PyAlink スクリプトコンポーネントを使用すると、コードを記述して任意の Alink アルゴリズムを呼び出すことができます。このコンポーネントを使用して、分類、回帰、レコメンデーションなどのタスクを実行できます。PyAlink スクリプトは Machine Learning Designer の他のコンポーネントともシームレスに統合されるため、エンドツーエンドのビジネスパイプラインを構築および検証できます。このトピックでは、PyAlink スクリプトコンポーネントの使用方法について説明します。
背景情報
PyAlink スクリプトコンポーネントは、単独で使用するか、Machine Learning Designer の他のコンポーネントと組み合わせて使用できます。数百の Alink コンポーネントにアクセスでき、コードを通じてデータ型の読み取りと書き込みをサポートします。また、このコンポーネントで生成した PipelineModel を EAS サービスとしてデプロイすることもできます。詳細については、「例:PyAlink スクリプトで生成したモデルを EAS サービスとしてデプロイする」をご参照ください。
基本概念
PyAlink スクリプトコンポーネントを使用する前に、以下の主要な概念を理解してください。
|
概念 |
説明 |
|
オペレーター |
Alink では、オペレーターはアルゴリズム機能を表します。オペレーターは、バッチオペレーターとストリームオペレーターに分類されます。例えば、ロジスティック回帰には以下のオペレーターが含まれます。
オペレーターは、 各オペレーターにはパラメータがあります。例えば、ロジスティック回帰には以下のパラメータが含まれます。
パラメータを構成するには、 データソースとデータシンクは特別なタイプのオペレーターです。定義後、  Alink には、一般的なストリームおよびバッチデータソースが含まれています。以下のコードは例です。 |
|
パイプライン |
Alink アルゴリズムをパイプラインで使用し、データ処理、特徴量エンジニアリング、モデルのトレーニングを 1 つのパイプラインに統合して、トレーニング、予測、オンラインサービスを実行することもできます。以下のコードは例です。 |
|
ベクトル |
Alink のカスタムデータ型であり、2 つの形式をサポートします。
説明
Alink では、列がベクトル型の場合、パラメータ名は通常 |
PyAlink スクリプトでサポートされる Alink コンポーネント
PyAlink スクリプトでは、データ処理、特徴量エンジニアリング、モデルのトレーニング用のコンポーネントなど、数百の Alink コンポーネントを使用できます。
PyAlink スクリプトコンポーネントは現在、パイプラインコンポーネントとバッチコンポーネントをサポートしていますが、ストリームコンポーネントはサポートしていません。
方法1:PyAlink スクリプトを単独で使用する
このトピックでは、ItemCf モデルを使用して movielens データセットをスコアリングする例を用いて、Machine Learning Designer プラットフォームと Alibaba Cloud リソースを使用して PyAlink スクリプトで実装したパイプラインを実行する方法について説明します。手順は以下のとおりです。
-
Machine Learning Designer ページに移動し、空のパイプラインを作成します。詳細については、「手順」をご参照ください。
-
パイプラインリストで、作成した空のパイプラインを選択し、[Open] をクリックします。
-
左側のコンポーネントリストの検索ボックスで [PyAlink Script] を検索し、[PyAlink Script] を右側のキャンバスにドラッグします。キャンバス上に [PyAlink Script-1] という名前のパイプラインノードが自動的に生成されます。
-
キャンバスで [PyAlink Script-1] ノードを選択します。右側のペインで、[Parameter Settings] タブと [実行チューニング] タブのパラメータを構成します。
-
[Parameter Settings] タブで、コードを記述します。以下のコードは例です。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") result = itemCF.transform(predictData) result.link(sinks[0]) BatchOperator.execute()PyAlink スクリプトは 4 つの出力ポートをサポートします。スクリプト内で
result.link(sinks[0])を使用して、最初の出力ポートにデータを書き込みます。下流コンポーネントは、この最初の出力ポートに接続することで、スクリプトからデータを読み取れます。詳細については、「PyAlink スクリプトでのデータの読み取りと書き込み」をご参照ください。 -
[実行チューニング] タブで、実行モードとノード仕様を設定します。
パラメータ
説明
[ジョブ実行モード]
以下のモードをサポートします。
-
[DLC (Single-machine, multi-concurrency)]:小規模なデータセットのタスク、デバッグおよび検証目的に推奨します。
-
[MaxCompute (Distributed)]:大規模なデータセットのタスクまたは本番タスクに推奨します。
-
[フルマネージド Flink]:ワークスペースに紐付けられたフルマネージド Flink クラスターでジョブを実行します。
[ワーカー数]
このパラメータは、[ジョブ実行モード]が [MaxCompute (Distributed)] または [フルマネージド Flink (Distributed)] の場合にのみ必要です。このパラメータは、実行ノードの数を指定します。このパラメータを空のままにすると、システムはタスクデータに基づいてノードを自動的に割り当てます。デフォルト値は空です。
[ワーカーあたりのメモリ (MB)]
このパラメータは、[ジョブ実行モード]が [MaxCompute (Distributed)] または [フルマネージド Flink (Distributed)] に設定されている場合にのみ構成する必要があります。このパラメータは、単一ノードのメモリサイズを MB 単位で指定します。値は正の整数で、デフォルト値は 8192 です。
[ワーカーあたりの CPU コア数]
このパラメータは、[ジョブ実行モード]が [MaxCompute (Distributed)] または [フルマネージド Flink (Distributed)] に設定されている場合にのみ必要です。このパラメータは、単一ノードの CPU コア数を指定します。値は正の整数で、デフォルト値は空です。
[ノード仕様]
DLC ノードのリソースタイプ。デフォルトは 2 vCPU + 8 GB Mem-ecs.g6.large です。
-
-
-
キャンバスの上部で [Save] をクリックし、次に実行アイコン
 をクリックして PyAlink スクリプトを実行します。
をクリックして PyAlink スクリプトを実行します。 -
タスクが完了したら、キャンバス上の [PyAlink Script-1] ノードを右クリックし、 を選択して、結果を確認します。
列名
説明
user_id
ユーザー ID。
item_id
映画 ID。
prediction_score
映画に対するユーザーの好みを示します。このスコアは、レコメンデーションの参考として使用できます。
方法2:PyAlink スクリプトを他のコンポーネントと組み合わせる
PyAlink スクリプトコンポーネントの入力ポートと出力ポートは、Machine Learning Designer の他のアルゴリズムコンポーネントと同じです。以下の図に示すように、それらを接続して組み合わせパイプラインを作成できます。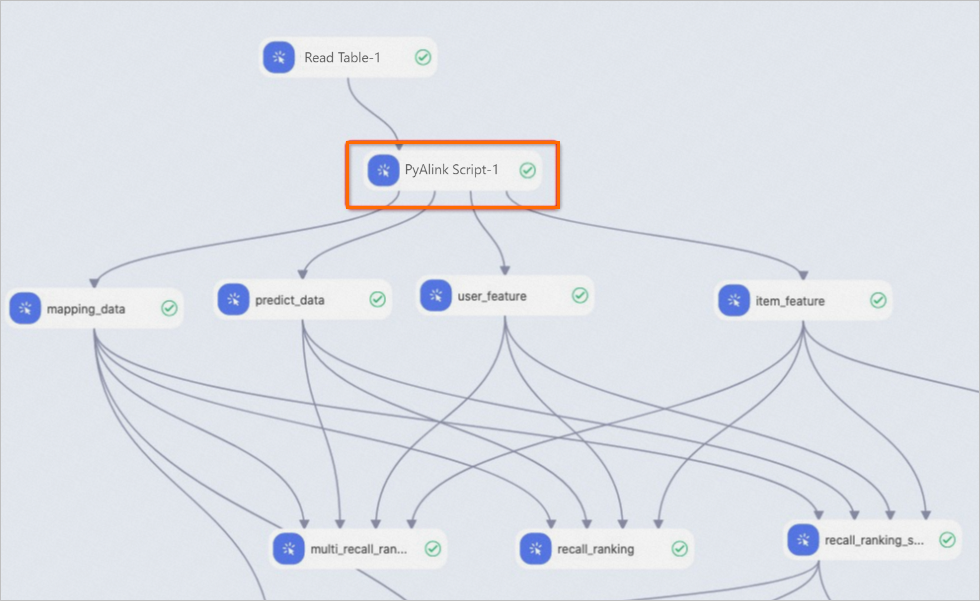
PyAlink スクリプトでのデータの読み取りと書き込み
-
データの読み取り
-
MaxCompute テーブルからの読み取り:スクリプトは、入力ポートを通じて上流コンポーネントから渡されたデータを読み取ります。以下のコードは例です。
train_data = sources[0] test_data = sources[1]コード内で、
sources[0]は最初の入力ポートに接続された MaxCompute テーブルを表し、sources[1]は 2 番目の入力ポートに接続されたテーブルを表します。コンポーネントは最大 4 つの入力ポートをサポートします。 -
ネットワークファイルシステムからの読み取り:スクリプトは、コード内で
CsvSourceBatchOpやAkSourceBatchOpなどの Alink のソースコンポーネントを使用してデータを読み取ります。以下のタイプのファイルを読み取れます。-
HTTP 経由でネットワークから共有ファイルを読み取ります。以下のコードは例です。
ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) -
OSS ファイルを読み取ります。まず、[パイプラインプロパティ] タブでパイプラインの一時データストレージパスを見つけます。このパスは
oss://<bucket-name>/<path>の形式で、OSS の読み取り/書き込み操作に使用します。以下のコードは例です。model_data = AkSourceBatchOp().setFilePath("oss://xxxxxxxx/model_20220323.ak")
-
-
-
データの書き込み
-
MaxCompute テーブルへの書き込み:スクリプトは、出力ポートを通じて下流コンポーネントにデータを書き込みます。以下のコードは例です。
result0.link(sinks[0]) result1.link(sinks[1]) BatchOperator.execute()result0.link(sinks[0])の行は、データを書き込み、最初の出力ポートを通じてアクセスできるようになります。最大 4 つの結果テーブルに書き込むことができ、4 つの出力ポートに対応します。 -
OSS ファイルへの書き込み。[パイプラインプロパティ] タブにある、パイプラインの [一時データストレージパス] フィールドで定義されている OSS パスを使用します。以下のコードは例です。
result.link(AkSinkBatchOp() \ .setFilePath("oss://xxxxxxxx/model_20220323.ak") \ .setOverwriteSink(True)) BatchOperator.execute()
-
例:モデルを EAS サービスとしてデプロイする
-
デプロイするモデルの生成
PyAlink スクリプトコンポーネントで生成した PipelineModel の場合にのみ、モデルを EAS サービスとしてデプロイできます。以下のコードを使用して PipelineModel ファイルを生成します。スクリプトの実行方法については、「方法1:PyAlink スクリプトコンポーネントを単独で使用する」をご参照ください。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") model = PipelineModel(itemCF) model.save().link(AkSinkBatchOp() \ .setFilePath("oss://<your_bucket_name>/model.ak") \ .setOverwriteSink(True)) BatchOperator.execute()<your_bucket_name>を OSS バケットの名前に置き換えます。重要PATH で構成されているデータセットパスに対する読み取り権限があることを確認してください。そうでない場合、コンポーネントの実行が失敗します。
-
EAS 構成ファイルの生成
以下のスクリプトを実行して、出力を
config.jsonファイルに書き込みます。# EAS 構成ファイル import json # EAS モデル構成を生成します model_config = {} # EAS が受信するデータのスキーマ model_config['inputDataSchema'] = "user_id long, item_id long" model_config['modelVersion'] = "v0.2" eas_config = { "name": "recomm_demo", "model_path": "http://xxxxxxxx/model.ak", "processor": "alink_outer_processor", "metadata": { "instance": 1, "memory": 2048, "region":"China (Beijing)" }, "model_config": model_config } print(json.dumps(eas_config, indent=4))config.jsonファイルの主要なパラメータ:-
name:デプロイするモデルサービスの名前です。 -
model_path:PipelineModelファイルが保存されている OSS パス。これをモデルファイルの実際の OSS パスに変更する必要があります。
config.jsonファイルの他のパラメータの説明については、「コマンドリファレンス」をご参照ください。 -
-
モデルの EAS サービスとしてのデプロイ
eascmd クライアントを使用してモデルをデプロイします。クライアントのセットアップ手順については、「クライアントのダウンロードと構成」をご参照ください。例えば、64 ビット Windows システムでは、次のコマンドを実行します。
eascmdwin64.exe create config.json