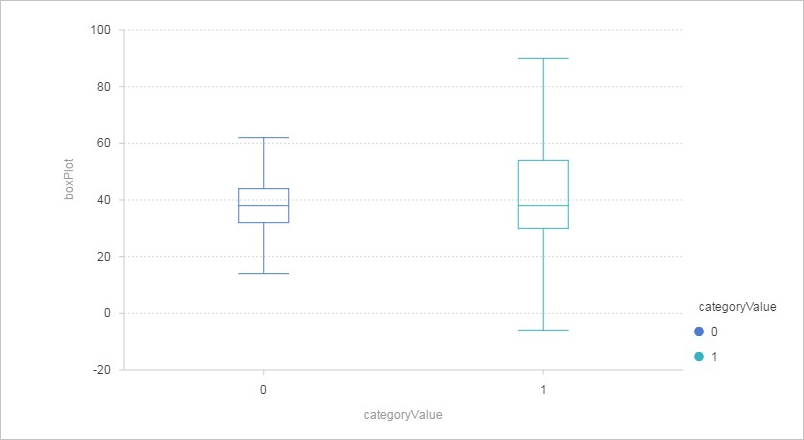
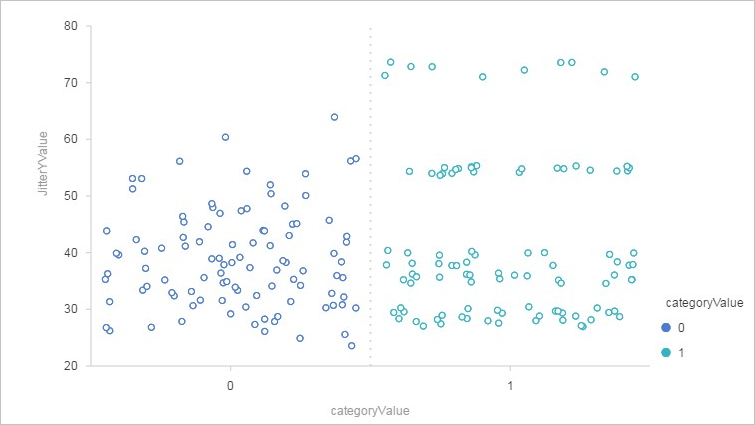
ビジュアルモデリングの箱ひげ図コンポーネントは、データセットの統計分布を可視化します。これを使用して、連続特徴量全体に値がどのように分散しているかを調査し、カテゴリカル特徴量によって定義されたグループ間で分布を比較できます。
制限事項
このコンポーネントの可視化されたレポートは、Machine Learning Studio でのみ利用可能です。
コンポーネントの構成
方法 1: コンソールを使用
ビジュアルモデリングのパイプライン構成ページで、[フィールド設定] タブの下で、以下のパラメーターを設定します。
| パラメーター | 説明 |
|---|---|
| 連続特徴量 | 分析する連続特徴量を含む列。 |
| カテゴリカル特徴量 | カテゴリカル特徴量を含む列。この列の一意の値ごとに個別の箱ひげ図グループが生成され、カテゴリ間の分布を比較できます。 |
| 層化サンプル | 採用された層化サンプルの数。 |
注: Machine Learning Studio では、各パラメーターに対して 1 つのフィールドのみを選択できます。ビジュアルモデリングでは、複数のフィールドを選択できます。
方法 2: PAI コマンドを使用
SQL Script コンポーネントを使用して、次の PAI コマンドを実行します。
PAI -name box_plot -project algo_public
-DinputTable="boxplot"
-DcontinueCols="age"
-DcategoryCol="y"
-DoutputTable="pai_temp_6075_97181_1"
-DsampleSize="1000"
-Dlifecycle="7";| パラメーター | 必須 | 説明 | デフォルト |
|---|---|---|---|
inputTable | はい | 入力テーブルの名前。 | N/A |
inputTablePartitions | いいえ | 入力テーブルから読み取るパーティション。サポートされているフォーマット: 単一パーティションの場合は partition_name=value、多層パーティションの場合は name1=value1/name2=value2。複数のパーティションを指定するには、コンマ (,) で区切ります。 | N/A |
outputTable | はい | 箱ひげ図とサンプルを格納する出力テーブルの名前。 | N/A |
continueCols | はい | 連続特徴量を含む列。 | N/A |
categoryCol | はい | カテゴリカル特徴量を含む列。一意の値ごとに個別の箱ひげ図グループが生成されます。 | N/A |
sampleSize | いいえ | 攪乱点 (disturbance points) のレンダリングのために層ごとにサンプリングされるデータポイントの数。 | 1000 |
lifecycle | いいえ | 出力テーブルのライフサイクル。単位: 日。 | 28 |
coreNum | いいえ | 計算に割り当てられるコアの数。正の整数である必要があります。 | 自動的に割り当てられます |
memSizePerCore | いいえ | コアあたりのメモリサイズ。有効な値: 1~65536。単位: MB。 | 自動的に割り当てられます |
例
入力データ
CREATE TABLE boxplot AS SELECT age, y FROM bank_data LIMIT 100;入力テーブルには、age (連続特徴量) と y (カテゴリカル特徴量) の 2 つの列があります。
| age | y |
|---|---|
| 50 | 0 |
| 53 | 0 |
| 28 | 1 |
| 39 | 0 |
| 55 | 1 |
パラメーター設定
age を連続特徴量列として、y をカテゴリカル特徴量列として設定します。他のすべてのパラメーターのデフォルト値は保持します。
出力
出力を表示するには、[ボックスプロット] を右クリックし、[データの表示] > [出力ポート] を選択します。
出力テーブルには次の列が含まれます。
| 列 | 説明 |
|---|---|
percent_points | 計算されたパーセンタイル値。 |
percent_count | 各間隔のデータエントリ数。間隔はパーセンタイルで分割されます。 |
sample_list | 各層から選択されたサンプル。サンプリングレートは次のように計算されます: サンプリングレート = 層化サンプルの数 / データエントリの総数。サンプリングレートが低すぎ、かつ、いずれかの層のサンプル数にサンプリングレートを乗じた値が 10 未満の場合、サンプリングレートは再計算されます。 |
コンポーネントは 2 つの可視化を生成します。