ナイーブベイズは、ベイズの定理に基づく確率的分類アルゴリズムです。このアルゴリズムでは、すべての特徴量が互いに統計的に独立であると仮定します。これは単純化された仮定ですが、トレーニングデータが限られている場合でも、高速かつ効果的な学習を実現します。
Machine Learning Designer の「ナイーブベイズ」コンポーネントでは、連続特徴(DOUBLE、BIGINT)および離散特徴(STRING、BOOLEAN、DATETIME)の 2 種類の特徴量を自動的に処理します。「強制変換列」パラメーターを使用すると、データの性質に応じてデフォルトの型推論をオーバーライドできます。たとえば、BIGINT 型の列を連続値ではなくカテゴリ値として扱う場合などに利用します。
「ナイーブベイズ」コンポーネントを利用するには、MaxCompute のコンピューティングリソースが必要です。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
設定済みのプロジェクトを持つ PAI コンソールへのアクセス権限
トレーニング用およびテスト用のテーブルを含む MaxCompute データソース
コンポーネントの設定
方法 1:PAI コンソールから設定
PAI コンソールにログインし、「ビジュアルモデリング(Designer)」に移動します。
パイプラインを開き、「ナイーブベイズ」コンポーネントをキャンバス上にドラッグ&ドロップします。
コンポーネントをクリックし、右側ペインでパラメーターを設定します。
[フィールド設定] タブ
| パラメーター | 説明 |
|---|---|
| 特徴列 | 特徴量として使用する列。デフォルト:ラベル列を除くすべての列。サポートされるデータ型:DOUBLE、STRING、BIGINT。 |
| 除外列 | トレーニングから除外する列。このパラメーターは「特徴列」と同時に設定できません。 |
| 強制変換列 | 特定の列についてデフォルトの型推論をオーバーライドします。空欄の場合は、以下のルールが適用されます:STRING、BOOLEAN、DATETIME 型の列は離散(カテゴリ)として扱われ、DOUBLE および BIGINT 型の列は連続として扱われます。BIGINT 型の列を連続ではなくカテゴリとして扱う場合は、ここで指定してください。 |
| ラベル列 | ターゲット列。DOUBLE、STRING、BIGINT 型である必要があります。また、特徴列としても指定することはできません。 |
| スパース形式の入力データを使用 | 入力データがキーと値のペア(key-value pairs)によるスパース形式である場合に有効化します。 |
| スパース入力時の K:V 区切り文字 | キーと値のペア間のデリミタ。デフォルト:カンマ(,)。 |
| スパース入力時のキーと値の区切り文字 | キーとその値の間のデリミタ。デフォルト:コロン(:)。 |
| PMML を生成するかどうか | Predictive Model Markup Language(PMML)形式のモデルファイルを生成します。パイプラインのストレージパスが未設定の場合、プロンプト表示時に「今すぐ作成」をクリックします。 |
[チューニング] タブ
| パラメーター | 説明 |
|---|---|
| CPU コア数 | コンピューティングに使用する CPU コア数。デフォルト:自動設定。 |
| コアのメモリサイズ (MB) | CPU コアあたりのメモリ量(MB)。有効範囲:1~65536。デフォルト:自動設定。 |
方法 2:PAI コマンドを使用
以下のコマンドを「SQL スクリプト」コンポーネント内で実行します。
PAI -name NaiveBayes -project algo_public
-DinputTablePartitions="pt=20150501"
-DmodelName="xlab_m_NaiveBayes_23772"
-DlabelColName="poutcome"
-DfeatureColNames="age,previous,cons_conf_idx,euribor3m"
-DinputTableName="bank_data_partition";| パラメーター | 必須 | 説明 | デフォルト |
|---|---|---|---|
inputTableName | はい | 入力テーブル名。 | — |
inputTablePartitions | いいえ | トレーニングに使用するパーティション。 | すべてのパーティション |
modelName | はい | 出力モデル名。 | — |
labelColName | はい | ラベル列名。 | — |
featureColNames | いいえ | 特徴列名。 | ラベル列を除くすべての列 |
excludedColNames | いいえ | 除外する列。このパラメーターは「featureColNames」と同時に設定できません。 | — |
forceCategorical | いいえ | データ型に関係なくカテゴリとして扱う列。未設定の場合、BIGINT 型は連続として扱われます。 | INT は連続 |
coreNum | いいえ | CPU コア数。 | 自動設定 |
memSizePerCore | いいえ | CPU コアあたりのメモリ量(MB)。有効範囲:1~65536。 | 自動設定 |
サンプル
この例では、小規模データセットを用いてバイナリ分類器をトレーニングし、「多クラス分類評価」コンポーネントで予測精度を評価します。
ステップ 1:トレーニングおよびテストデータの準備
MaxCompute クライアントを使用して、以下のスキーマを持つ 2 つのテーブル —
train_dataおよびtest_data— を作成します。id bigint, y bigint, f0 double, f1 double, f2 double, f3 double, f4 double, f5 double, f6 double, f7 double設定手順については、「MaxCompute クライアント(odpscmd)」および「テーブルの作成」をご参照ください。
以下のデータを各テーブルにインポートします。インポート手順については、「テーブルへのデータのインポート」をご参照ください。
トレーニングデータ(train_data)
id y f0 f1 f2 f3 f4 f5 f6 f7 1 -1 -0.294118 0.487437 0.180328 -0.292929 -1 0.00149028 -0.53117 -0.0333333 2 +1 -0.882353 -0.145729 0.0819672 -0.414141 -1 -0.207153 -0.766866 -0.666667 3 -1 -0.0588235 0.839196 0.0491803 -1 -1 -0.305514 -0.492741 -0.633333 4 +1 -0.882353 -0.105528 0.0819672 -0.535354 -0.777778 -0.162444 -0.923997 -1 5 -1 -1 0.376884 -0.344262 -0.292929 -0.602837 0.28465 0.887276 -0.6 6 +1 -0.411765 0.165829 0.213115 -1 -1 -0.23696 -0.894962 -0.7 7 -1 -0.647059 -0.21608 -0.180328 -0.353535 -0.791962 -0.0760059 -0.854825 -0.833333 8 +1 0.176471 0.155779 -1 -1 -1 0.052161 -0.952178 -0.733333 9 -1 -0.764706 0.979899 0.147541 -0.0909091 0.283688 -0.0909091 -0.931682 0.0666667 10 -1 -0.0588235 0.256281 0.57377 -1 -1 -1 -0.868488 0.1 テストデータ(test_data)
id y f0 f1 f2 f3 f4 f5 f6 f7 1 +1 -0.882353 0.0854271 0.442623 -0.616162 -1 -0.19225 -0.725021 -0.9 2 +1 -0.294118 -0.0351759 -1 -1 -1 -0.293592 -0.904355 -0.766667 3 +1 -0.882353 0.246231 0.213115 -0.272727 -1 -0.171386 -0.981213 -0.7 4 -1 -0.176471 0.507538 0.278689 -0.414141 -0.702128 0.0491804 -0.475662 0.1 5 -1 -0.529412 0.839196 -1 -1 -1 -0.153502 -0.885568 -0.5 6 +1 -0.882353 0.246231 -0.0163934 -0.353535 -1 0.0670641 -0.627669 -1 7 -1 -0.882353 0.819095 0.278689 -0.151515 -0.307329 0.19225 0.00768574 -0.966667 8 +1 -0.882353 -0.0753769 0.0163934 -0.494949 -0.903073 -0.418778 -0.654996 -0.866667 9 +1 -1 0.527638 0.344262 -0.212121 -0.356974 0.23696 -0.836038 -0.8 10 +1 -0.882353 0.115578 0.0163934 -0.737374 -0.56974 -0.28465 -0.948762 -0.933333
ステップ 2:パイプラインの構築と実行
パイプラインキャンバス上に、以下のコンポーネントを追加します:2 つの「テーブルの読み込み」コンポーネント、1 つの「ナイーブベイズ」コンポーネント、1 つの「予測」コンポーネント、および 1 つの「多クラス分類評価」コンポーネント。
下図のようにコンポーネントを接続します。パイプラインの作成方法については、「アルゴリズムモデリング」をご参照ください。
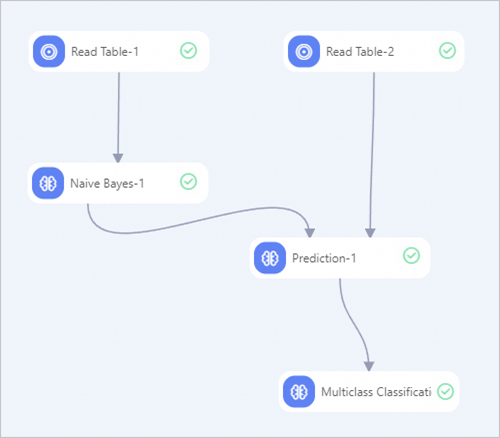
各コンポーネントを以下のように設定します。
テーブルの読み込み-1:「テーブルの選択」タブで、「テーブル名」を
train_dataに設定します。テーブルの読み込み-2:「テーブルの選択」タブで、「テーブル名」を
test_dataに設定します。ナイーブベイズ-1:「フィールド設定」タブで、「特徴列」を
f0, f1, f2, f3, f4, f5, f6, f7に、「ラベル列」をyに設定します。その他のパラメーターはすべてデフォルト値のままとします。予測-1:「フィールド設定」タブで、「予約列」を
id, yに設定します。その他のパラメーターはすべてデフォルト値のままとします。多クラス分類評価-1:「フィールド設定」タブで、「元の分類結果列」を
yに設定します。その他のパラメーターはすべてデフォルト値のままとします。
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。
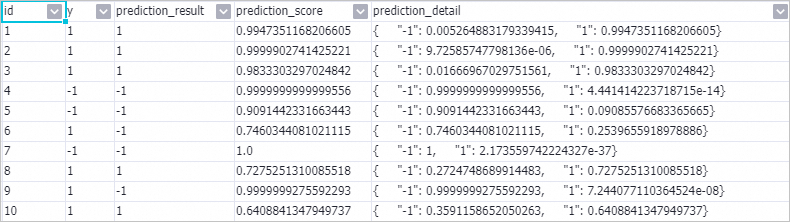
ステップ 3:予測結果の確認
パイプラインの実行が完了したら、「予測-1」を右クリックし、「データの表示」→「予測結果の出力」を選択します。
次のステップ
トレーニング済みモデルをオンラインサービスとしてデプロイするには、「オンラインサービスとしてモデルをデプロイ」をご参照ください。
Machine Learning Designer の概要および機能一覧については、「Machine Learning Designer の概要」をご参照ください。
その他のアルゴリズムコンポーネントについては、「すべてのコンポーネントの概要」をご参照ください。