線形モデルの特徴量重要度コンポーネントは、線形回帰や二項分類のロジスティック回帰などの線形モデルの特徴量重要度スコアを計算します。スパース形式と密形式の両方の入力データ形式をサポートしています。
このコンポーネントを使用して、モデルの予測に最も貢献する特徴量を特定します。これは、モデルのデバッグ、特徴量選択、モデルの動作に対する信頼の構築において重要なステップです。
制限事項
このコンポーネントは、MaxCompute コンピューティングリソース上でのみ実行されます。
前提条件
作業を開始する前に、以下が準備できていることを確認してください。
トレーニング済みの線形モデル (線形回帰または二項分類のロジスティック回帰)
特徴列とラベル列を含む MaxCompute の入力テーブル
コンポーネントの設定
以下のいずれかの方法でコンポーネントを設定します。
方法1:PAI コンソール (ビジュアルモデリング)
ビジュアルモデリングの [フィールド設定] タブと [チューニング] タブでパラメーターを設定します。
[フィールド設定] タブ
| パラメーター | 必須 | 説明 | デフォルト値 |
|---|---|---|---|
| 特徴列 | いいえ | 入力テーブルからトレーニングに使用する特徴列。 | ラベル列以外のすべての列 |
| ターゲット列 | はい | ラベル列です。[フィールドを選択] をクリックし、キーワードで列を検索して選択し、[OK] をクリックします。 | — |
| スパース形式のデータを入力 | いいえ | 入力データがスパース形式であるかどうかを指定します。 | — |
[チューニング] タブ
| パラメーター | 必須 | 説明 | デフォルト値 |
|---|---|---|---|
| コア数 | いいえ | コンピューティングに使用するコアの数。 | システムによって決定されます |
| コアごとのメモリサイズ | いいえ | 各コアに割り当てられるメモリ (MB)。 | システムによって決定されます |
方法2:PAI コマンド
PAI コマンドを使用してコンポーネントを実行します。SQL Script コンポーネントを使用して PAI コマンドを呼び出します。詳細については、「SQL スクリプト」をご参照ください。
PAI -name regression_feature_importance -project algo_public
-DmodelName=xlab_m_logisticregressi_20317_v0
-DoutputTableName=pai_temp_2252_20321_1
-DlabelColName=y
-DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
-DenableSparse=false -DinputTableName=pai_dense_10_9;| パラメーター | 必須 | 説明 | デフォルト値 |
|---|---|---|---|
inputTableName | はい | 入力テーブルの名前。 | なし |
outputTableName | はい | 出力テーブルの名前。 | なし |
labelColName | はい | 入力テーブルのラベル列。 | なし |
modelName | はい | 入力モデルの名前。 | なし |
featureColNames | いいえ | 入力テーブルの特徴列。 | ラベル列以外のすべての列 |
inputTablePartitions | いいえ | 入力テーブルから読み取るパーティション。 | テーブル全体 |
enableSparse | いいえ | 入力データがスパース形式であるかどうかを指定します。 | false |
itemDelimiter | いいえ | スパースデータにおけるキーと値のペアの区切り文字。 | スペース |
kvDelimiter | いいえ | スパースデータにおけるキーと値の区切り文字。 | コロン (:) |
lifecycle | いいえ | 出力テーブルのライフサイクル。 | 指定なし |
coreNum | いいえ | コア数。 | システムによって決定されます |
memSizePerCore | いいえ | コアごとのメモリサイズ。 | システムによって決定されます |
例
この例では、bank_data データセットを使用してロジスティック回帰モデルをトレーニングし、特徴量重要度スコアを計算します。
bank_dataという名前のテーブルを作成し、データをインポートします。詳細については、「テーブルの作成」および「テーブルへのデータのインポート」をご参照ください。次の SQL ステートメントを実行して、トレーニングデータを生成します。
CREATE TABLE IF NOT EXISTS pai_dense_10_9 AS SELECT age, campaign, pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, fixed_deposit FROM bank_data LIMIT 10;ビジュアルモデリングでパイプラインを構築して実行します。パイプラインの作成方法の詳細については、「アルゴリズムモデリング」をご参照ください。
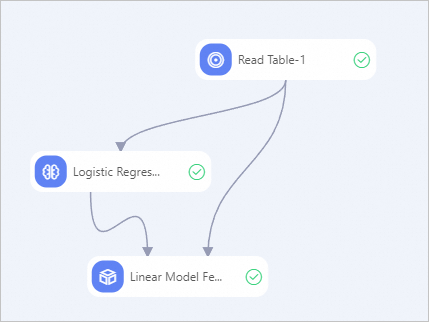
コンポーネントリストで、[テーブルの読み込み]、[多クラス分類用ロジスティック回帰]、および[線形モデルの特徴量の重要度]の3つのコンポーネントを検索し、キャンバス上にドラッグします。
上の図に示す順序でコンポーネントを接続します。
各コンポーネントを設定します。
[テーブル読み込み-1] をクリックします。[テーブルの選択] タブで、[テーブル名] を
bank_dataに設定します。[Logistic Regression for Multiclass Classification-1] をクリックします。[Fields Setting] タブで、[Training feature columns] を
age、campaign、pdays、previous、emp_var_rate、cons_price_idx、cons_conf_idx、euribor3m、およびnr_installedに設定します。[Target columns] をfixed_depositに設定します。[線形モデルの特徴量重要度-1] をクリックします。[フィールド設定] タブで、[ターゲット列] を
fixed_depositに設定します。
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。
パイプラインの実行が完了したら、[線形モデルの特徴量重要度-1] を右クリックし、[データを表示] > [モデル重要度テーブル] を選択します。
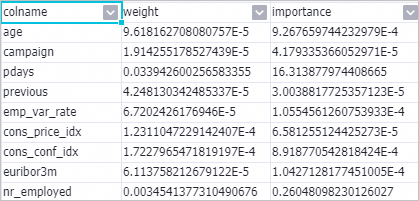 出力テーブルには次の 2 つの列が含まれます。
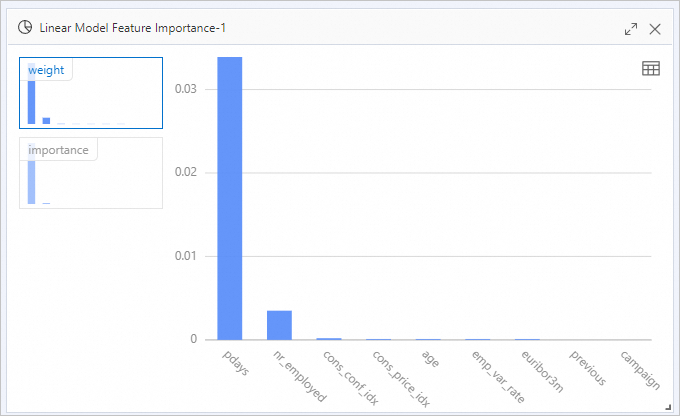
出力テーブルには次の 2 つの列が含まれます。列 計算式 測定内容 weightabs(w_)特徴量係数の絶対値 importanceabs(w_j) × STD(f_i)特徴量の標準偏差 (トレーニングデータの標準偏差) でスケーリングされた係数 [線形モデルの特徴量重要度-1] を右クリックし、[分析レポートの表示] を選択して、視覚化された重要度ランキングを確認します。
次のステップ
ビジュアルモデリングで利用可能なすべてのコンポーネントの概要については、「ビジュアルモデリングの概要」をご参照ください。
他のアルゴリズムコンポーネントについては、「コンポーネントリファレンス:全コンポーネントの概要」をご参照ください。