OSS-HDFS は、クラウドネイティブのデータレイクストレージサービスです。 OSS-HDFS は一元化されたメタデータ管理機能を提供し、Hadoop Distributed File System (HDFS) API と完全に互換性があります。 OSS-HDFS は、POSIX (Portable Operating System Interface) もサポートしています。 OSS-HDFS を使用すると、ビッグデータおよび AI 分野のデータレイクベースのコンピューティングシナリオでデータを管理できます。 このトピックでは、JindoSDK を使用して Hadoop で OSS-HDFS にアクセスする方法について説明します。
前提条件
OSS-HDFS がバケットに対して有効になっており、OSS-HDFS にアクセスするための権限が付与されています。 詳細については、「OSS-HDFS を有効にする」をご参照ください。
背景情報
既存の Hadoop アプリケーションと Spark アプリケーションを変更することなく、OSS-HDFS を使用できます。 HDFS でデータを管理するのと同じ方法で、データにアクセスして管理するために OSS-HDFS を簡単に構成できます。 また、無制限のストレージ容量、柔軟なスケーラビリティ、高いセキュリティ、信頼性、可用性など、OSS の特性を活用することもできます。
クラウドネイティブのデータレイクは OSS-HDFS に基づいています。 OSS-HDFS を使用して、エクサバイト単位のデータまたは数億個のオブジェクトを管理し、テラバイト単位のスループットを取得できます。 OSS-HDFS は、ビッグデータストレージの要件を満たすために、フラット名前空間機能と階層名前空間機能を提供します。 階層名前空間機能を使用すると、階層ディレクトリ構造でオブジェクトを管理できます。 OSS-HDFS は、フラット名前空間と階層名前空間の間でストレージ構造を自動的に変換して、オブジェクトメタデータを一元的に管理できるようにします。 従来の HDFS の NameNode のアクティブスタンバイ冗長アーキテクチャと比較して、OSS-HDFS はメタデータ管理のためのマルチノードのアクティブアクティブ冗長メカニズムを実装しており、信頼性とスケーラビリティが大幅に向上しています。 Hadoop ユーザーは、オブジェクトをコピーしたり形式を変換したりすることなく、OSS-HDFS 内のオブジェクトにアクセスできます。 これにより、ジョブのパフォーマンスが向上し、メンテナンスコストが削減されます。
OSS-HDFS のアプリケーションシナリオ、特性、および機能の詳細については、「OSS-HDFS とは」をご参照ください。
ステップ 1: VPC を作成し、VPC に ECS インスタンスを作成する
内部エンドポイントを使用して OSS-HDFS にアクセスできる仮想プライベートクラウド (VPC) を作成します。
VPC コンソール にログインします。
VPC ページで、[VPC の作成] をクリックします。
VPC を作成する際は、VPC が OSS-HDFS を有効にするバケットと同じリージョンにあることを確認してください。 VPC の作成方法の詳細については、「VPC と vSwitch を作成する」をご参照ください。
VPC に Elastic Compute Service (ECS) インスタンスを作成します。
VPC の ID をクリックします。 表示されるページで、[リソース管理] タブをクリックします。
[含まれる基本クラウド リソース] セクションで、Elastic Compute Service の右側にある
 アイコンをクリックします。
アイコンをクリックします。[インスタンス] ページから ECS インスタンスを作成します。
ECS インスタンスを作成する際は、インスタンスが VPC と同じリージョンにあることを確認してください。 ECS インスタンスの作成方法の詳細については、「インスタンスを作成する」をご参照ください。
ステップ 2: Hadoop ランタイム環境を作成する
Java 環境をインストールします。
作成した ECS インスタンスの右側にある [接続] をクリックします。
ECS インスタンスへの接続方法の詳細については、「ECS インスタンスに接続する方法」をご参照ください。
既存の Java Development Kit (JDK) のバージョンを確認します。
java -versionオプション。 JDK のバージョンが 1.8.0 より前の場合は、JDK をアンインストールします。 JDK のバージョンが 1.8.0 以降の場合は、この手順をスキップします。
rpm -qa | grep java | xargs rpm -e --nodepsJDK パッケージをインストールします。
sudo yum install java-1.8.0-openjdk* -y次のコマンドを実行して、構成ファイルを開きます。
vim /etc/profile環境変数を追加します。
JDK の現在のパスが存在しない場合は、/usr/lib/jvm/ パスに移動して、java-1.8.0-openjdk ファイルを探します。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar export PATH=$PATH:$JAVA_HOME/bin次のコマンドを実行して、環境変数を有効にします。
source /etc/profile
SSH サービスを有効にします。
SSH サービスをインストールします。
sudo yum install -y openssh-clients openssh-serverSSH サービスを有効にします。
systemctl enable sshd && systemctl start sshdSSH キーを生成し、信頼済みリストにキーを追加します。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Hadoop をインストールします。
Hadoop インストールパッケージをダウンロードします。
この例では、Hadoop 3.4.0 のインストールパッケージがダウンロードされます。 別のバージョンをダウンロードする場合は、インストールパッケージの実際の名前を指定してください。 Hadoop インストールパッケージの入手方法の詳細については、Hadoop をご参照ください。
wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gzパッケージを解凍します。
tar xzf hadoop-3.4.0.tar.gz頻繁にアクセスするパスにパッケージを移動します。
mv hadoop-3.4.0 /usr/local/hadoop環境変数を構成します。
Hadoop の環境変数を構成します。
vim /etc/profile export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH source /etc/profileHadoop の構成ファイルで HADOOP_HOME を更新します。
cd $HADOOP_HOME vim etc/hadoop/hadoop-env.sh${JAVA_HOME} を実際のパスに置き換えます。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
オプション。 ディレクトリが存在しない場合は、次のコマンドを実行して環境変数を有効にします。
cd $HADOOP_HOME/etc/hadoopcore-site.xml および hdfs-site.xml 構成ファイルを更新します。
core-site.xml 構成ファイルを更新し、属性を追加します。
<configuration> <!-- HDFS で NameNode のアドレスを指定します。 --> <property> <name>fs.defaultFS</name> <!-- 値をホスト名または localhost に置き換えます。 --> <value>hdfs://localhost:9000</value> </property> <!-- Hadoop の一時ディレクトリをカスタムディレクトリに変更します。 --> <property> <name>hadoop.tmp.dir</name> <!-- 次のコマンドを実行して、管理ユーザーにディレクトリを管理する権限を付与します。sudo chown -R admin:admin /opt/module/hadoop-3.4.0 --> <value>/opt/module/hadoop-3.4.0/data/tmp</value> </property> </configuration>hdfs-site.xml 構成ファイルを更新し、属性を追加します。
<configuration> <!-- HDFS の複製数を指定します。 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
ファイル構造をフォーマットします。
hdfs namenode -formatHDFS を起動します。
HDFS を起動するには、NameNode、DataNode、およびセカンダリ NameNode を起動する必要があります。
HDFS を起動します。
cd /usr/local/hadoop/ sbin/start-dfs.sh進捗状況をクエリします。
jps次の出力が返されます。
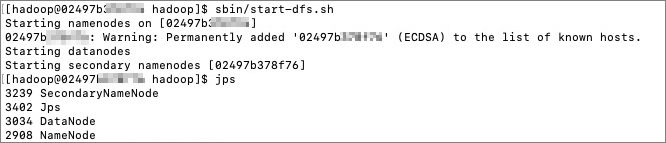
上記の手順を実行すると、デーモンプロセスが作成されます。 ブラウザを使用して http://{ip}:9870 にアクセスし、HDFS に関するインターフェイスと詳細情報を表示できます。
Hadoop がインストールされているかどうかをテストします。
hadoop version コマンドを実行します。 Hadoop がインストールされている場合は、バージョン情報が返されます。
ステップ 3: オンプレミス HDFS を OSS-HDFS に切り替える
JindoSDK JAR パッケージをダウンロードします。
宛先ディレクトリに切り替えます。
cd /usr/lib/JindoSDK JAR パッケージの最新バージョンをダウンロードします。 詳細については、GitHub をご覧ください。
JindoSDK JAR パッケージを解凍します。
tar zxvf jindosdk-x.x.x-linux.tar.gz説明x.x.x は、JindoSDK JAR パッケージのバージョン番号を示します。
環境変数を構成します。
構成ファイルを変更します。
vim /etc/profile環境変数を構成します。
export JINDOSDK_HOME=/usr/lib/jindosdk-x.x.x-linuxHADOOP_CLASSPATH を構成します。
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:${JINDOSDK_HOME}/lib/*次のコマンドを実行して、環境変数を有効にします。
. /etc/profile
JindoSDK DLS 実装クラスを構成し、バケットへのアクセスに使用する AccessKey ペアを指定します。
Hadoop の core-site.xml ファイルで JindoSDK DLS 実装クラスを構成します。
<configuration> <property> <name>fs.AbstractFileSystem.oss.impl</name> <value>com.aliyun.jindodata.oss.JindoOSS</value> </property> <property> <name>fs.oss.impl</name> <value>com.aliyun.jindodata.oss.JindoOssFileSystem</value> </property> </configuration>Hadoop の core-site.xml ファイルで、OSS-HDFS が有効になっているバケットの AccessKey ID と AccessKey シークレットを事前に構成します。
<configuration> <property> <name>fs.oss.accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.oss.accessKeySecret</name> <value>xxx</value> </property> </configuration>
OSS-HDFS のエンドポイントを構成します。
OSS で OSS-HDFS を使用してバケットにアクセスする場合は、OSS-HDFS のエンドポイントを構成する必要があります。
oss://<Bucket>.<Endpoint>/<Object>形式で OSS-HDFS にアクセスするために使用されるパスを構成することをお勧めします。 例:oss://examplebucket.cn-shanghai.oss-dls.aliyuncs.com/exampleobject.txt。 アクセスパスを構成すると、JindoSDK はアクセスパスで指定されたエンドポイントに基づいて対応する OSS-HDFS 操作を呼び出します。他の方法を使用して OSS-HDFS のエンドポイントを構成することもできます。 詳細については、「付録 1: OSS-HDFS のエンドポイントを構成するために使用されるその他の方法」をご参照ください。
ステップ 4: OSS-HDFS にアクセスする
ディレクトリを作成する
次のコマンドを実行して、examplebucket という名前のバケットに dir/ という名前のディレクトリを作成します。
hdfs dfs -mkdir oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/dir/オブジェクトをアップロードする
次のコマンドを実行して、examplebucket という名前のバケットに examplefile.txt という名前のオブジェクトをアップロードします。
hdfs dfs -put /root/workspace/examplefile.txt oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/examplefile.txtディレクトリをクエリする
次のコマンドを実行して、examplebucket という名前のバケットで dir/ という名前のディレクトリをクエリします。
hdfs dfs -ls oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/dir/オブジェクトをクエリする
次のコマンドを実行して、examplebucket という名前のバケットで examplefile.txt という名前のオブジェクトをクエリします。
hdfs dfs -ls oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/examplefile.txtオブジェクトのコンテンツをクエリする
次のコマンドを実行して、examplebucket という名前のバケットで examplefile.txt という名前のオブジェクトのコンテンツをクエリします。
重要次のコマンドを実行すると、クエリされたオブジェクトのコンテンツがプレーンテキストで画面に表示されます。 コンテンツがエンコードされている場合は、HDFS の Java API を使用してオブジェクトをデコードし、オブジェクトのコンテンツを読み取ります。
hdfs dfs -cat oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/examplefile.txtオブジェクトまたはディレクトリをコピーする
次のコマンドを実行して、subdir1 という名前のルートディレクトリを examplebucket という名前のバケットの subdir2 という名前のディレクトリにコピーします。 また、subdir1 ルートディレクトリの位置、subdir1 ルートディレクトリ内のオブジェクト、および subdir1 ルートディレクトリ内のサブディレクトリの構造と内容は変更されません。
hdfs dfs -cp oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/subdir1/ oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/subdir2/subdir1/オブジェクトまたはディレクトリを移動する
次のコマンドを実行して、srcdir という名前のルートディレクトリと、ルートディレクトリ内のオブジェクトとサブディレクトリを destdir という名前の別のルートディレクトリに移動します。
hdfs dfs -mv oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/srcdir/ oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/destdir/オブジェクトをダウンロードする
次のコマンドを実行して、examplebucket という名前のバケットから exampleobject.txt という名前のオブジェクトをコンピューターのルートディレクトリの /tmp という名前のディレクトリにダウンロードします。
hdfs dfs -get oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/exampleobject.txt /tmp/オブジェクトまたはディレクトリを削除する
次のコマンドを実行して、destfolder/ という名前のディレクトリと、ディレクトリ内のすべてのオブジェクトを examplebucket という名前のバケットから削除します。
hdfs dfs -rm oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/destfolder/