このトピックでは、DLC が提供する AIMaster ベースのフォールトトレランスモニタリング機能の使用方法について説明します。
背景情報
ディープラーニングは広く利用されています。モデルおよびデータセットが大規模化するにつれて、分散トレーニングが一般的な手法となっています。しかし、ジョブインスタンス数が増加すると、ソフトウェアおよびハードウェアの例外が発生する可能性も高まり、その結果としてジョブが失敗するリスクがあります。
大規模な分散ディープラーニングジョブを安定的に実行するために、DLC は AIMaster ベースのフォールトトレランスモニタリング機能を提供しています。AIMaster はジョブレベルのコンポーネントであり、有効化すると他のジョブインスタンスとともに AIMaster インスタンスが実行され、ジョブのモニタリング、フォールトトレランス評価、リソース制御を実施します。
制限事項
AIMaster は現在、以下のフレームワークをサポートしています: PyTorch、MPI、TensorFlow、ElasticBatch。
ステップ 1: フォールトトレランスパラメーターの構成
このセクションでは、フォールトトレランスモニタリング機能に関するすべてのパラメーターについて説明します。設定計画の参考として、サンプル構成をご利用ください。この機能を有効化する際には、Other Cofiguration セクションでこれらのパラメーターを指定できます。
パラメーター
カテゴリ | 機能 | パラメーター | 説明 | デフォルト値 |
一般設定 | ジョブ実行モード | --job-execution-mode | ジョブの実行モードを指定します。有効値:
リトライ可能なエラーが発生した場合のフォールトトレランス動作は、ジョブタイプによって異なります。
| Sync |
ジョブ再起動設定 | --enable-job-restart | フォールトトレランス条件を満たすか、ランタイム例外が発生した場合にジョブを再起動するかどうかを指定します。有効値:
| False | |
--max-num-of-job-restart | ジョブが再起動できる最大回数を指定します。この回数を超えると、ジョブは失敗とマークされます。 | 3 | ||
ランタイム設定 説明 インスタンスが失敗していないシナリオに適用されます。 | ジョブハング検出 | --enable-job-hang-detection | 実行中のジョブに対してハング検出を有効にするかどうかを指定します。この機能は同期ジョブでのみサポートされます。有効値:
| False |
--job-hang-interval | ジョブがハングと見なされるまでの非アクティブ状態の持続時間を秒単位で指定します。値は正の整数である必要があります。 非アクティブ時間がこの値を超えると、ジョブは異常とマークされ、再起動がトリガーされます。 | 1800 | ||
| C4D (Calibrating Collective Communication over Converged ethernet - Diagnosis) 検出を有効にするかどうかを指定します。この機能により、ジョブのハングを引き起こす遅延ノードや障害ノードを迅速に診断・特定できます。 説明 このパラメーターは、 | False | ||
ジョブ終了時のハング検出 | --enable-job-exit-hang-detection | ジョブ終了時にハング検出を有効にするかどうかを指定します。この機能は同期ジョブでのみサポートされます。有効値:
| False | |
--job-exit-hang-interval | ジョブの終了処理中に非アクティブ状態が許容される時間を秒単位で指定します。値は正の整数である必要があります。 終了時の非アクティブ時間がこの値を超えると、ジョブは異常とマークされ、再起動がトリガーされます。 | 600 | ||
フォールトトレランス設定 説明 インスタンスが失敗したシナリオに適用されます。 | フォールトトレランスポリシー | --fault-tolerant-policy | フォールトトレランスポリシーを指定します。有効値:
| ExitCodeAndErrorMsg |
同一エラーの最大発生回数 | --max-num-of-same-error | 単一インスタンスで同一エラーが発生できる最大回数を指定します。 エラー回数がこの値を超えると、ジョブは失敗とマークされます。 | 10 | |
最大許容失敗率 | --max-tolerated-failure-rate | 最大許容失敗率を設定します。失敗したインスタンスの割合がこの値を超えると、ジョブは失敗とマークされます。 デフォルト値 -1 は、この機能が無効であることを示します。例: このパラメーターを 0.3 に設定すると、ワーカーインスタンスの 30% を超えるインスタンスが失敗した場合、ジョブは失敗とマークされます。 | -1 |
サンプル構成
以下の例は、さまざまなトレーニングジョブ向けの一般的なパラメーター構成を示しています。
同期トレーニングジョブ(PyTorch ジョブで一般的)
インスタンスで例外が発生し、フォールトトレランス条件を満たす場合、ジョブが再起動されます。
--job-execution-mode=Sync --enable-job-restart=True --max-num-of-job-restart=3 --fault-tolerant-policy=ExitCodeAndErrorMsg非同期トレーニングジョブ(TensorFlow ジョブで一般的)
リトライ可能なエラーが発生した場合、失敗したワーカーインスタンスのみが再起動されます。デフォルトでは、PS または Chief インスタンスが失敗してもジョブは再起動されません。--enable-job-restart を True に設定することで、ジョブの再起動を有効化できます。
--job-execution-mode=Async --fault-tolerant-policy=OnFailureオフライン推論ジョブ(ElasticBatch ジョブで一般的)
インスタンスは独立しており、非同期ジョブと同様です。インスタンスが失敗した場合、そのインスタンスのみが再起動されます。
--job-execution-mode=Async --fault-tolerant-policy=OnFailure
ステップ 2: フォールトトレランスモニタリングの有効化
トレーニングジョブを送信する際に、DLC コンソールまたは SDK を使用して、フォールトトレランスモニタリング機能を有効にできます。
コンソールで有効化する
コンソールで DLC トレーニングジョブを送信する際に、Automatic Fault Tolerance スイッチを Fault Tolerance and Diagnosis セクションでオンにして、他のパラメーターを設定できます。詳細については、「トレーニングジョブを作成する」をご参照ください。この機能を有効にすると、AIMaster ロールが開始され、ジョブのライフサイクル全体をモニターし、エラーが発生した際にフォールトトレランス操作を実行します。

以下の項目は設定内容を説明しています。
Other Cofiguration テキストボックスで他のパラメーターを指定できます。パラメーターの詳細については、「ステップ 1: フォールトトレランスパラメーターの構成」をご参照ください。
ハング検出 を有効化した後、C4D Detection を有効化できます。C4D (Calibrating Collective Communication over Converged ethernet - Diagnosis) は、Alibaba Cloud が開発した独自の診断ツールであり、大規模モデルトレーニングジョブにおけるパフォーマンスの低下やハングなどの問題を特定するために使用されます。詳細については、「C4D の使用」をご参照ください。
説明C4D は Alibaba Cloud が開発した高性能集団通信ライブラリである ACCL に依存しています。ACCL がインストールされていることを確認してください。詳細については、「ACCL: Alibaba Cloud 高性能集団通信ライブラリ」をご参照ください。
現時点で、C4D 検出機能は Lingjun AI Computing Service 上で実行される DLC job でのみ使用できます。
ハング検出 を有効化した後、呼び出しスタックスナップショット分析ツールを使用して、ジョブがハングしている具体的なコード行を特定できます。これには、ハング検出しきい値の専用構成が必要です。詳細については、「呼び出しスタックスナップショット分析ツールの使用」をご参照ください。
DLC SDK の使用を有効化する
Go SDK を使用する
Go SDK を使用してジョブを送信する際に、フォールトトレランスモニタリング機能を有効化します。
createJobRequest := &client.CreateJobRequest{} settings := &client.JobSettings{ EnableErrorMonitoringInAIMaster: tea.Bool(true), ErrorMonitoringArgs: tea.String("--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=3600"), } createJobRequest.SetSettings(settings)パラメーター:
EnableErrorMonitoringInAIMaster: フォールトトレランスモニタリング機能を有効にするかどうかを指定します。
ErrorMonitoringArgs: フォールトトレランスモニタリングの他のパラメーターを指定します。
Python SDK を使用する
Python SDK を使用してジョブを送信する際に、フォールトトレランスモニタリング機能を有効化します。
from alibabacloud_pai_dlc20201203.models import CreateJobRequest, JobSettings settings = JobSettings( enable_error_monitoring_in_aimaster = True, error_monitoring_args = "--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=30" ) create_job_req = CreateJobRequest( ... settings = settings, )パラメーター:
enable_error_monitoring_in_aimaster: フォールトトレランスモニタリング機能を有効にするかどうかを指定します。
error_monitoring_args: フォールトトレランスモニタリングの他のパラメーターを指定します。
ステップ 3: 高度な機能の構成
以下の高度な機能を使用して、ジョブの要件に基づいてフォールトトレランスモニタリングをカスタマイズできます。
フォールトトレランス通知の構成
ジョブのフォールトトレランスモニタリングを有効化した後、フォールトトレランスイベントの通知を設定できます。Workspace Detailsページで、Configure Workspace > Configure Event Notificationを選択し、Create Event Ruleをクリックして、イベントタイプをDLC task > Automatic Fault Toleranceに設定します。詳細については、「ワークスペースイベントセンター」をご参照ください。
NaN のトレーニング損失値など、トレーニングジョブで例外が発生した場合、コード内で AIMaster SDK を使用してカスタム通知メッセージを送信できます。
この機能を使用するには、AIMaster WHL パッケージをインストールする必要があります。詳細については、「よくある質問」をご参照ください。
from aimaster import job_monitor as jm
job_monitor_client = jm.Monitor(config=jm.PyTorchConfig())
...
if loss == Nan and rank == 0:
st = job_monitor_client.send_custom_message(content="The training loss for the job is NaN.")
if not st.ok():
print('failed to send message, error %s' % st.to_string())カスタムフォールトトレランスキーワードの構成
フォールトトレランスモニタリング機能には、一般的なリトライ可能なエラーを監視する組み込みモジュールが含まれています。失敗したインスタンスのログに特定のキーワードが出現した際にフォールトトレランス操作をトリガーしたい場合は、コード内でキーワードを構成できます。構成後、フォールトトレランスモニタリングモジュールは失敗したインスタンスの末尾ログをスキャンし、一致するキーワードを検索します。
フォールトトレランスポリシーは ExitCodeAndErrorMsg に設定されている必要があります。
PyTorch ジョブ向けのカスタムフォールトトレランスキーワード構成例
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.PyTorchConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])monitor.set_retryable_errors 関数は、カスタムフォールトトレランスキーワードを設定します。
TensorFlow ジョブ向けのカスタムフォールトトレランスキーワード構成例
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.TFConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])
段階的ジョブハング検出の構成
デフォルトでは、ハング検出設定はジョブのライフサイクル全体に適用されます。ただし、ジョブは段階的に実行されます。たとえば、初期化段階ではノード間の通信確立に時間がかかる場合がありますが、トレーニング段階ではログがより頻繁に更新されます。トレーニングプロセス中にハングしたノードを迅速に検出するために、DLC は段階的ジョブハング検出機能を提供しています。この機能により、トレーニングの各段階ごとに異なるハング検出間隔を構成できます。以下のコードはその例を示しています。
monitor.reset_config(jm_config_params)
# Example:
# monitor.reset_config(job_hang_interval=10)
# or
# config_params = {"job_hang_interval": 10, }
# monitor.reset_config(**config_params)以下のコードは、PyTorch ジョブ向けの段階的ジョブハング検出構成例を示しています。
import torch
import torch.distributed as dist
from aimaster import job_monitor as jm
jm_config_params = {
"job_hang_interval": 1800 # 全体的な 30 分間の検出。
}
jm_config = jm.PyTorchConfig(**jm_config_params)
monitor = jm.Monitor(config=jm_config)
dist.init_process_group('nccl')
...
# Implement these two functions in the AIMaster SDK.
# You only need to add annotations to your functions.
def reset_hang_detect(hang_seconds):
jm_config_params = {
"job_hang_interval": hang_seconds
}
monitor.reset_config(**jm_config_params)
def hang_detect(interval):
reset_hang_detect(interval)
...
@hang_detect(180) # この関数のスコープ内でのみ、ハング検出を 3 分にリセットします。
def train():
...
@hang_detect(-1) # この関数のスコープ内でのみ、ハング検出を一時的に無効化します。
def test():
...
for epoch in range(0, 100):
train(epoch)
test(epoch)
self.scheduler.step()
C4D の使用
C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis)は、大規模モデルトレーニングジョブにおけるパフォーマンスの低下や一部サービス停止などの問題を診断するために Alibaba Cloud が開発した独自のツールです。C4D は、Alibaba Cloud が開発したパフォーマンス専有型の集合通信ライブラリである ACCL に依存しています。ACCL がインストールされており、環境変数が正しく設定されていることを確認してください。詳細については、「ACCL: Alibaba Cloud パフォーマンス専有型の集合通信ライブラリ」をご参照ください。現在、Lingjun AI コンピューティングサービスで実行される DLC job に対して C4D 検出機能を使用できます。
仕組み
C4D はジョブ内のすべてのノードからステータス情報を集約し、通信レイヤー内または通信レイヤー外でノードに問題があるかどうかを判断します。以下の図はシステムアーキテクチャーを示しています。
パラメーター
C4D 検出を有効化した後、Other Configurations テキストボックスで以下のパラメーターを構成できます。
パラメーター | 説明 | 例 |
--c4d-log-level | C4D 出力ログレベルを設定します。有効値:
デフォルト値は Warning であり、Warning レベルおよび Error レベルのログが出力されます。通常の運用ではデフォルト値を使用することを推奨します。パフォーマンスの問題をトラブルシューティングする場合は、値を Info に設定できます。 |
|
--c4d-common-envs | C4D 実行用の環境変数を設定します。形式は
|
|
Error レベルのログが生成された場合、AIMaster は対応するノードを自動的に隔離し、ジョブを再起動します。以下の表は、各ログレベルごとの処理ロジックを示しています。
エラーレベル | エラーの説明 | アクション |
Error | デフォルトでは、通信レイヤーのハングが 3 分を超えるとジョブが失敗します。C4D_HANG_TIMEOUT および C4D_HANG_TIMES パラメーターを構成することで、このデフォルト値を変更できます。 | AIMaster はログに報告されたノードを自動的に隔離します。 |
Warn | デフォルトでは、通信レイヤーのハングが 10 秒を超えるとパフォーマンスに影響を与えますが、ジョブは失敗しません。C4D_HANG_TIMEOUT パラメーターを構成することで、このデフォルト値を変更できます。 | ログに報告されたノードは自動的に隔離されず、手動での確認が必要です。 |
通信レイヤー外のハングが 10 秒を超えると、ジョブが失敗する可能性があります。 | ログに報告されたノードは自動的に隔離されず、手動での確認が必要です。 | |
Info | 通信レイヤーの低速化および通信レイヤー外の低速化。 | これらの診断ログは主にパフォーマンスの問題に関するものであり、手動での確認が必要です。 |
DLC job の実行が遅くなったりハングしたりした場合は、DLC job リストに移動してジョブ名をクリックし、ジョブ詳細ページを開きます。[インスタンス] セクションで AIMaster ノードログを確認し、C4D 診断結果を参照してください。診断結果の詳細については、「診断結果のサンプル」をご参照ください。
診断結果
RankCommHang: ノードに通信レイヤーのハングがあることを示します。

RankNonCommHang: ノードに通信レイヤー外(例: 計算プロセス内)のハングがあることを示します。

RankCommSlow: ノードに通信レイヤーのパフォーマンス低下があることを示します。
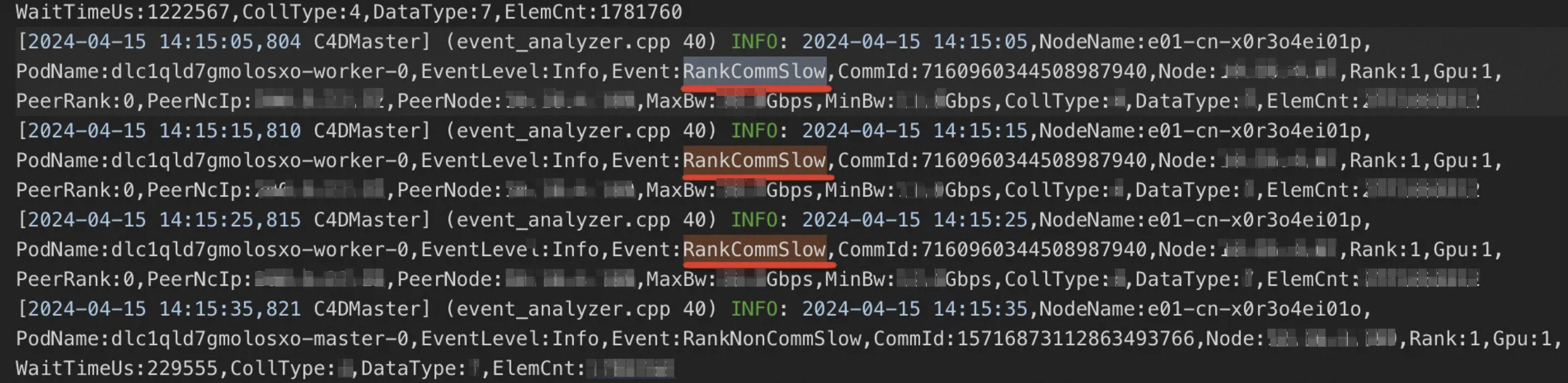
RankNonCommSlow: ノードに通信レイヤー外のパフォーマンス低下があることを示します。

呼び出しスタック分析ツールの使用
ジョブのハングは、大規模モデルトレーニングにおける一般的な失敗タイプです。代表的な例として NCCL ハングがあり、ジョブが失敗すると「Watchdog caught collective operation timeout」というログが生成されます。ジョブハングの根本原因を迅速に特定できるよう、呼び出しスタックスナップショット分析ツールを開発しました。以下の手順に従ってツールを使用してください。
ステップ 1: pystack または py-spy のインストール
コンテナイメージに pystack または py-spy がインストールされているか確認してください。インストールされていない場合は、いずれかをインストールする必要があります。以下のコマンドは pystack のインストール例を示しています。
pip install pystack -i https://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.comステップ 2: ハング検出スイッチの有効化
スイッチの有効化方法については、「コンソールで有効化する」をご参照ください。ハング検出スイッチを有効化した後、呼び出しスタックスナップショット分析ツールを使用するには、適切なハング検出しきい値を構成する必要があります。まず、ジョブのタイムアウト期間を確認します。この情報は通常、ジョブがハングした後に生成されるエラーログに記載されています。以下のコードはログのサンプルを示しています。
Watchdog caught collective operation timeout: WorkNCCL(SeqNum=2143, OpType=ALLREDUCE, NumelIn=659, NumelOut=659, Timeout(ms)=600000) ran for 600535 milliseconds before timing outこのエラーログの Timeout フィールドは、ジョブのタイムアウト期間が 600 秒 (10 分) であることを示しています。この場合、ハング検出しきい値を 450 秒に設定することを推奨します。エラーログの Timeout 値が 1800 秒の場合、ハング検出しきい値を 1500 秒に設定することを推奨します。目安として、ハング検出しきい値は Timeout 値より約 150~200 秒短く設定してください。
前述の手順に従ってハング検出機能を構成すると、AIMaster はハングが発生した際にジョブプロセスの呼び出しスタックを自動的に収集・分析します。分析結果は AIMaster ノードログで確認できます。以下の図は、ジョブハング後に生成された呼び出しスタックの分析結果サンプルを示しています。

分析結果では、stack フィールドに具体的な呼び出しスタックが表示され、threads フィールドに関連するスレッドが表示され、count フィールドに同じ呼び出しスタックを持つスレッド数が表示されます。count が 1 のスタックは、ハングの原因である可能性が非常に高く、注意深く調査する必要があります。
ステップ 4: 再起動理由の確認
再起動試行の確認: ジョブ再起動情報は試行ごとに整理されています。[ジョブ概要] ページで、試行の詳細を展開して、各ステージで消費された時間などの情報を確認できます。これにより、ジョブのステータスをより正確に把握できます。

再起動履歴の確認: 再起動回数 または Restart records タブをクリックして、再起動理由、再起動結果、再起動に要した時間などの再起動情報を確認できます。

以下の手順を実行します。
Restart records リストで、Description をクリックして、再起動の詳細情報を確認します。詳細情報には、Restarts、Restart Time、Node Name、Instance Name、Error Code、Error Message、Error Source が含まれます。
View Aggregation Fault Details をクリックして、すべての再起動レコードの詳細を展開します。

よくある質問
Q: AIMaster SDK をインストールするにはどうすればよいですか?
以下のコマンドを実行して、Python バージョンに応じた対応する WHL パッケージをインストールします。
# Python 3.6
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp36-cp36m-linux_x86_64.whl
# Python 3.8
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp38-cp38-linux_x86_64.whl
# Python 3.10
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp310-cp310-linux_x86_64.whl