Deep Learning Containers (DLC) を使用すると、分散型またはシングルノードのトレーニングジョブを迅速に作成できます。Kubernetes 上に構築された DLC は、マシンを購入したり、ランタイム環境を手動で設定したりする必要がありません。ワークフローを変更することなく、すぐに DLC を使用できます。このトピックでは、MNIST 手書き認識の例を使用して、DLC を使用してシングルノード・シングル GPU トレーニングまたはマルチノード・マルチ GPU 分散トレーニングを実行する方法を説明します。
MNIST 手書き認識は、ディープラーニングにおける最も古典的な入門タスクの 1 つです。目標は、10 種類の手書き数字 (0 から 9) を認識する機械学習モデルを構築することです。

前提条件
ルートアカウントを使用して PAI をアクティブ化し、ワークスペースを作成します。PAI コンソールにログインします。左上のコーナーでリージョンを選択してサービスをアクティブ化します。次に、ワンクリック権限付与を使用してプロダクトをアクティブ化します。
課金の説明
このトピックの例では、パブリックリソースを使用して DLC ジョブを作成します。課金方法は従量課金です。詳細については、「Deep Learning Containers (DLC) の課金」をご参照ください。
シングルノード・シングル GPU トレーニング
データセットの作成
データセットには、モデルトレーニング用のコード、データ、および結果が保存されます。このトピックでは、Object Storage Service (OSS) データセットを例として使用します。
PAI コンソールの左側のナビゲーションウィンドウで、Datasets > Custom Dataset > Create datasets を選択します。
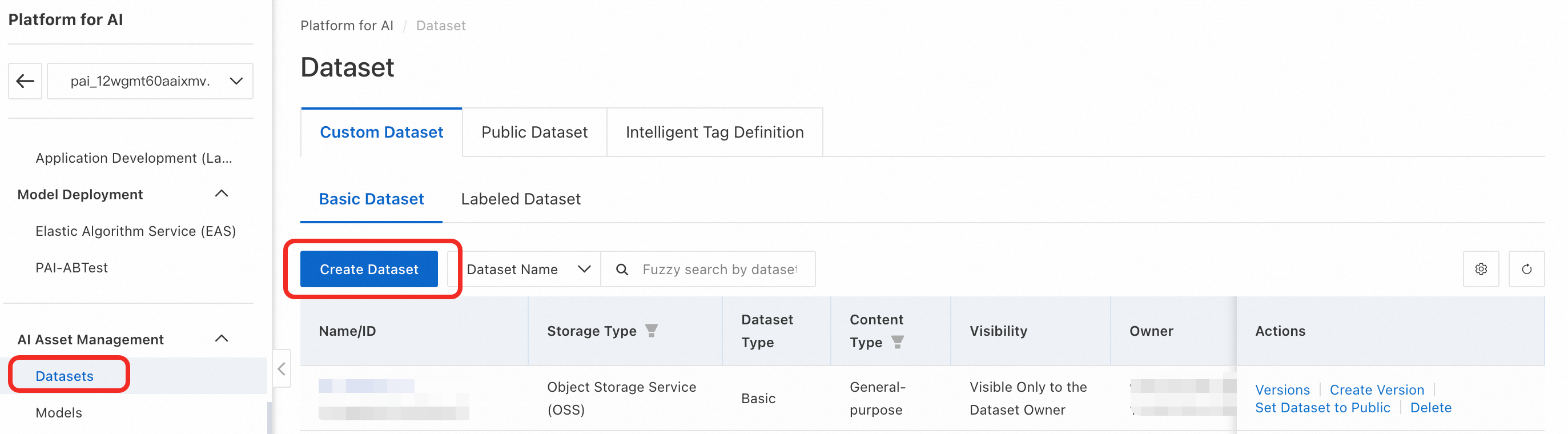
データセットのパラメーターを設定します。主要なパラメーターは以下のとおりです。その他のパラメーターはデフォルト値を使用できます。
Name:たとえば、
dataset_mnistStorage Type:OSS
OSS Path:
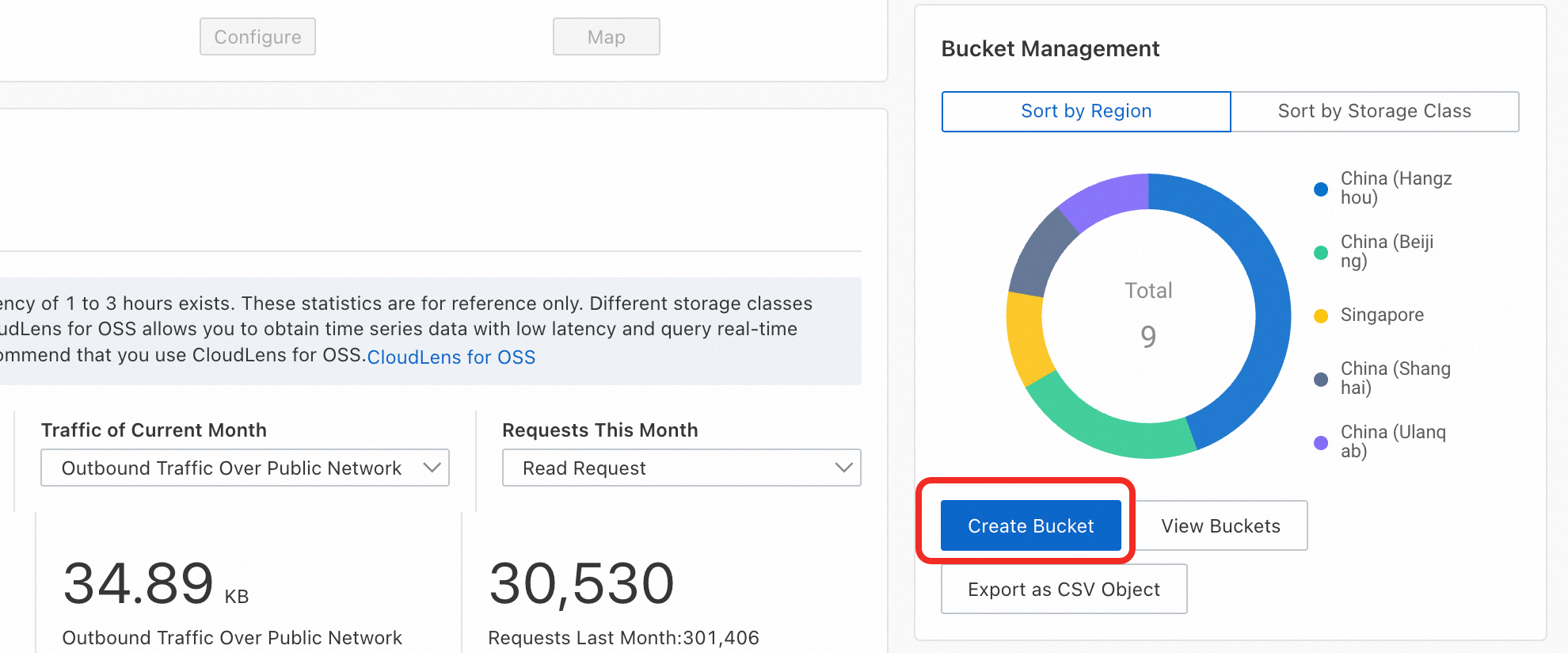
 アイコンをクリックし、バケットを選択して、
アイコンをクリックし、バケットを選択して、dlc_mnistなどの新しいフォルダを作成します。OSS をアクティブ化していない場合、または現在のリージョンで利用可能なバケットがない場合は、次の手順に従って OSS をアクティブ化し、バケットを作成します。
OSS コンソールにログオンします。バケットの作成 をクリックします。[バケット名] を入力します。Region を PAI と同じリージョンに設定します。他のパラメーターはデフォルト値のままにし、[作成] をクリックします。
[OK] をクリックしてデータセットを作成します。
トレーニングコードとデータをアップロードします。
このトピックで提供されているトレーニングコードをダウンロードします。mnist_train.py をクリックしてファイルをダウンロードします。プロセスを簡略化するため、このコードは実行時にデータセットの dataSet フォルダにトレーニングデータを自動的にダウンロードします。
独自のプロジェクトの場合は、事前にコードとトレーニングデータを PAI データセットにアップロードできます。
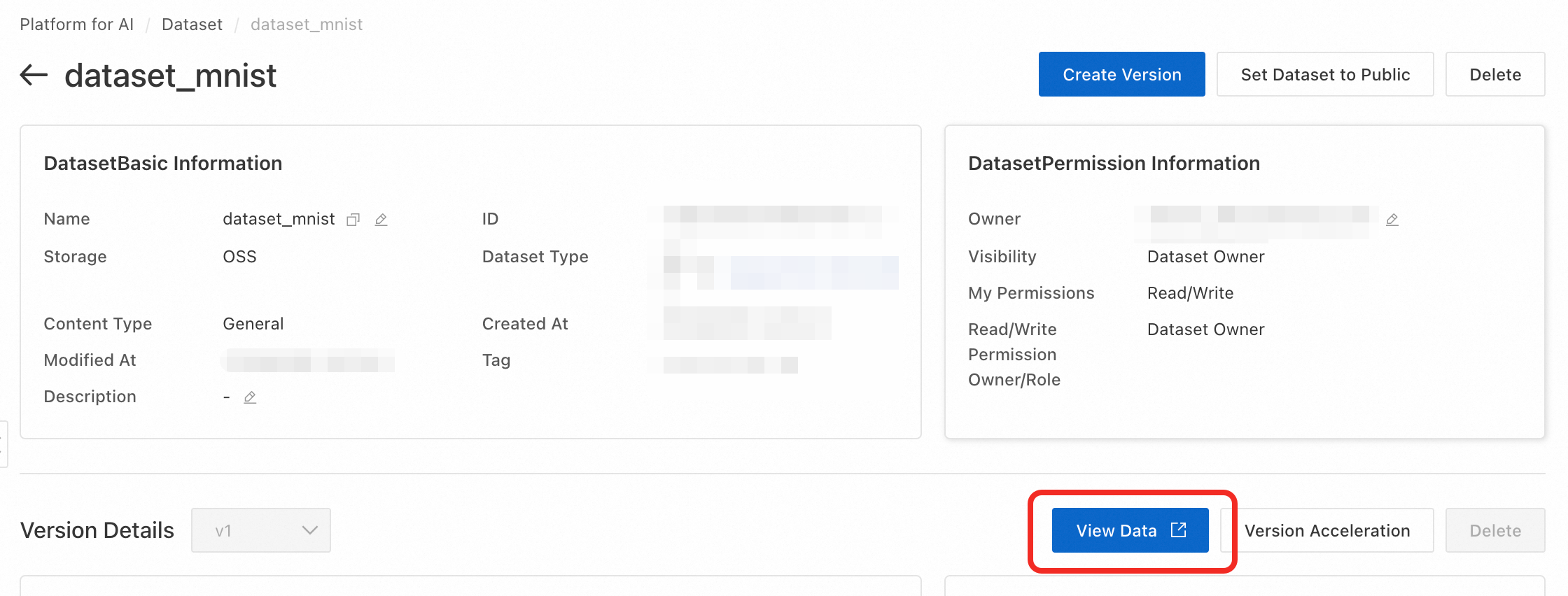
コードをアップロードするには、データセット詳細ページで View Data をクリックして OSS コンソールに移動します。次に、オブジェクト > ファイルの選択 > アップロード の順にクリックして、トレーニングコードをアップロードします。
DLC ジョブの作成
PAI コンソールの左側のナビゲーションウィンドウで、Deep Learning Containers (DLC) > Create Job を選択します。
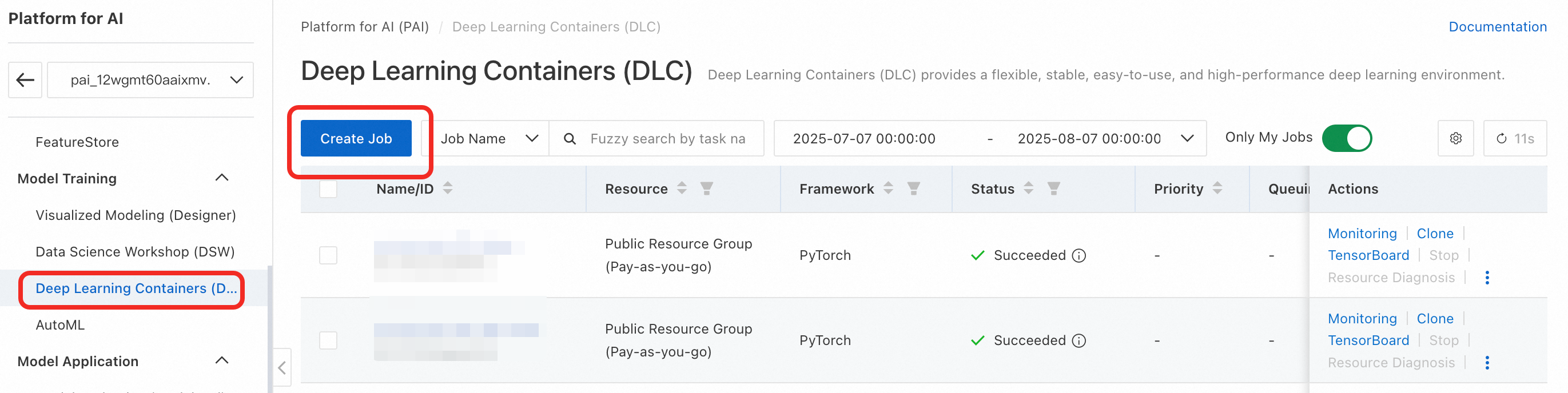
DLC ジョブのパラメーターを設定します。主要なパラメーターは以下のとおりです。その他のパラメーターはデフォルト値を使用できます。詳細については、「トレーニングジョブの作成」をご参照ください。
Image Configuration:Image Address を選択します。次に、Region に対応するレジストリアドレスを入力します。

リージョン
対応するレジストリアドレス
北京
dsw-registry-vpc.cn-beijing.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
上海
dsw-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
杭州
dsw-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
その他
「リージョン ID の照会」を行い、レジストリアドレスの <Region ID> を置き換えて完全な URL を取得します。
dsw-registry-vpc.<Region ID>.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
このランタイムイメージは、「Interactive Modelling (DSW) クイックスタート」の環境と互換性があることが確認されています。通常、PAI を使用してモデリングを行う場合、まず DSW で環境を検証してコードを開発し、その後 DLC を使用してトレーニングを行います。
Dataset Mount: Custom Dataset を選択して、前のステップで作成したデータセットを選択します。 デフォルトの Mount Path は
/mnt/dataです。Startup Command:
python /mnt/data/mnist_train.pyこの起動コマンドは、DSW またはローカルで実行する場合と同じです。ただし、
mnist_train.pyは/mnt/data/にマウントされているため、コードパスを/mnt/data/mnist_train.pyに変更する必要があります。Source: Public Resources を選択します。Resource Type には、
ecs.gn7i-c8g1.2xlargeを選択します。このインスタンスタイプが在庫切れの場合は、別の GPU アクセラレーションインスタンスタイプを選択できます。
OK をクリックしてジョブを作成します。 ジョブの実行には約 15 分かかります。 ジョブの実行中に、「ログ」をクリックしてトレーニングプロセスを表示できます。
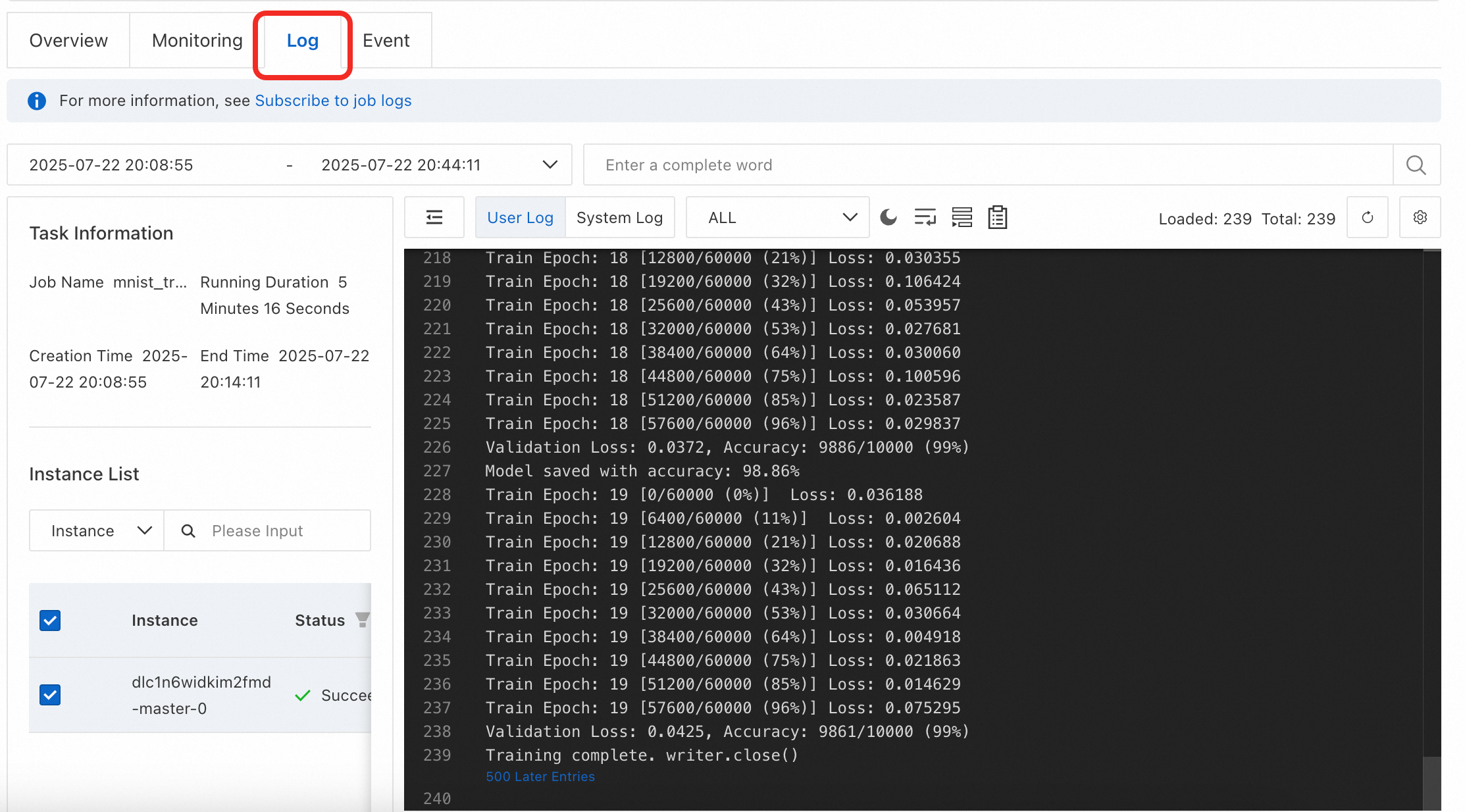
ジョブが完了すると、マウントされたデータセットの
outputパスに、最適なモデルのチェックポイントと TensorBoard のログが生成されます。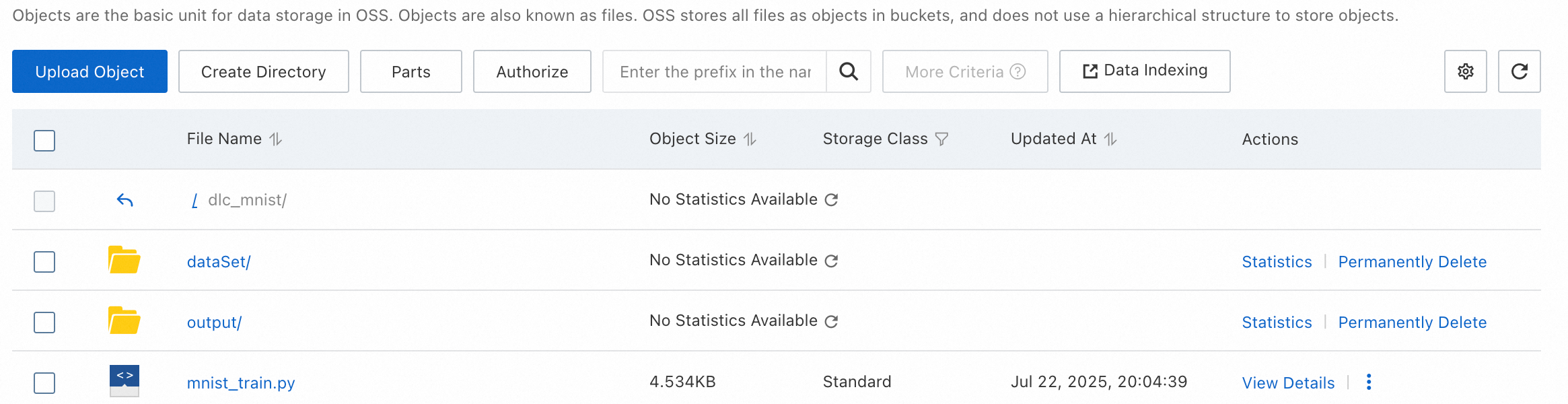
TensorBoard の表示 (オプション)
可視化ツール TensorBoard を使用して、損失曲線を表示し、トレーニングの詳細を理解できます。
DLC ジョブで TensorBoard を使用するには、データセットを設定する必要があります。
DLC ジョブの詳細ページで、ページ上部の Tensorboard > Create TensorBoard をクリックします。
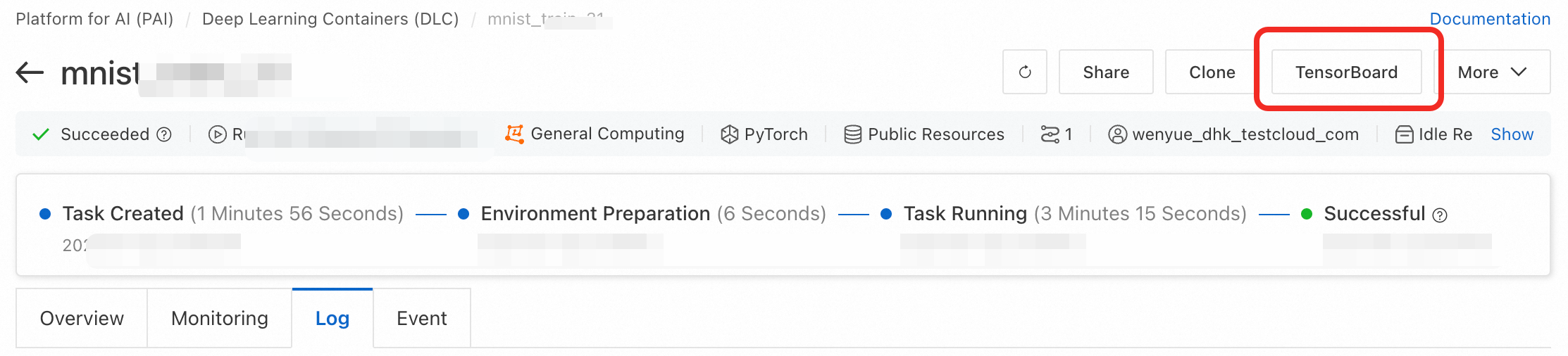
Configuration Type を By Task に設定します。Summary Path フィールドに、トレーニングコードでサマリーが保存されているパス
/mnt/data/output/runs/を入力します。OK をクリックして開始します。対応するコードスニペット:
writer = SummaryWriter('/mnt/data/output/runs/mnist_experiment')View TensorBoard をクリックすると、トレーニングデータセットの損失を反映する train_loss 曲線と、検証セットの損失を反映する validation_loss 曲線を表示できます。
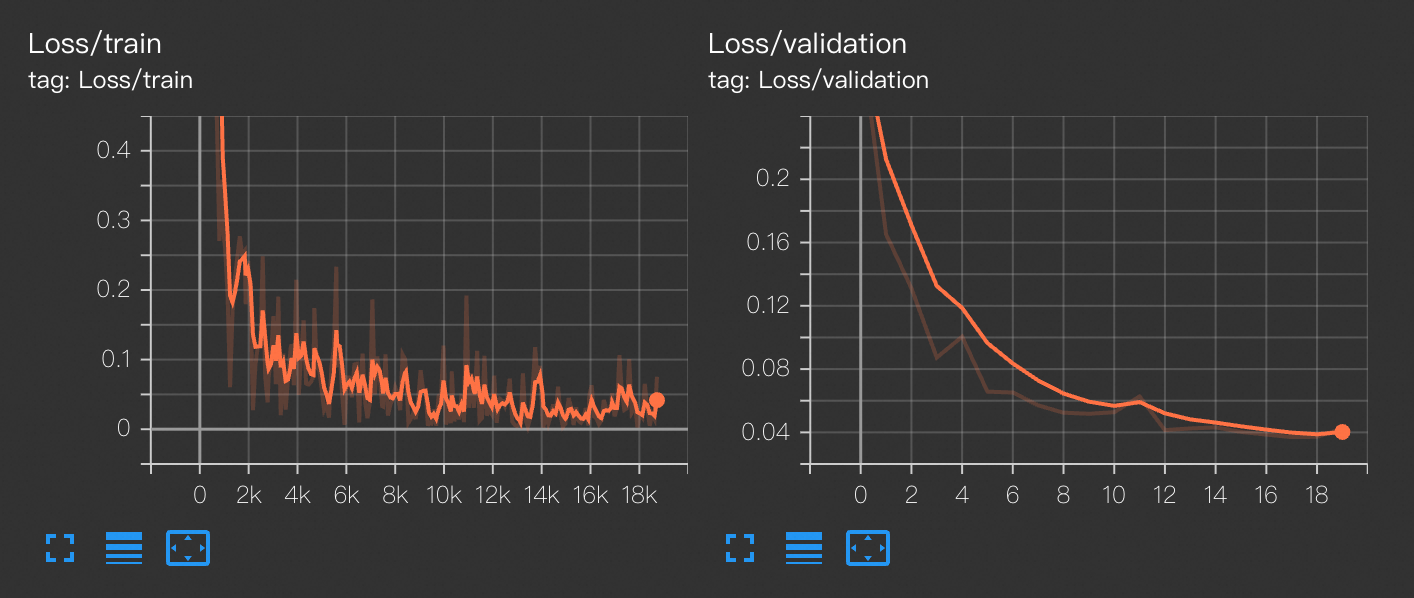
トレーニング済みモデルのデプロイ
詳細については、「EAS を使用してモデルをオンラインサービスとしてデプロイする」をご参照ください。
シングルノード・マルチ GPU またはマルチノード・マルチ GPU の分散トレーニング
単一の GPU の VRAM がトレーニングのニーズに対して不十分な場合、またはトレーニングプロセスを高速化したい場合は、シングルノード・マルチ GPU またはマルチノード・マルチ GPU の分散トレーニングジョブを作成できます。
このトピックでは、それぞれ 1 つの GPU を持つ 2 つのインスタンスの例を使用します。この例は、シングルノード・マルチ GPU またはマルチノード・マルチ GPU トレーニングの他の構成にも適用されます。
データセットの作成
「シングルノード・シングル GPU トレーニング」ですでにデータセットを作成している場合は、mnist_train_distributed.py コードをダウンロードしてアップロードするだけです。そうでない場合は、まず「データセットの作成」を行い、その後コードをアップロードする必要があります。
DLC ジョブの作成
PAI コンソールの左側のナビゲーションウィンドウで、Deep Learning Containers (DLC) > Create Job を選択します。
DLC ジョブのパラメーターを設定します。主要なパラメーターは以下のとおりです。その他のパラメーターはデフォルト値を使用できます。詳細については、「トレーニングジョブの作成」をご参照ください。
Image Configuration: Image Address を選択します。次に、お使いの Region に対応するレジストリアドレスを入力します。
リージョン
レジストリアドレス
北京
dsw-registry-vpc.cn-beijing.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
上海
dsw-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
杭州
dsw-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
その他
「リージョン ID の照会」を行い、レジストリアドレスの <Region ID> を置き換えて完全な URL を取得します。
dsw-registry-vpc.<Region ID>.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
このランタイムイメージは、「Interactive Modelling (DSW) クイックスタート」の環境と互換性があることが確認されています。通常、PAI を使用してモデリングを行う場合、まず DSW で環境を検証してコードを開発し、その後 DLC を使用してトレーニングを行います。
Dataset Mount:Custom Dataset を選択し、前のステップで作成したデータセットを選択します。 デフォルトの Mount Path は
/mnt/dataです。Startup Command:
torchrun --nproc_per_node=1 --nnodes=${WORLD_SIZE} --node_rank=${RANK} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} /mnt/data/mnist_train_distributed.pyDLC は、共通の環境変数 (たとえば
MASTER_ADDR、WORLD_SIZE$VARIABLE_NAMESource: Public Resources を選択します。Number of Nodes を 2 に設定します。Resource Type には、
ecs.gn7i-c8g1.2xlargeを選択します。このインスタンスタイプが在庫切れの場合は、別の GPU アクセラレーションインスタンスタイプを選択できます。
Confirm をクリックしてジョブを作成します。ジョブの実行には約 10 分かかります。実行中は、Overview ページで 2 つのインスタンスのトレーニングLogを表示できます。
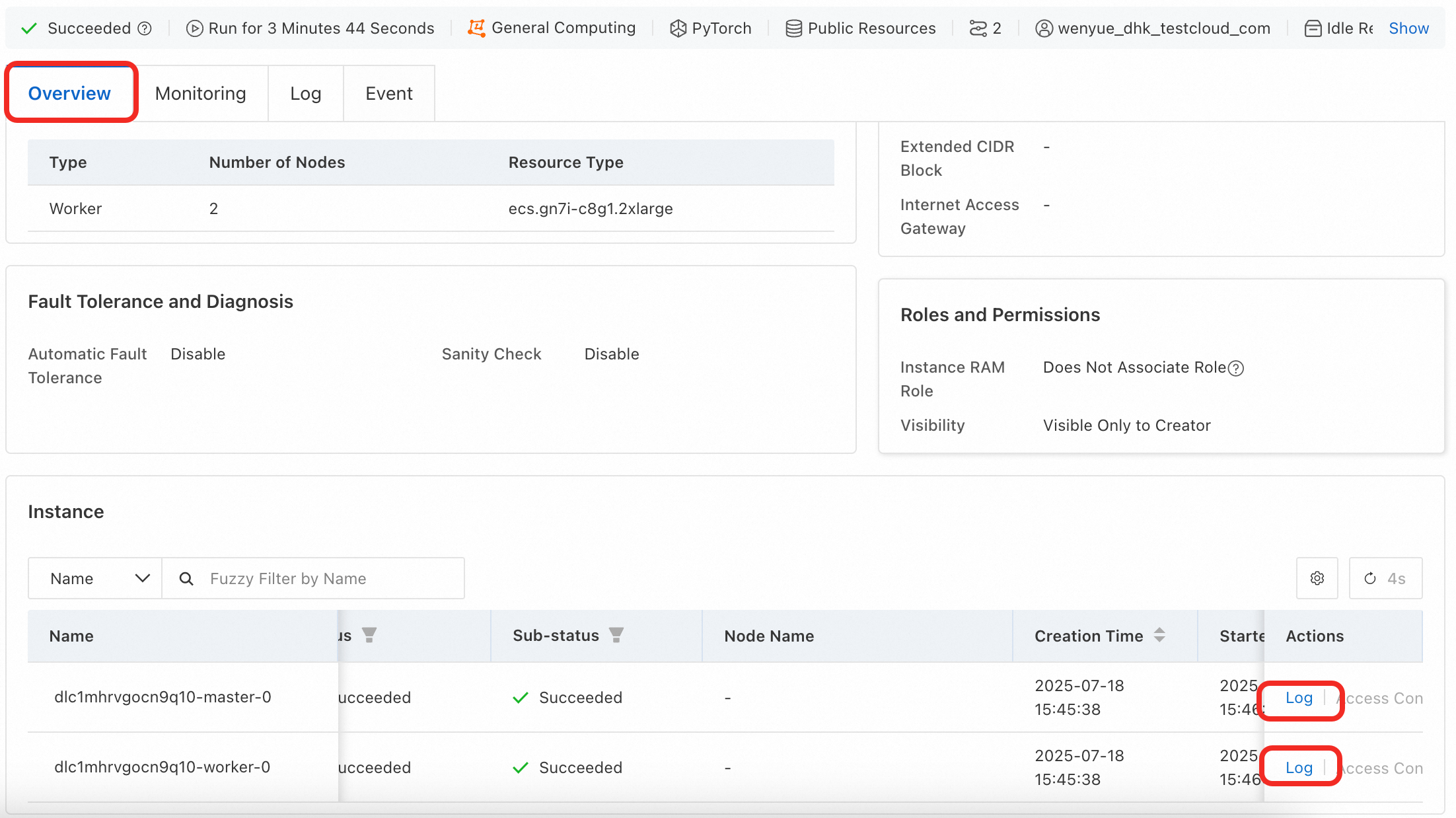
ジョブが完了すると、マウントされたデータセットの
output_distributedパスに、最適なモデルのチェックポイントと TensorBoard のログが生成されます。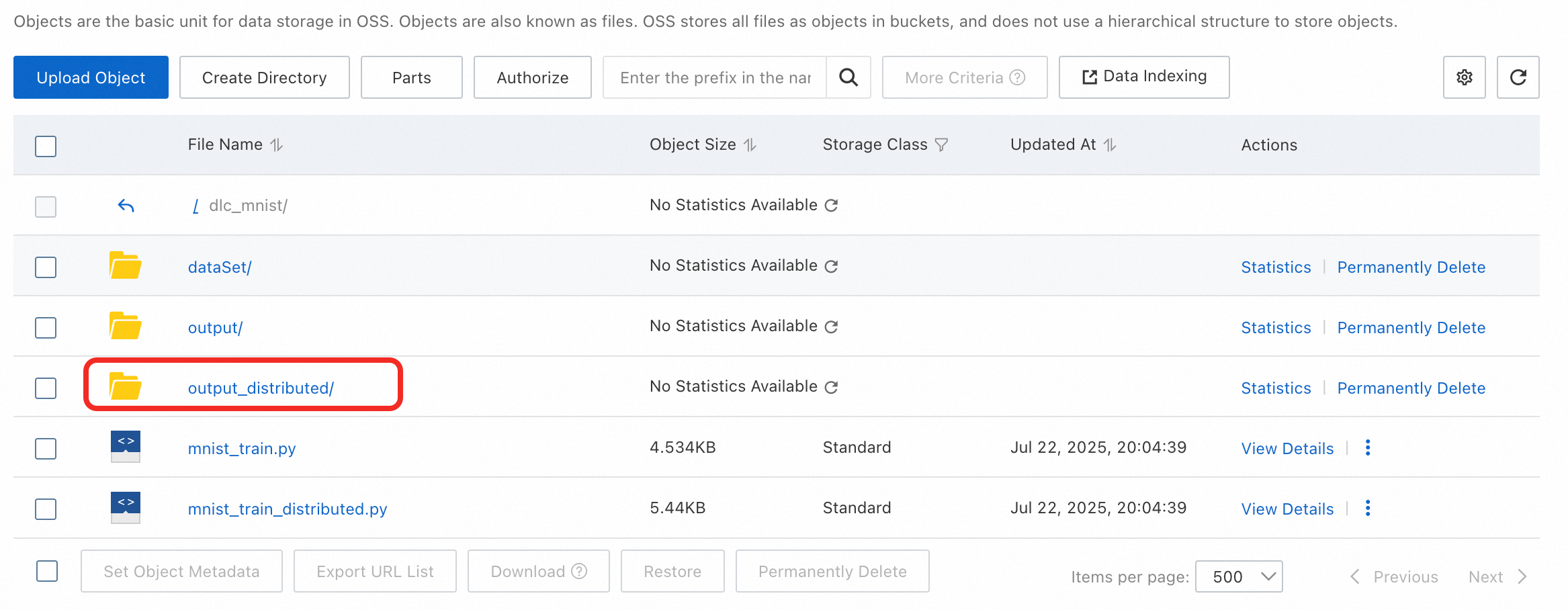
TensorBoard の表示 (オプション)
可視化ツール TensorBoard を使用して、損失曲線を表示し、トレーニングの詳細を理解できます。
DLC ジョブで TensorBoard を使用するには、データセットを設定する必要があります。
DLC ジョブの詳細ページで、ページ上部の TensorBoard > Create TensorBoard をクリックします。
Configuration Type を By Task に設定します。Summary Path フィールドに、トレーニングコードでサマリーが保存されているパス
/mnt/data/output_distributed/runsを入力します。OK をクリックして開始します。対応するコードスニペット:
writer = SummaryWriter('/mnt/data/output_distributed/runs/mnist_experiment')View TensorBoard をクリックすると、トレーニングデータセットの損失を反映する train_loss 曲線と、検証セットの損失を反映する validation_loss 曲線を表示できます。
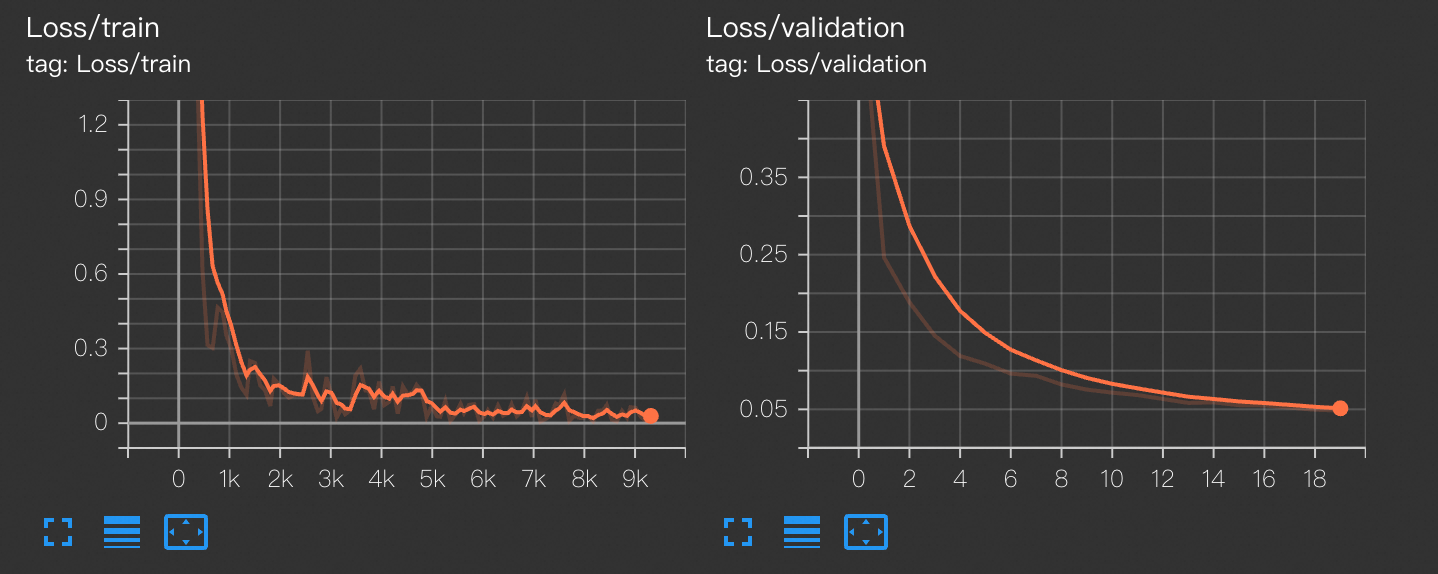
トレーニング済みモデルのデプロイ
詳細については、「EAS を使用してモデルをオンラインサービスとしてデプロイする」をご参照ください。
関連ドキュメント
詳細については、「Deep Learning Containers (DLC)」をご参照ください。