複数のノードで AI 推論サービスを起動する際、OSS Connector のモデルブロードキャスト機能を使用すると、1 つのノードのみが OSS からモデルデータをロードします。残りのノードは、チェーンベースのトポロジーを介してデータを受信します。この方法により、ソースへのトラフィックが大幅に削減され、モデルのディストリビューション効率が向上します。
仕組み
AI 推論サービスを実行している複数のノードが同時に OSS からモデルファイルをプルすると、ダウンロードアクティビティによってソースの送信帯域幅が飽和状態になる可能性があります。これにより、パフォーマンスボトルネックが発生し、起動の遅延や失敗を引き起こすことがあります。この問題は、OSS の送信帯域幅が低いリージョンで特に顕著であり、ソースへの同時トラフィックがデプロイ効率に深刻な影響を与える可能性があります。
OSS Connector のモデルブロードキャストは、大規模な AI 推論のデプロイメントを最適化します。同じモデルに対して複数の推論インスタンスが起動されると、1 つまたは少数のノードのみが OSS から直接モデルデータをロードします。このデータは、チェーンベースのトポロジーを介して他のノードに配信されます。モデルブロードキャストは、ノードのストレージとネットワークリソースを活用して、ソースへのトラフィックを削減し、ソースの負荷を軽減し、ディストリビューション効率を向上させます。
OSS Connector のモデルブロードキャストは、モデルファイルがノードから次のノードへと順次渡されるチェーンベースの転送方式を使用します。各ノードは、データの受信と転送を一度だけ行います。モデルファイルの転送では、単一のデータストリームでほとんどの主要なインスタンスタイプのネットワーク帯域幅を飽和させるのに十分な場合が多くあります。チェーンベースの方式は、1 つのノードが複数の下流ノードに同時にデータを送信する必要があるツリーベースの転送で発生しうる帯域幅のボトルネックを回避します。
OSS Connector は、高同時実行戦略を使用して、OSS からモデルファイルをメモリバッファーにプリフェッチします。これにより、推論エンジンは必要に応じてモデルを GPU メモリにロードできます。バッファーされたメモリは、推論が完了した後、遅延を経て解放されます。モデルブロードキャスト機能は、このバッファーをノード間で共有できるようにすることで、この仕組みを基盤としています。DADI P2P 機能を統合し、ノード検出とメタデータ管理には Redis または Tair サービスのみを必要とします。この設定により、バッファーされたデータを他のノードに配信できます。シングルノードのデプロイメントと比較して、このソリューションは軽量なバッファー共有ロジックを追加するだけで、モデルのロード中にアイドル状態のノードの送信帯域幅を最大限に活用します。これにより、分散モデルローディングのための費用対効果が高く効率的な方法が提供されます。
モデルブロードキャストを使用すると、特定のモデルに対して、常に単一のデータストリームのみが OSS からプルされます。これにより、バッチ起動時の OSS ソースへの負荷が大幅に削減されます。ただし、ソースのパフォーマンスが依然としてボトルネックである場合は、この機能を OSS Accelerator または DADI P2P の分散キャッシュバージョンと併用する必要があります。
前提条件
OSS Connector for AI/ML v1.2.0 以降がインストールされていること。インストール手順については、「OSS Connector for AI/ML を使用してモデルデプロイの効率を向上させる」をご参照ください。
ノード検出とメタデータ管理に利用できる Redis または Tair データベースがあること。
データベースの設定
モデルブロードキャスト機能には、ノード検出とメタデータ管理のために Redis または Tair サービスが必要です。この機能を使用するには、このデータベースを設定する必要があります。
オプション 1: Tair の購入と設定 (推奨)
Tair は、Alibaba Cloud のフルマネージド型クラウドデータベースサービスであり、Redis プロトコルと互換性があります。
Tair インスタンスを作成します。手順については、「クイックスタートの概要」をご参照ください。インスタンスのバージョンは 6.0 以降である必要があり、最小仕様を使用できます。
推論ノードが Tair インスタンスにアクセスできるように、ホワイトリストを設定します。
モデルブロードキャストを設定するには、
接続アドレス、ポート番号、ユーザー名、およびパスワードが必要です。
オプション 2: スタンドアロンの Redis サービスのデプロイ
または、Kubernetes クラスターに独自の Redis サービスをデプロイすることもできます。
以下の YAML 設定は、アクセス制御リスト (ACL) 認証を持つ Redis サービスをデプロイします。
ACL 設定ファイルを作成し、Kubernetes の Secret を生成します。
# ACL コンテンツの作成 cat > users.acl << EOF user default off -@all user Username on >Password ~* &* +@all EOF # Secret の作成 kubectl create secret generic redis-acl-secret \ --from-file=users.acl \ --dry-run=client -o yaml | kubectl apply -f -説明UsernameとPasswordを実際のユーザー名とパスワードに置き換えてください。以下の設定を使用して、Redis サービスとそのデプロイメントをデプロイします。
# redis-service.yaml apiVersion: v1 kind: Service metadata: name: redis spec: selector: app: model-redis ports: - protocol: TCP port: 6379 targetPort: 6379 --- # redis-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: model-redis-deployment spec: replicas: 1 selector: matchLabels: app: model-redis template: metadata: labels: app: model-redis spec: containers: - name: redis image: mirrors-ssl.aliyuncs.com/redis:8.4.0 ports: - containerPort: 6379 command: ["redis-server"] args: - "--aclfile" - "/etc/redis/users.acl" - "--maxmemory" - "900mb" - "--maxmemory-policy" - "volatile-lru" - "--save" - "" - "--appendonly" - "no" - "--loglevel" - "notice" resources: requests: memory: "1Gi" cpu: "100m" limits: memory: "1Gi" cpu: "200m" volumeMounts: - name: acl-config mountPath: /etc/redis/users.acl subPath: users.acl volumes: - name: acl-config secret: secretName: redis-acl-secretRedis サービスをデプロイするには、次のコマンドを実行します。
kubectl apply -f redis-service.yaml
モデルブロードキャストの有効化
OSS Connector の設定ファイル /etc/oss-connector/config.json にモデルブロードキャストの設定を追加します。
{
...
"broadcast": {
"enableBroadcast": true,
"tenant": "${P2P_KEY_PREFIX}",
"db": {
"host": "${P2P_REDIS_HOST}",
"port": 6379,
"username": "${P2P_REDIS_USERNAME}",
"password": "${P2P_REDIS_PASSWD}"
}
},
"bindPort": 19898
...
}次の表に、設定パラメーターを示します。
パラメーター | 説明 |
broadcast.enableBroadcast | モデルブロードキャストを有効にするかどうかを指定します。この機能を有効にするには、 |
broadcast.tenant | テナント名を指定します。同じテナント名を持つノードは、モデルブロードキャストを使用できます。サービスごとに一意のテナントを設定することを推奨します。 |
broadcast.db.host | Redis または Tair サービスの接続アドレスを指定します。 |
broadcast.db.port | Redis または Tair サービスのポート番号を指定します。デフォルトは 6379 です。 |
broadcast.db.username | Redis または Tair サービスのユーザー名を指定します。 |
broadcast.db.password | Redis または Tair サービスのパスワードを指定します。 |
bindPort | 他のノードにデータを提供するために使用されるポートを指定します。デフォルト値は 19898 です。 |
Kubernetes クラスターで複数のインスタンスを持つモデルブロードキャストサービスをデプロイする方法の完全な例については、「複数のインスタンスを持つモデルブロードキャストサービスのデプロイ」をご参照ください。
キャッシュサイズの上限設定
モデルブロードキャスト中、ノードは他のノードによる取得のためにモデルデータをメモリにキャッシュします。このキャッシュメモリは、以下の方法で制限できます。
方法 1: 環境変数の設定
export CONNECTOR_MAX_CACHE_ADVISE_GB=100方法 2: 設定ファイルでの設定
/etc/oss-connector/config.jsonでprefetch.maxCacheAdviseGBを設定します:{ ... "prefetch": { "vcpus": 16, "workers": 24, "maxCacheAdviseGB": 100 }, ... }
メモリ制限はソフトリミットです。
環境変数は設定ファイルよりも優先されます。
パフォーマンスレポート
以下は、異なるリージョンで Qwen2.5-72B モデル (135.437 GB) を使用したモデルブロードキャスト機能の性能テスト結果です。
北京リージョンでのテスト
テスト環境
項目 | 構成 |
OSS | 中国 (北京)、イントラネットのダウンロード帯域幅 250 Gbps |
ノード構成 | ecs.g9i.24xlarge、ネットワーク 32/48 Gbps (ピーク)、96 vCPU、384 GiB |
モデル | Qwen2.5-72B、135.437 GB |
メトリクス | vLLM API サーバーの起動からサービス準備完了までの時間、および OSS と P2P のトラフィック。 |
キャッシュサイズ無制限
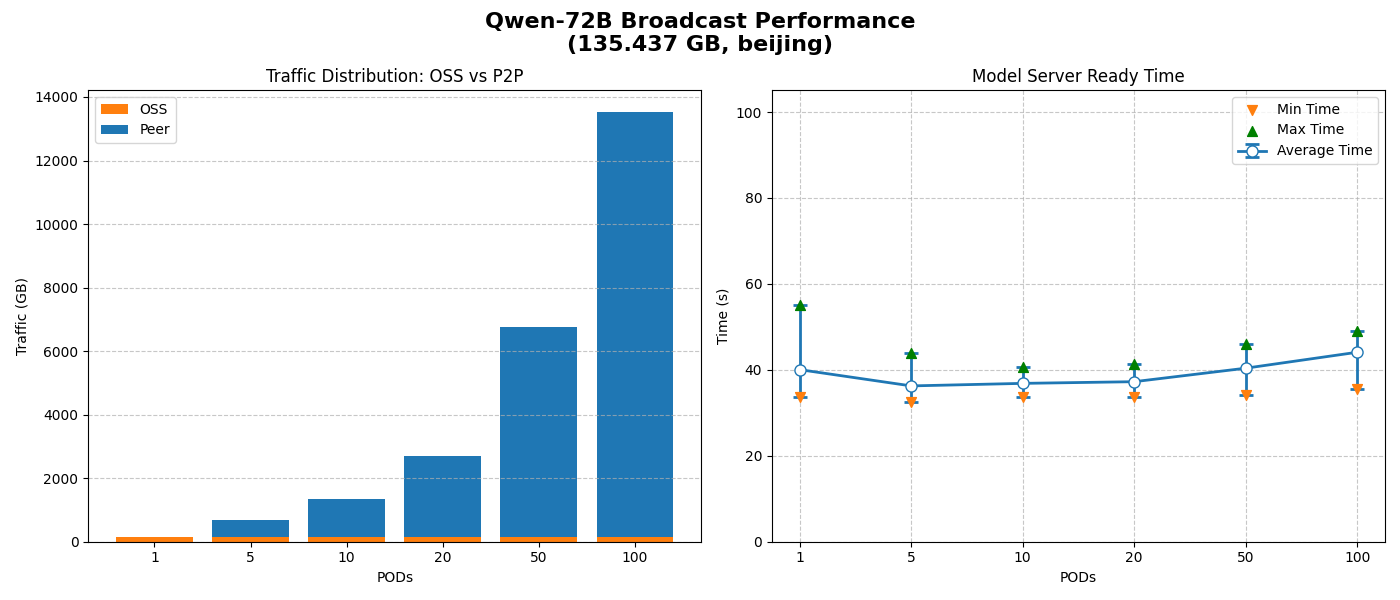
ソースへのデータストリームは 1 つだけ使用され、他のすべてのデータは P2P を介して転送されます。これにより、OSS への帯域幅の負荷が最小限に抑えられます。
平均モデル準備完了時間は O(1) に近く、ノード数に比例して増加しません。これは、優れた水平スケーリングを示しています。
キャッシュサイズ制限あり
キャッシュサイズを無制限、100 GB、60 GB、40 GB、20 GB、0 GB に制限した場合に、1、10、50、100 ノードが同時に起動したときのモデル準備完了時間をテストしました。
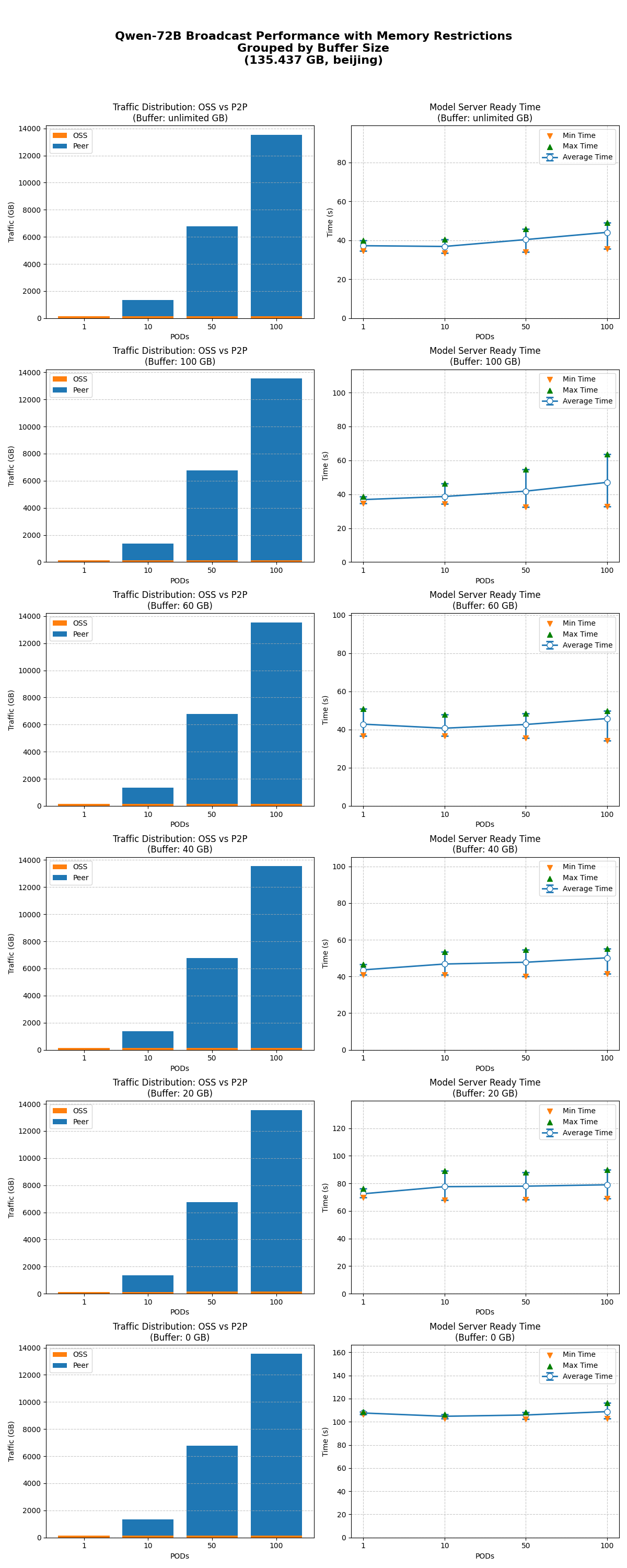
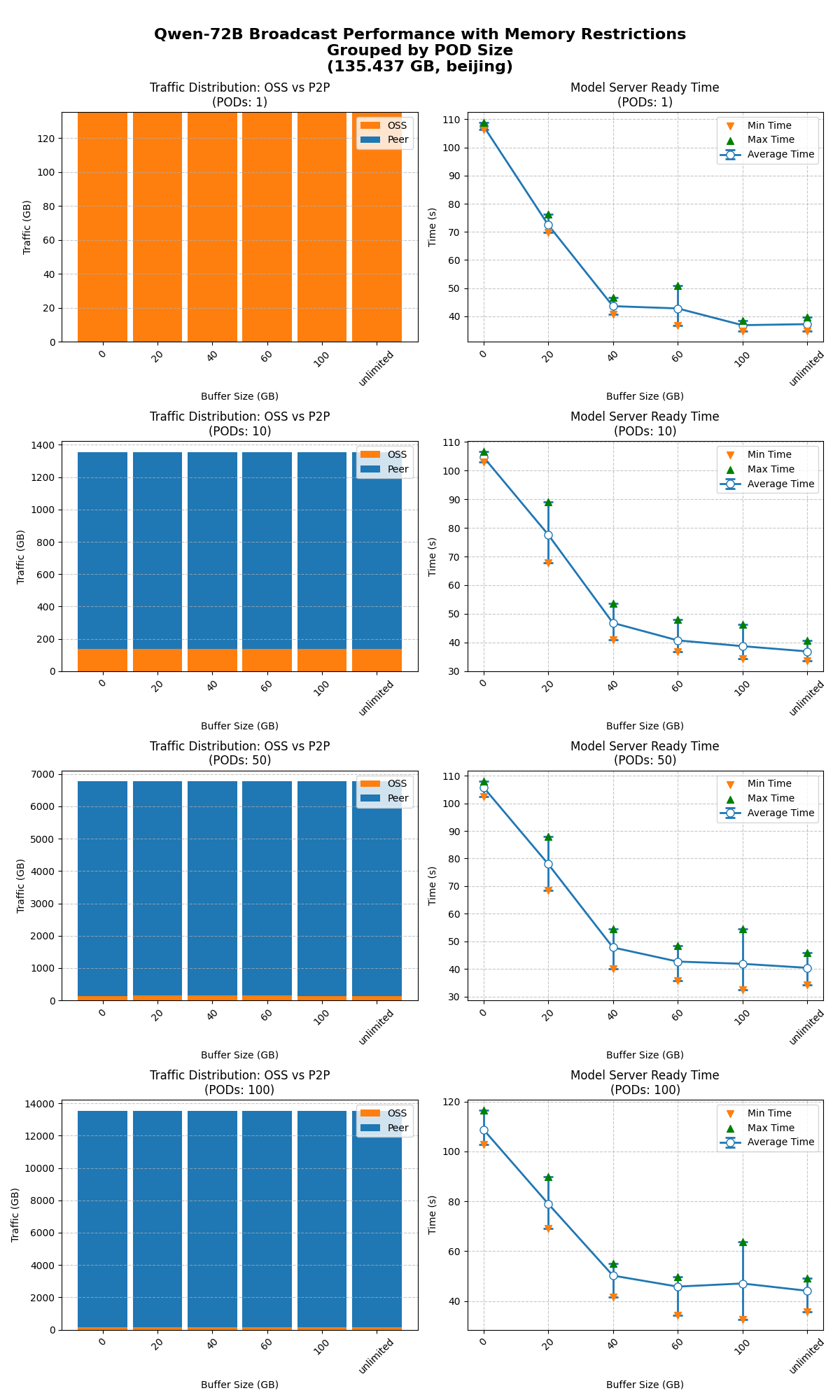
モデルブロードキャストは、さまざまなキャッシュサイズ制限下で期待どおりに機能します。
キャッシュ制限がパフォーマンスに与える影響は、すべての同時実行レベルで一貫しています。キャッシュサイズが 40 GB 以上の場合、モデル準備完了時間に大きな影響はありません。パフォーマンスは、キャッシュサイズが 20 GB 以下になると著しく低下し始めます。
ウランチャブリージョンでのテスト
テスト環境
項目 | 構成 |
OSS | 中国 (ウランチャブ)、イントラネットのダウンロード帯域幅 10 Gbps |
ノード構成 | ecs.g9i.24xlarge、ネットワーク 32/48 Gbps (ピーク)、96 vCPU、384 GiB |
モデル | Qwen2.5-72B、135.437 GB |
キャッシュサイズを無制限、60 GB、0 GB に制限した場合に、1、10、50、100 ノードが同時に起動したときのモデル準備完了時間をテストしました。
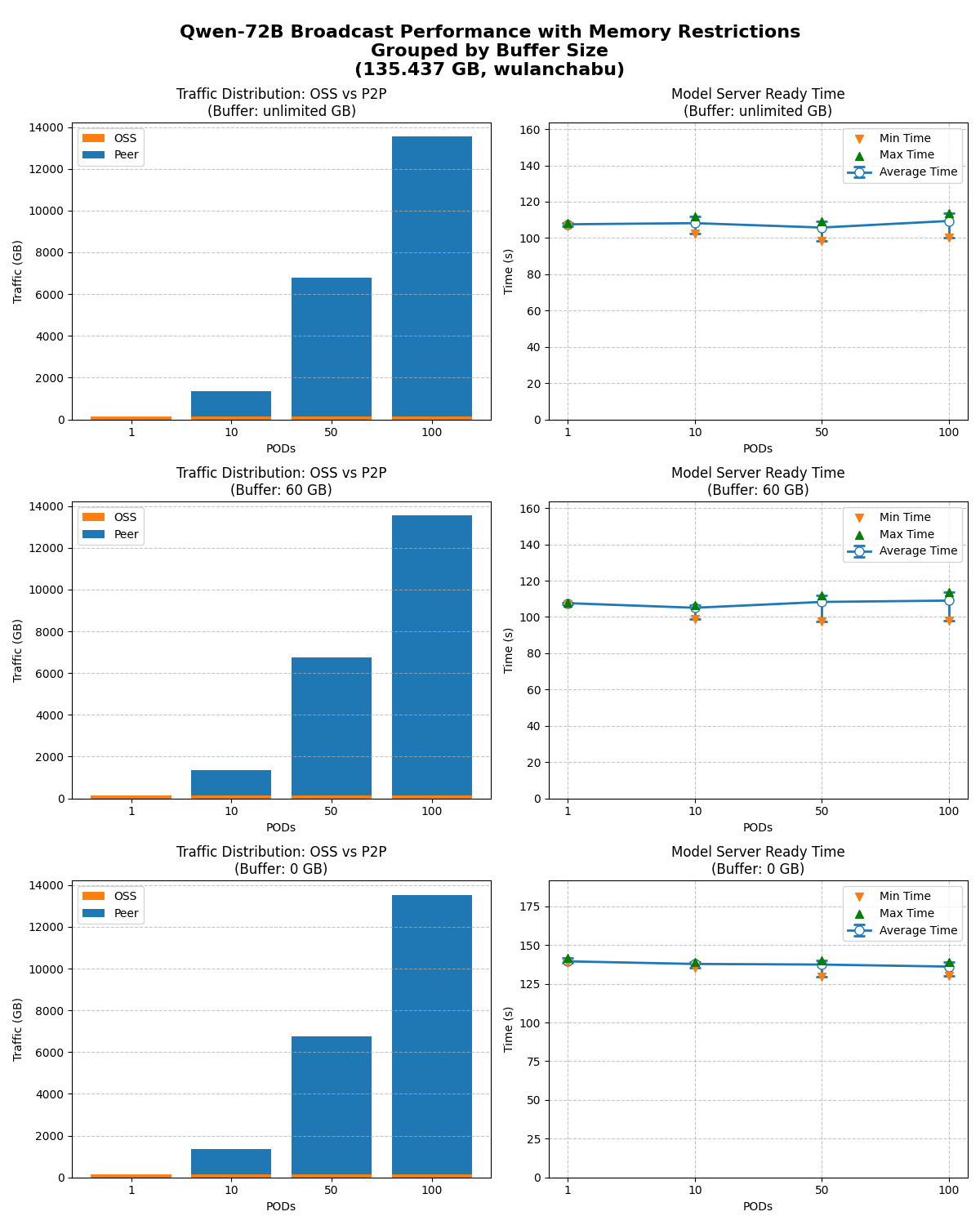
OSS のダウンロード帯域幅が限られている場合でも、テスト結果は、モデルブロードキャストが優れた水平スケーリングを維持し、OSS への帯域幅の負荷を最小限に抑えることを示しています。