予測コンポーネントは、トレーニング済みモデルを新しいデータに適用し、結果を出力テーブルに書き込みます。ご利用のモデルが、ペアの予測コンポーネントを持たない従来のデータマイニングコンポーネントでトレーニングされた場合に使用します。
前提条件
開始する前に、以下があることを確認してください。
ビジュアルモデリングのトレーニング済みモデル
モデルが期待する特徴列を含む入力テーブル
コンポーネントの設定
方法1: ビジュアルモデリングでの設定
Machine Learning Platform for AI (PAI) コンソールのパイプラインキャンバスで、予測コンポーネントを選択し、次のパラメーターを設定します。
[フィールド設定] タブ
| パラメーター | 説明 |
|---|---|
| [特徴列] | 入力テーブルから選択された特徴列。デフォルトでは、すべての列が選択されています。 |
| [予約済み列] | 出力テーブルに引き継ぐ列。ダウンストリーム評価を容易にするために、ラベル列を含めます。 |
| [出力結果列] | 最上位の予測結果を含む出力列。 |
| [出力スコア列] | 最上位の予測結果の確率を含む出力列。 |
| [出力詳細列] | すべての可能な結果とその確率を含む出力列。 |
| [スパース行列] | 入力データがスパース形式 (キーと値のペア) の場合に有効にします。 |
| KV デリミタ | スパースデータ内のキーと値間のデリミタ。デフォルト: コロン (:)。 |
| [KVペアデリミタ] | スパースデータ内のキーと値のペア間のデリミタ。デフォルト: コンマ (,)。 |
[チューニング] タブ
| パラメーター | 説明 |
|---|---|
| コア | コア数。正の整数である必要があります。コアあたりのメモリサイズと組み合わせて使用します。 |
| コアあたりのメモリサイズ | コアあたりのメモリ (MB単位)。コアと組み合わせて使用します。 |
方法2: PAI コマンドの実行
SQL Script コンポーネントを使用して、次のコマンドを実行します。
pai -name prediction
-DmodelName=nb_model
-DinputTableName=wpbc
-DoutputTableName=wpbc_pred
-DappendColNames=label;パラメーター
| パラメーター | 必須 | 説明 | デフォルト |
|---|---|---|---|
inputTableName | はい | 入力テーブル名。 | — |
modelName | はい | トレーニング済みモデル名。 | — |
outputTableName | はい | 出力テーブル名。 | — |
featureColNames | いいえ | 入力テーブルからの特徴列。コンマで区切ります。 | すべての列 |
appendColNames | いいえ | 出力テーブルに追加する入力列。 | なし |
inputTablePartitions | いいえ | 入力テーブルから読み取るパーティション。サポートされている形式: 単一パーティションの場合は partition_name=value、多層パーティションの場合は name1=value1/name2=value2。複数のパーティションはコンマで区切ります。 | テーブル全体 |
outputTablePartition | いいえ | 出力テーブルに結果を書き込むパーティション。 | なし |
resultColName | いいえ | 最上位の予測結果の出力列。 | prediction_result |
scoreColName | いいえ | 最上位の予測結果の確率の出力列。 | prediction_score |
detailColName | いいえ | すべての可能な結果とその確率の出力列。 | prediction_detail |
enableSparse | いいえ | 入力データがスパースであるかどうか。有効な値: true、false。 | false |
itemDelimiter | いいえ | スパースなキーと値のペア間のデリミタ。 | , |
kvDelimiter | いいえ | スパースなキーと値間のデリミタ。 | : |
lifecycle | いいえ | 出力テーブルのライフサイクル。 | なし |
coreNum | いいえ | コア数。 | 自動的に割り当てられます |
memSizePerCore | いいえ | コアあたりのメモリ (MB)。 | 自動的に割り当てられます |
例
この例では、ランダムフォレスト分類器を構築し、同じデータに対して予測を実行します。
テスト入力テーブルの作成:
create table pai_rf_test_input as select * from ( select 1 as f0,2 as f1, "good" as class union all select 1 as f0,3 as f1, "good" as class union all select 1 as f0,4 as f1, "bad" as class union all select 0 as f0,3 as f1, "good" as class union all select 0 as f0,4 as f1, "bad" as class )tmp;ランダムフォレストアルゴリズムを使用してモデルをトレーニングします。
PAI -name randomforests -project algo_public -DinputTableName="pai_rf_test_input" -DmodelName="pai_rf_test_model" -DforceCategorical="f1" -DlabelColName="class" -DfeatureColNames="f0,f1" -DmaxRecordSize="100000" -DminNumPer="0" -DminNumObj="2" -DtreeNum="3";トレーニング済みモデルに対して予測を実行します。
PAI -name prediction -project algo_public -DinputTableName=pai_rf_test_input -DmodelName=pai_rf_test_model -DresultColName=prediction_result -DscoreColName=prediction_score -DdetailColName=prediction_detail -DoutputTableName=pai_temp_2283_76333_1出力テーブル
pai_temp_2283_76333_1の表示: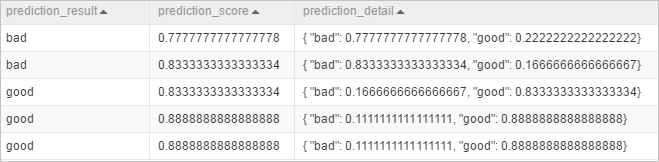
出力テーブルには3つの列が含まれています。
prediction_result: 最上位の予測結果 (最も高い確率を持つクラス)。この例では、値はgoodまたはbadです。prediction_score: 最上位の予測結果の確率。この例では、予測結果はどちらの確率が高いかによって good または bad になり得ます。prediction_scoreには最も高い確率が含まれています。prediction_detail: すべての可能な結果とその確率。