリプト-1] コンポーネントをクリックします。右側の [パラメーター] タブで、[SQL スクリプト] を
select * from ${t1} where cluster_index=10に設定します。結果では、システムは地理関連タグを自動的に一緒に分類します。ただし、nuts のように、カテゴリに明らかに適合しないタグが混在しています。これは、トレーニングサンプルの数が不十分であるためである可能性があります。トレーニングサンプルが十分に大きい場合、タグクラスタリング結果は非常に正確です。
参考資料
アルゴリズムコンポーネントの詳細については、次のトピックをご参照ください。