PAI 上の TensorFlow に関する一般的な質問と解決策を、データアクセス、モデルのエクスポート、トラブルシューティングのトピックを網羅して紹介します。
目次
複数の Python ファイルを参照するにはどうすればよいですか?
複数のファイルにまたがる関数を参照するには、すべての Python ファイル (例:test1.py と test2.py) を .tar.gz ファイルにパッケージ化してアップロードします。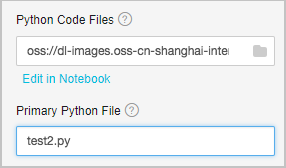 各項目は次のとおりです:
各項目は次のとおりです:
-
[Python コードファイル]: .tar.gz パッケージ。
-
[メイン Python ファイル]: メインのエントリファイル。
OSS にデータをアップロードするにはどうすればよいですか?
ディープラーニングのデータは OSS バケットに保存されます。 GPU クラスターと同じリージョンにバケットを作成すると、クラシックネットワークを使用でき、トラフィック料金がかかりません。その後、OSS コンソールからフォルダの作成、データの整理、ファイルのアップロードができます。
API または SDK を使用して OSS にデータをアップロードします (単純アップロード)。OSS は、ossutil や osscmd などのツールも提供しており、ファイルのアップロードとダウンロードが可能です (OSS の開発者ツール)。
アップロードツールには AccessKey ID と AccessKey シークレットが必要です。これらは Alibaba Cloud コンソールで作成または表示できます。
OSS からデータを読み取るにはどうすればよいですか?
Python はネイティブに OSS パスをサポートしていません。Open()、os.path.exist()、Scipy.misc.imread()、numpy.load() などの標準的なファイル操作は、OSS 上で直接実行することはできません。
PAI でデータを読み取るには、次のいずれかの方法を使用します。
-
単一の画像やテキストファイルの読み取りなど、単純な読み取り操作には
tf.gfile関数を使用します。tf.gfile.Copy(oldpath, newpath, overwrite=False) # ファイルをコピーします。 tf.gfile.DeleteRecursively(dirname) # ディレクトリ内のすべてのファイルを再帰的に削除します。 tf.gfile.Exists(filename) # ファイルが存在するかどうかを確認します。 tf.gfile.FastGFile(name, mode='r') # ファイルをブロックせずに読み取ります。 tf.gfile.GFile(name, mode='r') # ファイルを読み取ります。 tf.gfile.Glob(filename) # フォルダ内のすべてのファイルを一覧表示します。パターンをサポートしています。 tf.gfile.IsDirectory(dirname) # dirname がディレクトリかどうかを返します。 tf.gfile.ListDirectory(dirname) # dirname 配下のすべてのファイルを一覧表示します。 tf.gfile.MakeDirs(dirname) # dirname にフォルダを作成します。親ディレクトリが存在しない場合は自動的に作成されます。フォルダがすでに存在し、書き込み可能である場合、操作は成功します。 tf.gfile.MkDir(dirname) # dirname にフォルダを作成します。 tf.gfile.Remove(filename) # filename を削除します。 tf.gfile.Rename(oldname, newname, overwrite=False) # ファイル名を変更します。 tf.gfile.Stat(dirname) # ディレクトリの統計情報を返します。 tf.gfile.Walk(top, inOrder=True) # ディレクトリのファイルツリーを返します。 -
バッチ読み込みには、
tf.gfile.Glob、tf.gfile.FastGFile、tf.WholeFileReader()、およびtf.train.shuffle_batch()を使用します。まずファイルリストを取得し、次にバッチを作成します。
Designer では、-XXX 形式の tf.flags を使用して、読み取りディレクトリやコードファイルなどのパラメーターを渡します。ここで XXX は文字列です。
import tensorflow as tf
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_string('buckets', 'oss://{OSS Bucket}/', '学習画像が保存されているフォルダ')
tf.flags.DEFINE_string('batch_size', '15', 'バッチサイズ')
files = tf.gfile.Glob(os.path.join(FLAGS.buckets,'*.jpg')) # バケット内のすべての JPG ファイルのパスを一覧表示します。ファイルサイズに基づいてバッチ読み込み方法を選択します。
-
小さいファイルを読み取るには、
tf.gfile.FastGFile()を使用します。for path in files: file_content = tf.gfile.FastGFile(path, 'rb').read() # ファイルを読み取るには、必ず 'rb' を使用してください。そうしないと、エラーが発生する可能性があります。 image = tf.image.decode_jpeg(file_content, channels=3) # この例では JPG 画像を使用します。 -
大きいファイルを読み取るには、
tf.WholeFileReader()を使用します。reader = tf.WholeFileReader() # reader をインスタンス化します。 fileQueue = tf.train.string_input_producer(files) # reader 用のキューを作成します。 file_name, file_content = reader.read(fileQueue) # キューからファイルを読み取ります。 image_content = tf.image.decode_jpeg(file_content, channels=3) # 読み取った結果を画像にデコードします。 label = XXX # ラベルの処理は省略されています。 batch = tf.train.shuffle_batch([label, image_content], batch_size=FLAGS.batch_size, num_threads=4, capacity=1000 + 3 * FLAGS.batch_size, min_after_dequeue=1000) sess = tf.Session() # セッションを作成します。 tf.train.start_queue_runners(sess=sess) # キューを開始します。このコマンドを実行しないと、スレッドはブロックされたままになります。 labels, images = sess.run(batch) # 結果を取得します。コードのポイント:
-
tf.train.string_input_producer:ファイル名のリストをキューに変換します。キュー処理スレッドを開始するには、tf.train.start_queue_runnersを呼び出す必要があります。 -
tf.train.shuffle_batchのパラメーター:-
batch_size:バッチ操作ごとに返されるデータエントリの数。 -
num_threads:データをエンキューするために使用されるスレッドの数。一般的な値は 4 です。 -
capacity:最大キューサイズ。ランダムシャッフルの範囲を定義します。たとえば、10,000 エントリのデータセット内の 5,000 のバッファからシャッフルするには、capacityを 5000 に設定します。 -
min_after_dequeue:デキュー後に保持される要素の最小数。これにより、最小限のミキシングレベルが保証されます。[capacity] を超えることはできません。
-
-
OSS にデータを書き込むにはどうすればよいですか?
OSS にデータを書き込むには、次のいずれかの方法を使用します。これらの例では、出力は /model/example.txt に保存されます。
-
tf.gfile.FastGFile()を使用してデータを書き込む:tf.gfile.FastGFile(FLAGS.checkpointDir + 'example.txt', 'wb').write('hello world') -
tf.gfile.Copy()を使用してローカルファイルを OSS にコピーする:tf.gfile.Copy('./example.txt', FLAGS.checkpointDir + 'example.txt')
実行時に OOM エラーが発生するのはなぜですか?
メモリ使用量が 30 GB を超えると OOM が発生します。データセット全体をメモリに読み込む代わりに、gfile を使用して OSS からデータをストリーミングします。詳細については、「OSS からデータを読み取るにはどうすればよいですか?」をご参照ください。
TensorFlow のユースケースの例を教えてください。
楽曲制作: 楽曲制作のサンプルコード。
2 つの GPU が設定されている場合、model_average_iter_interval はどのような目的で使用されますか?
model_average_iter_interval がない場合、GPU は標準の Parallel-SGD を実行し、イテレーションごとに勾配の更新を交換します。1 より大きい値に設定すると、代わりに Model Average が使用されます。つまり、model_average_iter_interval イテレーションごとに両方の GPU でモデルパラメーターが平均化されます。
TensorFlow モデルを SavedModel としてエクスポートするにはどうすればよいですか?
SavedModel 形式
EAS の公式ビルド済みプロセッサを使用して TensorFlow モデルをオンラインサービスとしてデプロイするには、モデルを SavedModel 形式にエクスポートする必要があります。これは TensorFlow が推奨する公式形式です。ディレクトリ構造は次のとおりです:
assets/
variables/
variables.data-00000-of-00001
variables.index
saved_model.pb|saved_model.pbtxt各項目は次のとおりです:
-
assets:予測に必要な補助ファイル (語彙ファイルなど) を格納するオプションのフォルダ。 -
variables:tf.train.Saverによって保存された変数情報を格納します。 -
saved_model.pbまたはsaved_model.pbtxt:学習済みモデルのグラフ構造を含むMetaGraphDefと、予測の入力と出力を指定するSignatureDefを格納します。
SavedModel のエクスポート
TensorFlow ガイドの「保存と復元」では、SavedModel のエクスポートについて詳しく説明しています。単純なモデルの場合は、次の簡単な方法を使用します。
tf.saved_model.simple_save(
session,
"./savedmodel/",
inputs={"image": x}, ## x はモデルの入力変数です。
outputs={"scores": y} ## y はモデルの出力です。
)オンライン予測をリクエストする際は、モデルの signature_name を指定する必要があります。simple_save() でエクスポートされたモデルの場合、デフォルトの signature_name は [serving_default] です。
複雑なモデルの場合は、手動で SavedModel にエクスポートします。
print('Exporting trained model to', export_path) # 学習済みモデルを export_path にエクスポートします
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
tensor_info_x = tf.saved_model.utils.build_tensor_info(x)
tensor_info_y = tf.saved_model.utils.build_tensor_info(y)
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': tensor_info_x},
outputs={'scores': tensor_info_y},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
)
legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'predict_images': prediction_signature,
},
legacy_init_op=legacy_init_op
)
builder.save()
print('Done exporting!') # エクスポート完了各項目は次のとおりです:
-
export_pathは、モデルのエクスポート先のパスを指定します。 -
prediction_signature:モデルの入力と出力のSignatureDef(SignatureDef)。この例では、signature_nameはpredict_imagesです。 -
builder.add_meta_graph_and_variables:エクスポートパラメーターを指定します。
-
予測用にモデルをエクスポートする場合、タグを
tf.saved_model.tag_constants.SERVINGに設定してください。 -
詳細については、「TensorFlow SavedModel」をご参照ください。
Keras モデルの SavedModel への変換
Keras の model.save() は H5 形式でエクスポートします。オンライン予測のために SavedModel に変換するには、load_model() で H5 モデルを読み込み、再エクスポートします。
import tensorflow as tf
with tf.device("/cpu:0"):
model = tf.keras.models.load_model('./mnist.h5')
tf.saved_model.simple_save(
tf.keras.backend.get_session(),
"./h5_savedmodel/",
inputs={"image": model.input},
outputs={"scores": model.output}
)チェックポイントの SavedModel への変換
tf.train.Saver() で保存されたチェックポイントモデルは、オンライン予測のために SavedModel に変換する必要があります。saver.restore() でチェックポイントを読み込み、再エクスポートします。
import tensorflow as tf
# 変数定義 ...
saver = tf.train.Saver()
with tf.Session() as sess:
# チェックポイントファイルからモデルを復元します。
saver.restore(sess, "./lr_model/model.ckpt")
tensor_info_x = tf.saved_model.utils.build_tensor_info(x)
tensor_info_y = tf.saved_model.utils.build_tensor_info(y)
tf.saved_model.simple_save(
sess,
"./savedmodel/",
inputs={"image": tensor_info_x},
outputs={"scores": tensor_info_y}
)