機械学習モデルのトレーニングでは、高次元データセットによってトレーニング速度が低下し、ノイズが発生します。主成分分析 (PCA) は、元の特徴から相関のない少数の主成分を抽出することで次元を削減し、可能な限り多くの分散を保持します。Machine Learning Platform for AI (PAI) の Machine Learning Designer にある PCA コンポーネントを使用して、下流モデルのトレーニングの前に表形式データを前処理します。
制限事項
PCA コンポーネントは、密形式のデータのみを受け入れます。疎行列はサポートされていません。
コンポーネントの設定
設定方法は、インタラクティブなセットアップのためのビジュアルパイプラインエディターを使用する方法と、スクリプト化および自動化されたワークフローのための PAI コマンドを使用する方法の 2 つがあります。
方法1:パイプラインページでの設定
Machine Learning Designer でパイプラインを開き、PCA コンポーネントを選択して、以下のパラメーターを設定します。
| タブ | パラメーター | 説明 |
|---|---|---|
| [フィールド設定] | [特徴列] | 入力テーブルから分析対象として選択された列。 |
| [フィールド設定] | [追加列] | 次元削減後に出力テーブルに追加される列。 |
| [パラメーター設定] | データサイズ比率 | 保持する寄与率。有効値:(0, 1)。デフォルト値:0.9。 |
| [パラメーター設定] | [特徴分解モード] | 特徴を分解するために使用される行列。 |
| [パラメーター設定] | [データ変換方法] | 分解前にデータを前処理するために使用される方法。 |
| [チューニング] | [ライフサイクル] | 出力テーブルのライフサイクル。正の整数である必要があります。 |
| [チューニング] | [コア数] | 割り当てるコア数。[ノードあたりのメモリサイズ (単位: MB)] と一緒に使用します。有効値:[1, 9999]。 |
| [チューニング] | [ノードあたりのメモリサイズ (単位: MB)] | コアあたりのメモリ (MB)。有効値:[1024, 64 × 1024]。 |
方法2:PAI コマンドの使用
SQL Script コンポーネントを介して PAI コマンドを実行します。詳細については、「SQL Script」をご参照ください。
PAI -name PrinCompAnalysis
-project algo_public
-DinputTableName=bank_data
-DeigOutputTableName=pai_temp_2032_17900_2
-DprincompOutputTableName=pai_temp_2032_17900_1
-DselectedColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed
-DtransType=Simple
-DcalcuType=CORR
-DcontriRate=0.9;必須パラメーター
| パラメーター | 説明 |
|---|---|
inputTableName | トレーニングに使用する入力テーブル。 |
selectedColNames | 分析対象として選択された列。複数の列名はコンマ (,) で区切ります。INT 型または DOUBLE 型の列をサポートします。 |
eigOutputTableName | 固有値と固有ベクトルを含む出力テーブル。 |
princompOutputTableName | 主成分の次元削減とノイズリダクション後の出力テーブル。 |
オプションパラメーター
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
contriRate | 保持する寄与率。有効値:(0, 1)。 | 0.9 |
transType | データの前処理方法。有効値:Simple、Sub-Mean、Normalization。 | Simple |
calcuType | 特徴分解行列。有効値:CORR、COVAR_SAMP、COVAR_POP。 | CORR |
remainColumns | 次元削減後に出力に引き継がれる元のテーブルの列。 | なし |
coreNum | コア数。memSizePerCore と一緒に使用します。有効値:[1, 9999]。 | システムによって決定 |
memSizePerCore | コアあたりのメモリ (MB)。有効値:[1024, 64 × 1024]。 | システムによって決定 |
lifecycle | 出力テーブルのライフサイクル。正の整数である必要があります。 | なし |
例
次の例では、7 つの数値列 (pdays、previous、emp_var_rate、cons_price_idx、cons_conf_idx、euribor3m、nr_employed) を持つ bank_data テーブルを使用し、相関行列分解を用いて寄与率の 90% を保持します。
出力テーブルの例
次元削減後のデータテーブル — 保持された主成分を新しい列として含みます。
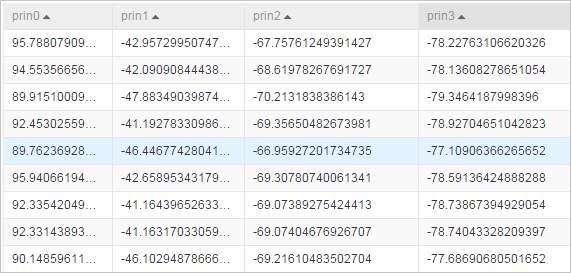
固有値テーブル — 各コンポーネントの固有値と累積寄与率を示します。このテーブルを使用して、保持されたコンポーネントの数と、
contriRateのしきい値を満たしているかどうかを確認します。