このトピックでは、Deep Learning Containers (DLC) に関するよくある質問とその回答、トラブルシューティングのガイダンス、およびソリューションについて説明します。
Q:モデルのトレーニングが「SupportsDistributedTraining false, please set InstanceCount=1」というエラーで失敗する場合
原因:現在のトレーニングジョブは複数のインスタンスを使用するように構成されていますが、モデルが分散トレーニングをサポートしていません。
解決策:ノード数を 1 に設定します。
Q:モデルのトレーニングが「failed to compose dlc job specs, resource limiting triggered, you are trying to use more GPU resources than the threshold」というエラーで失敗する場合
トレーニングジョブが、同時に実行できる GPU の上限である 2 台を超えています。現在のジョブが完了するのを待ってから新しいジョブを開始するか、チケットを送信してクォータの引き上げをリクエストしてください。
Q:「exited with code 137」エラーが発生した場合の対処方法
「xxx exited with code 137」というエラーが発生した場合は、より大きなメモリサイズのインスタンスを使用するか、ワーカーの数を増やすか、コードでリクエストされるメモリ量を変更してください。

Linux では、エラーコード 137 は、プロセスが SIGKILL シグナルによって強制終了されたことを示します。最も一般的な原因はメモリ使用量が多く、メモリ不足 (OOM) エラーが発生することです。ジョブ詳細ページでワーカーのメモリ使用量を確認し、メモリ不足の原因を特定できます。その後、より大きなメモリサイズのインスタンスを使用するか、ワーカーの数を増やすか、コードでリクエストされるメモリ量を変更してください。
Q:DLC ジョブのステータスが「失敗」または「デキュー済み」になった場合の対処方法
DLC のタスク実行ステータスは、次の順序で発生します。
ジョブ タイプ | ステータス シーケンス | |
従量課金リソースを使用する DLC ジョブ | Lingjun AI Computing プリエンプティブルリソースを使用 |
|
Lingjun AI Computing または汎用パブリックリソースを使用 |
| |
サブスクリプションリソースを使用する DLC ジョブ |
| |
ジョブのステータスが [準備中] の場合はどうすればよいですか?
ジョブが長時間 [準備中] のままである場合、VPC を構成せずに分散トレーニングジョブに CPFS データセットを構成したことが原因である可能性があります。分散トレーニングジョブを再作成する必要があります。ジョブを再作成する際に、CPFS データセットと VPC を構成します。選択した VPC が CPFS ファイルシステムの VPC と同じであることを確認してください。詳細については、「トレーニングジョブの作成」をご参照ください。
ジョブのステータスが [失敗] の場合はどうすればよいですか?
ジョブ詳細ページで、ジョブステータスの横にある
 アイコンにカーソルを合わせるか、インスタンスの操作ログを表示して、失敗の原因を特定します。詳細については、「トレーニング詳細の表示」をご参照ください。
アイコンにカーソルを合わせるか、インスタンスの操作ログを表示して、失敗の原因を特定します。詳細については、「トレーニング詳細の表示」をご参照ください。
Q:パブリックリソースを使用するジョブを、後で専用リソースを使用するように変更できますか?
使用するリソースを変更するには、ジョブを再作成する必要があります。元のジョブの [操作] 列で [クローン] をクリックして、新しいジョブを作成します。新しいジョブは元のジョブの構成を再利用するため、同じパラメーターを再入力する必要はありません。課金の詳細については、「DLC の課金」をご参照ください。
Q:DLC で複数のマシンと複数の GPU を設定する方法
DLC ジョブを作成する際に、次の起動コマンドを構成できます。詳細については、「トレーニングジョブの作成」をご参照ください。
python -m torch.distributed.launch \ --nproc_per_node=2 \ --master_addr=${MASTER_ADDR} \ --master_port=${MASTER_PORT} \ --nnodes=${WORLD_SIZE} \ --node_rank=${RANK} \ train.py --epochs=100Q:PAI-DLC プラットフォームでトレーニングしたモデルをローカルマシンにダウンロードする方法
DLC ジョブを送信する際に、必要なデータセットを関連付けることができます。次に、起動コマンドを構成して、トレーニング結果をマウントされたデータセットディレクトリに出力します。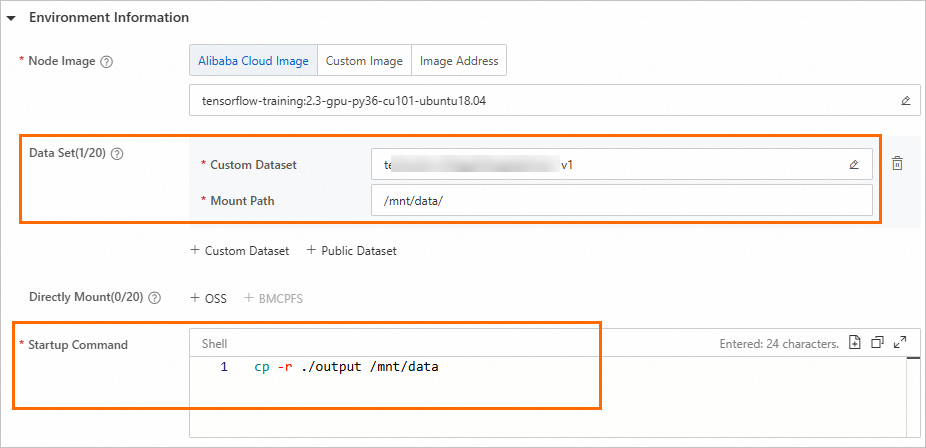
トレーニングが完了すると、生成されたモデルファイルは自動的にマウントされたデータセットディレクトリに保存されます。その後、マウントされたデータセットの対応するファイルシステムにアクセスし、モデルファイルをローカルマシンにダウンロードできます。
DLC ジョブを送信する際にデータセットを関連付ける方法の詳細については、「コンソールを使用したジョブの作成」をご参照ください。
Object Storage Service (OSS) ファイルシステムからローカルマシンにファイルをダウンロードする方法の詳細については、「コンソールを使用したクイックスタート」をご参照ください。
NAS ファイルシステムからローカルマシンにファイルをダウンロードする方法の詳細については、「Function Compute でのファイルシステムのマウント」をご参照ください。
Q:DLC で Docker イメージを使用する方法
Docker イメージを使用して DLC ジョブを作成する:Docker イメージを Alibaba Cloud Container Registry (ACR) にプッシュします。次に、それをカスタムイメージとして PAI ワークスペースに追加します。その後、DLC ジョブを作成する際にそのイメージを選択してインスタンスを起動できます。
Docker イメージを ACR にプッシュするには、「Personal Edition のインスタンスを使用したイメージのプッシュとプル」をご参照ください。
PAI カスタムイメージを追加するには、「カスタムイメージ」をご参照ください。
DLC コンテナーに Docker をインストールして使用する:DLC ジョブはコンテナー内で実行されます。そのため、DLC コンテナー内に Docker をインストールして使用することはできません。
Q:完了したノードを他の DLC ジョブが使用できるように解放するように DLC ジョブを構成する方法
問題の説明:
DLC ジョブがマルチワーカー分散トレーニングタスクを開始すると、一部のワーカーが早期に終了し、正常に終了することがあります。これは、データスキューなどの要因によって発生する可能性があります。ただし、デフォルトの構成では、これらの完了したワーカーはスケジュールされたノードを占有し続けます。
解決策: 設定するのは PAI-DLC の高度なパラメーター ReleaseResourcePolicyです。デフォルトでは、このパラメーターは設定されておらず、計算リソースはジョブ全体が完了した後にのみ解放されます。これを pod-exit に設定すると、worker が終了するとすぐに計算リソースが解放されます。
Q:DLC ジョブで「OSError: [Errno 116] Stale file handle」エラーが報告される理由
問題の説明:
複数のワーカーが PyTorch の torch.compile を実行して AOT (Ahead-Of-Time) コンパイルを行う際に、「OSError: [Errno 116] Stale file handle」エラーで失敗します。この失敗は、キャッシュファイルの読み取りができないことが原因です。
トラブルシューティング:
このエラーは通常、ネットワークファイルシステム (NFS) 環境で発生します。これは、サーバー上で削除または移動されたファイルのファイルハンドルをプロセスが保持している場合にトリガーされます。クライアントが無効なハンドルを使用してファイルにアクセスしようとすると、ハンドルがステイルになります。
原因:
根本的な原因は、PyTorch の AOT コンパイルメカニズムが、最適化された計算グラフをファイルシステムにキャッシュすることです。デフォルトでは、キャッシュは通常ローカルの tmpfs である /tmp に保存されます。ただし、クラスターコンピューティングなどの環境では、キャッシュが NFS 経由でマウントされた CPFS 分散ファイルシステムに保存される場合があります。NFS はファイル削除操作に敏感です。ステイルファイルハンドルは、いくつかの条件下でトリガーされる可能性があります。たとえば、PyTorch が古いキャッシュファイルを自動的にクリーンアップしたり、別のプロセスがキャッシュディレクトリを削除してファイルが削除されたりすることがあります。このエラーは、クライアントが古いハンドルを保持している間に NFS サーバー上でファイルが移動、削除、または権限が変更された場合にも発生する可能性があります。NFS クライアントはデフォルトでファイル属性をキャッシュするため、サーバーで行われた変更を検出できない場合があります。この問題は、いくつかの環境要因によって悪化します。CPFS は NFS に基づいており、特に一時キャッシュファイルなどのライフサイクルの短いファイルの場合、高同時アクセス中にステイルファイルハンドルエラーが発生しやすくなります。キャッシュの読み取り、書き込み、またはクリーンアップを同時に行う複数のワーカーからの同時アクセスも、競合状態を引き起こす可能性があります。
解決策:
主な解決策:環境変数 TORCHINDUCTOR_CACHE_DIR=/dev/shm/torch_cache を設定して、キャッシュがローカルの tmpfs を使用するように強制します。
代替ソリューション:
Torch の公式ドキュメントに従って Redis を共有キャッシュとして使用します。これには、Redis サービスをセットアップする必要があります。
CPFS の NFS 構成を確認します。`noac` マウントオプションは問題を軽減する可能性がありますが、パフォーマンスに影響を与える可能性があります。
TORCHINDUCTOR_CACHE_DIR="" を設定してキャッシュを無効にします。ただし、これによりコンパイルのパフォーマンスが犠牲になります。