概要
デジタルオペレーションの時代において、ゲーム会社はプレイヤー行動の詳細な分析を通じて、リテンション、収益化、エンゲージメントを向上させる必要があります。従来のデータウェアハウスアーキテクチャは、高コスト、スケーラビリティの低さ、エンジン断片化といった課題に直面しています。
このソリューションは、Alibaba Cloud OpenLakeオープンソースレイクハウスフレームワークに基づいて構築されており、次のコアコンポーネントを使用しています。
EMR Serverless Spark:効率的なETLのためのサーバーレスSparkエンジン。
Paimon:ACIDトランザクション、スキーマ進化、タイムトラベルをサポートする統合ストリーミング・バッチレイクストレージフォーマット。
Data Lake Formation (DLF):Spark、StarRocks、Flink、その他のエンジンを接続する統合メタデータ管理。
StarRocks:高並行ポイントクエリと複雑なOLAPをサポートする高速統合分析エンジン。
このソリューションにより、次のことが可能になります。
OSSの生ログからDWDおよびADS層まで、データをレイヤーでモデル化。
Sparkによる柔軟で強力なバッチETLを実行。
処理済み結果をPaimonレイクテーブルに書き込み、マルチエンジン共有を実現。
StarRocksでレイクテーブルまたは内部テーブルを直接クエリし、BIレポートやアドホック分析を強化。
アーキテクチャ図
前提条件
次の準備を完了します。
製品 | アクション |
EMR Serverless | Spark計算クラスターを作成し、DLF権限をアタッチします。 |
DLF | サービスを有効にします。ターゲットリージョンにPaimonカタログを作成し、 |
StarRocks | EMR Serverless StarRocksインスタンスをデプロイします (オプション - Spark + Paimonのみを使用する場合はスキップ)。 |
DataWorks | Spark ETLスクリプトを実行します。 |
操作手順
ステップ1: 環境変数を設定します (Notebookで実行)
%emr_serverless_spark
DLF_CATALOG_ID = "clg-paimon-e62c8d1e8fa04ee097be4870af155296" # ← ご利用のDLF Catalog IDに置き換えてください
REGION = "cn-hangzhou" # ← ご利用のリージョンに置き換えてください
print(f"DLF Catalog ID: {DLF_CATALOG_ID}")
print(f"Region: {REGION}")ステップ2: Sparkセッションを初期化し、データソースを検証します
from pyspark.sql import SparkSession
OSS_PUBLIC_BUCKET = f"emr-starrocks-benchmark-resource-{REGION}"
PROFILE_SRC_GLOB = f"oss://{OSS_PUBLIC_BUCKET}/sr_game_demo_v2/user_profile/*.parquet"
EVENT_SRC_GLOB = f"oss://{OSS_PUBLIC_BUCKET}/sr_game_demo_v2/user_event/*.parquet"
spark = (
SparkSession.builder
.appName("DLF-Paimon-Ingest-sr_game_demo_v2")
.config("spark.dlf.catalog.id", DLF_CATALOG_ID)
.config("spark.dlf.region", REGION)
.config("spark.hadoop.fs.oss.endpoint", f"oss-{REGION}-internal.aliyuncs.com")
.enableHiveSupport()
.getOrCreate()
)
# ファイルが存在することを確認します
def glob_count(path_glob: str) -> int:
from py4j.java_gateway import java_import
jvm = spark._jvm
hconf = spark.sparkContext._jsc.hadoopConfiguration()
Path = jvm.org.apache.hadoop.fs.Path
p = Path(path_glob)
fs = p.getFileSystem(hconf)
stats = fs.globStatus(p)
return 0 if stats is None else len(stats)
print("profile matched:", glob_count(PROFILE_SRC_GLOB))
print("event matched: ", glob_count(EVENT_SRC_GLOB))
ステップ3: 生データを読み取り、Paimon ODS層に書き込みます
利点: Paimonは、ファイルの結合、インデックス作成、スキーマ進化を自動的に管理します。手動でのParquetパーティション分割は不要です。
df_profile = spark.read.parquet(PROFILE_SRC_GLOB)
df_event = spark.read.parquet(EVENT_SRC_GLOB)
spark.sql("CREATE DATABASE IF NOT EXISTS game_db")
# Paimonテーブル (ODS層) に書き込みます
(df_profile.write
.format("paimon")
.mode("overwrite")
.saveAsTable("game_db.ods_user_profile"))
(df_event.write
.format("paimon")
.mode("overwrite")
.saveAsTable("game_db.ods_user_event"))
ステップ4: DWD詳細データ層を構築します (Spark SQL ETL)
4.1 ユーザー詳細テーブル dwd_user_details
DROP TABLE IF EXISTS game_db.dwd_user_details;CREATE TABLE game_db.dwd_user_details
USING paimon
AS
WITH p AS (
SELECT
user_id,
decode(gender, 'UTF-8') AS gender,
decode(os_version, 'UTF-8') AS os_version,
CAST(decode(current_level, 'UTF-8') AS INT) AS current_level,
decode(device_type, 'UTF-8') AS device_type,
TO_DATE(decode(last_login_date, 'UTF-8')) AS last_login_date,
decode(favorite_game_mode, 'UTF-8') AS favorite_game_mode,
decode(language_preference, 'UTF-8') AS language_preference,
decode(active_time, 'UTF-8') AS active_time,
TO_DATE(decode(registration_date, 'UTF-8')) AS registration_date,
CAST(decode(total_deaths, 'UTF-8') AS INT) AS total_deaths,
CAST(decode(game_hours, 'UTF-8') AS DOUBLE) AS game_hours,
decode(location, 'UTF-8') AS location,
decode(play_frequency, 'UTF-8') AS play_frequency,
ROW_NUMBER() OVER (
PARTITION BY user_id
ORDER BY TO_DATE(decode(last_login_date, 'UTF-8')) DESC NULLS LAST
) AS rn
FROM game_db.ods_user_profile
)
SELECT * EXCEPT (rn)
FROM p
WHERE rn = 1; -- 重複排除: 各user_idの最新のlast_login_dateを持つレコードのみを保持します4.2 ユーザーイベント詳細テーブル dwd_user_event
DROP TABLE IF EXISTS game_db.dwd_user_event;CREATE TABLE game_db.dwd_user_event
USING paimon
AS
WITH e AS (
SELECT
user_id,
LOWER(decode(event_type, 'UTF-8')) AS event_type,
TRIM(decode(timestamp, 'UTF-8')) AS ts_str,
decode(event_details, 'UTF-8') AS event_details,
decode(location, 'UTF-8') AS event_location
FROM game_db.ods_user_event
),
e_ts AS (
SELECT *,
CASE
WHEN ts_str RLIKE '^[0-9]{13}$' THEN TO_TIMESTAMP(FROM_UNIXTIME(CAST(ts_str AS BIGINT)/1000))
WHEN ts_str RLIKE '^[0-9]{10}$' THEN TO_TIMESTAMP(FROM_UNIXTIME(CAST(ts_str AS BIGINT)))
ELSE TO_TIMESTAMP(ts_str)
END AS event_ts
FROM e
)
SELECT
e.user_id,
e.event_ts,
TO_DATE(e.event_ts) AS event_date,
e.event_type,
COALESCE(NULLIF(e.event_location,''), d.location) AS location,
-- JSONから金額を抽出
COALESCE(CAST(get_json_object(event_details, '$.amount') AS DOUBLE), 0.0) AS amount,
d.gender, d.device_type
FROM e_ts e
LEFT JOIN game_db.dwd_user_details d ON e.user_id = d.user_id
WHERE e.event_ts IS NOT NULL;ステップ5: ADSアプリケーションデータ層を構築します (メトリック集約)
5.1 日次保持率テーブル ads_retention_daily
DROP TABLE IF EXISTS game_db.ads_retention_daily;CREATE TABLE game_db.ads_retention_daily
USING paimon
AS
WITH dau AS (
SELECT event_date AS dt, user_id
FROM game_db.dwd_user_event
GROUP BY event_date, user_id
)
SELECT
base.dt,
base.dau,
COALESCE(d1.d1_retained, 0) AS d1_retained,
ROUND(COALESCE(d1.d1_retained,0) * 1.0 / base.dau, 4) AS d1_retention_rate,
COALESCE(d7.d7_retained, 0) AS d7_retained,
ROUND(COALESCE(d7.d7_retained,0) * 1.0 / base.dau, 4) AS d7_retention_rate
FROM (
SELECT dt, COUNT(DISTINCT user_id) AS dau FROM dau GROUP BY dt
) base
LEFT JOIN (
SELECT a.dt, COUNT(DISTINCT a.user_id) AS d1_retained
FROM dau a JOIN dau b ON a.user_id = b.user_id AND b.dt = DATE_ADD(a.dt, 1)
GROUP BY a.dt
) d1 ON base.dt = d1.dt
LEFT JOIN (
SELECT a.dt, COUNT(DISTINCT a.user_id) AS d7_retained
FROM dau a JOIN dau b ON a.user_id = b.user_id AND b.dt = DATE_ADD(a.dt, 7)
GROUP BY a.dt
) d7 ON base.dt = d7.dt;5.2 その他のADSテーブル (元のコードを参照)
ads_purchase_trends_daily:日次GMVと有料ユーザーads_device_preference_daily:デバイス分布とシェアads_region_distribution_daily:省および市町村のDAU分布
ステップ6: StarRocksに接続します
StarRocksノードを作成して、レイクテーブルを直接クエリします。
-- レイクテーブルを直接クエリします
SELECT * FROM paimon_catalog.game_db.ads_retention_daily LIMIT 10;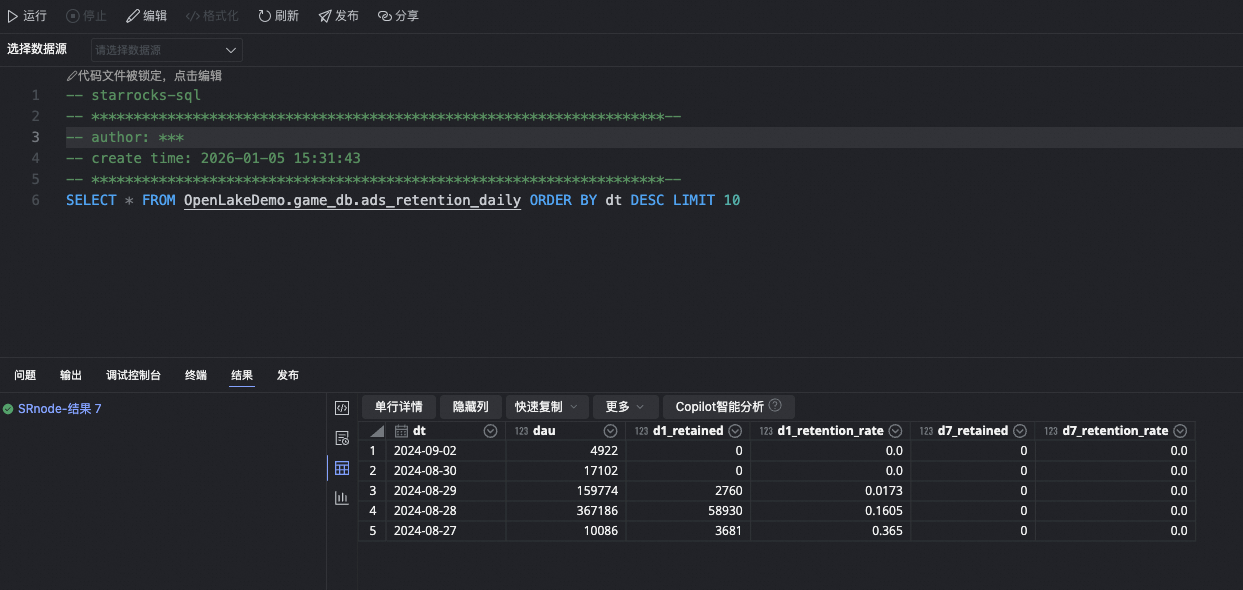
ステップ7: 可視化 (Quick BI)
Quick BIコンソールで、StarRocksデータソースを作成します。
次のSQLで新しいデータセットを作成します。
データセットSQL 1:
SELECT * FROM game_db.ADS_MV_USER_RETENTION;データセットSQL 2:
SELECT * FROM game_db.ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION;データセットSQL 3:
SELECT * FROM game_db.ADS_MV_USER_DEVICE_PREFERENCE;データセットSQL 4:
SELECT * FROM game_db.ADS_MV_USER_PURCHASE_TRENDS;
折れ線グラフ、マップ、ダッシュボード、その他の可視化を構築して、主要なメトリックを監視します。
ソリューションの利点の概要
ディメンション | 従来のアプローチ | このソリューション |
ストレージコスト | 高いHDFSコスト | 低コストのOSS + Paimonでの自動小ファイル結合 |
コンピューティングの弾力性 | 常時稼働クラスターが必要 | 従量課金制のEMR Serverless |
データ一貫性 | 手動パーティションおよびバージョン管理 | Paimon ACID + タイムトラベル |
マルチエンジン連携 | データサイロ | DLFの統合メタデータ - Spark、Flink、StarRocksで共有 |
開発効率 | 複雑なスケジューリング依存関係 | NotebookでのエンドツーエンドETLおよびSQLモデリング |