このトピックでは、LHM スケジューリング移行ツールを使用して、DolphinScheduler のスケジューリングワークフローを DataWorks に移行する方法について説明します。このプロセスには、DolphinScheduler からのタスクのエクスポート、変換、そして DataWorks へのインポートが含まれます。
1. DolphinScheduler ワークフローのエクスポート
エクスポートツールは、DolphinScheduler API を呼び出すことによって、プロジェクト、ワークフロー定義、データソース定義、およびリソースファイル情報を取得します。このツールは、1.x、2.x、3.x を含むすべてのバージョンの DolphinScheduler をサポートしています。ワークフローをエクスポートするには、次の手順に従います。
1. 前提条件
JDK 17 のランタイム環境を準備します。ランタイム環境と DolphinScheduler 間のネットワーク接続を確保してください。スケジューリング移行ツールをダウンロードし、ローカルで解凍します。
ネットワーク接続をテストするには、DolphinScheduler の ListProject API を呼び出して、情報が返され、返されたリストに移行したいプロジェクトが含まれていることを確認します。トークンの取得方法については、次のセクションをご参照ください。
# DolphinScheduler 1.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/query-project-list
# DolphinScheduler 2.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/list
# DolphinScheduler 3.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/list2. 接続情報の設定
プロジェクトディレクトリの `conf` フォルダに、`read.json` などの JSON 形式でエクスポート設定ファイルを作成します。
使用する前に、JSON ファイルからコメントを削除してください。
{
"schedule_datasource": {
"name": "YourDolphin", // DolphinScheduler データソースに名前を付けます。
"type": "DolphinScheduler", // データソースタイプ (DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // エンドポイント
"project": "Comprehensive Test", // プロジェクト名
"token": "***********************" // トークン
},
"operaterType": "AUTO" // 接続タイプ (AUTO: API を通じてスケジューリング情報を自動的に取得)
},
"conf": {
}
}2.1. エンドポイントの取得
エンドポイントは API エンドポイントであり、通常はフロントエンドページの URL と同じです。たとえば、次の図のエンドポイントは `http://120.55.X.XXX:12345` です。
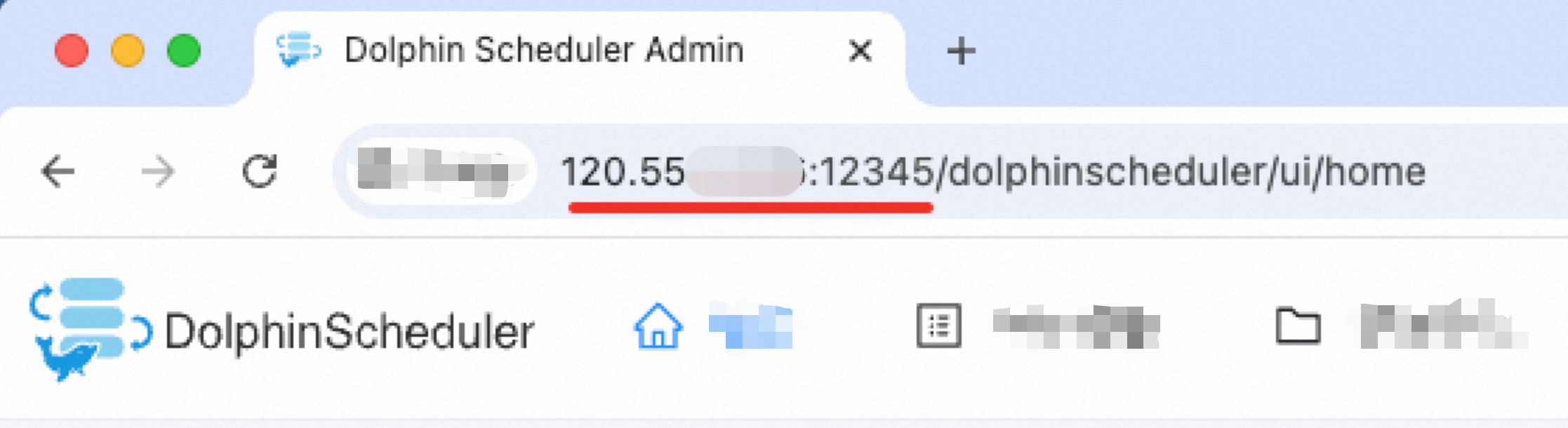
DolphinScheduler のアドレスが `http://your-company:12345/dolphinscheduler/ui/home` の場合、エンドポイントは `http://your-company:12345` です。
DolphinScheduler はオープンソースのスケジューリングエンジンであるため、その API モジュールはカスタマイズされている可能性があります。API 呼び出しが失敗した場合は、Swagger ページに移動して簡単なテストを実行し、API の属性を確認できます。
2.2. トークンの取得
セキュリティセンターで、トークン管理ページに移動し、トークンを作成して、十分に長い有効期限を設定します。
ユーザートークンは、移行したいプロジェクトに対する権限を持っている必要があります。
2.3. プロジェクトの取得
プロジェクト管理ページに移動します。移行したいプロジェクトの名前をコピーし、`project` フィールドに入力します。
3. スケジューリング検出ツールの実行
スケジューリング検出ツールを実行すると、次の内容を格納する 2 つのファイルが生成されます:
DolphinScheduler API からの生情報。これは ApiOutput パッケージと呼ばれます。
生情報のデータ構造を標準化する検出ツール解析パッケージ。これは ReaderOutput パッケージと呼ばれます。
ReaderOutput パッケージはスケジューリングエクスポートの最終結果です。ApiOutput パッケージは、エクスポートプロセス中のトラブルシューティングにのみ使用される中間結果です。
コマンドラインから検出ツールを呼び出すことができます。コマンドは次のとおりです:
sh ./bin/run.sh read \
-c ./conf/<your_config_file>.JSON \
-f ./data/0_OriginalPackage/<api_raw_info_package>.zip \
-o ./data/1_ReaderOutput/<source_discovery_export_package>.zip \
-t <PluginName>`-c` パラメーターは設定ファイルのパスを指定します。`-f` パラメーターは ApiOutput パッケージのストレージパスを指定します。`-o` パラメーターは ReaderOutput パッケージのストレージパスを指定します。`-t` パラメーターは検出プラグインの名前を指定します。
DolphinScheduler 1.x、2.x、3.x のエクスポートプラグインは、それぞれ `dolphinv1-reader`、`dolphinv2-reader`、`dolphinv3-reader` です。
たとえば、DolphinScheduler 3.2.0 からプロジェクト A をエクスポートする場合:
sh ./bin/run.sh read \
-c ./conf/projectA_read.JSON \
-f ./data/0_OriginalPackage/projectA_ApiOutput.zip \
-o ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-t dolphinv3-reader4. エクスポート結果の表示
`./data/1_ReaderOutput/` ディレクトリに生成された `ReaderOutput.zip` パッケージを開いて、エクスポート結果をプレビューできます。
統計レポートは、DolphinScheduler のワークフロー、ノード、リソース、関数、データソースに関する基本情報の概要を提供します。
`data/project` フォルダには、DolphinScheduler スケジューリング情報の標準化されたデータ構造が含まれています。
統計レポート:
「概要」という名前のシート 1 には、Reader エクスポート結果の概要が表示されます。「WORKFLOW」や「WORKFLOWNODE」などの他のシートには、ワークフロー、ノード、リソース、関数、データソースに関する特定の情報が含まれています。
統計レポートには、2 つの特別な機能があります:
1. レポートでワークフローとノードの一部のプロパティを変更できます。編集可能なフィールドは青いフォントでマークされています。次の段階であるスケジューリング変換の初期化フェーズ中に、ツールはテーブルからプロパティの変更を取得して適用します。
2. レポートでは、ワークフローの子テーブルで対応する行を削除することで、変換中に特定のワークフローをスキップできます。これはブラックリストとして機能します。注意:ワークフローが相互に依存している場合、関連するワークフローは同じバッチで変換する必要があります。ブラックリストを使用してこれらを分離しないでください。例外が発生する原因となります。
詳細については、「スケジューリング移行の概要レポートを使用してスケジューリングプロパティを補足・修正する」をご参照ください。
5. よくある質問
5.1. (バッチ検出) 複数のプロジェクトを一度に検出できますか?
はい、できます。`project` 設定項目に複数のプロジェクト名をカンマで区切って入力できます。名前にスペースを追加しないでください。DolphinScheduler のプロジェクト名にはスペースが含まれる可能性があり、ツールはスペースを名前の一部として照合するためです。
ファイルを使用する前に、JSON コード内のコメントを削除してください。
{
"schedule_datasource": {
"name": "YourDolphin", // Dolphin データソースに名前を付けます。
"type": "DolphinScheduler", // データソースタイプ (DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // エンドポイント
"project": "Project1,Project2", // プロジェクト名
"token": "***********************" // トークン
},
"operaterType": "AUTO" // 接続タイプ (AUTO: API を通じてスケジューリング情報を自動的に取得)
},
"conf": {
}
}実行コマンドでは、`-f` と `-o` パラメーターはフォルダパスを指定する必要があります。ツールは各プロジェクトに対して個別のエクスポートパッケージを自動的に作成します。
sh ./bin/run.sh read \
-c ./conf/<your_config_file>.JSON \
-f ./data/0_OriginalPackage/ \
-o ./data/1_ReaderOutput/ \
-t <dolphinv1/2/3-reader>5.2. (手動モード) API がない場合はどうすればよいですか?
一部の開発者は DolphinScheduler から API モジュールを削除しており、API 接続を介してスケジューリング情報を取得できなくなっています。代替案として、`./data/0_OriginalPackage/` ディレクトリに生情報パッケージを手動で構築し、設定で `operaterType` を `MANUAL` に変更することができます。ツールは、手動で構築されたパッケージを入力として使用し、DolphinScheduler の検出を完了します。
ファイルを使用する前に、JSON コード内のコメントを削除してください。
{
"schedule_datasource": {
"name": "YourDolphin", // Dolphin データソースに名前を付けます。
"type": "DolphinScheduler", // データソースタイプ (DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // エンドポイント
"project": "ComprehensiveTest", // プロジェクト名
"token": "***********************" // トークン
},
"operaterType": "MANUAL" // 接続タイプ (MANUAL: オフラインモード)
},
"conf": {
}
}生パッケージ構造の例:
.
├── package_info.JSON
├── projects.JSON
├── projects
│ └── ComprehensiveTest
│ └── processDefinition
│ └── process_definitions_page_1.JSON
├── datasource
│ └── datasource_page_1.JSON
├── resource
│ └── resources.JSON
└── udfFunction
└── udf_function_page_1.JSON`package_info.json` には、DolphinScheduler のバージョンを含むパッケージ情報が含まれています。
{
"version": "3.2.0"
}`projects.json` にはプロジェクト情報が含まれています。手動で構築する場合は、`id`、`userId`、`code`、`name` フィールドの入力に集中してください。
[
{
"id": 2,
"userId": 1,
"code": 16372996967936,
"name": "Comprehensive Test",
"description": "",
"createTime": "2025-01-20 11:40:39",
"updateTime": "2025-01-20 11:40:39",
"perm": 0,
"defCount": 0,
"instRunningCount": 0
}
]`projects` フォルダにはワークフロー定義が格納されます。手動で構築する場合は、次のレベルのディレクトリをプロジェクト名に変更します。次に、DolphinScheduler インターフェイスからワークフロー定義をエクスポートし、それらを `process_definitions_page_*.json` に順次名前を変更して、`processDefinition` ディレクトリに配置します。
`datasource`、`resource`、`udfFunction` には、それぞれデータソース情報、リソースファイル情報、UDF 情報が含まれています。DolphinScheduler インターフェイスにはこれらの要素のエクスポート機能がないため、省略できます。`datasource_page_1.json`、`resources.json`、`udf_function_page_1.json` には空の配列 (`[]`) を入力できます。これらの要素を省略すると、ワークフロー移行の詳細に軽微な影響があります。これは、データソースに関連付けられた SQL ノードのマッピング、データソースに関連付けられた非カスタムテンプレートモードの DataX ノードのマッピング、およびノードとリソース間の参照関係の移行に影響します。影響を受けるノードは DataWorks で正常に作成されますが、DataWorks でノードとデータソースおよびリソースのバインドを手動で設定する必要があります。
5.3. トークンは有効なのに、一部のワークフローがエクスポートから漏れている場合はどうすればよいですか?
まず、トークンがプロジェクトに対する権限を持っているかどうかを確認してください。
さらに、DolphinScheduler 1.x の一部のマイナーバージョンの API は、エクスポート中にデータ損失を引き起こす可能性があります。エクスポート結果の統計レポートを使用して、不足しているワークフローを特定し、追加することができます。
2. DataWorks 向け DolphinScheduler ワークフローの変換
DolphinScheduler は人気のあるオープンソースのスケジューリングエンジンです。DataWorks は DolphinScheduler のスケジューリング機能を完全にサポートしています。移行ツールがワークフローを変換した後、DolphinScheduler と同じ効果で DataWorks で実行できます。
1. 前提条件
検出ツールが正常に実行され、DolphinScheduler のスケジューリング情報がエクスポートされ、`ReaderOutput.zip` ファイルが生成されていること。
(任意ですが推奨) 検出エクスポートパッケージを開き、統計レポートをチェックして、移行範囲内のすべての項目がエクスポートされたことを確認します。
2. 変換設定項目
2.1. 変換設定テンプレート
ファイルを使用する前に、JSON コード内のコメントを削除してください。
{
"conf": {},
"self": {
"if.use.default.convert": false,
"if.use.migrationx.before": false,
"if.use.dataworks.newidea": true,
"owner.map": [ // オーナーマッピング
{
"src": "1", // DolphinScheduler ユーザー ID
"tgt": "202006995118212119" // DataWorks ユーザー ID
}
],
"conf": [
{
"nodes": "all", // ルールグループの範囲
"rule": {
"settings": {
// DolphinScheduler Shell ノードを DataWorks Shell ノードに変換
"workflow.converter.shellNodeType": "DIDE_SHELL",
// 不明なノードをデフォルトで DataWorks 仮想ノードに変換
"workflow.converter.target.unknownNodeTypeAs": "VIRTUAL",
// DolphinScheduler SQL ノードをデータソースタイプに基づいて対応する DataWorks SQL またはデータベースノードに変換
"workflow.converter.dolphinscheduler.sqlNodeTypeMapping": {
"CLICKHOUSE": "CLICK_SQL",
"HIVE": "ODPS_SQL",
"STARROCKS": "StarRocks",
"DORIS": "HOLOGRES_SQL",
"MYSQL": "MYSQL",
"REDSHIFT": "Redshift",
"SQLSERVER": "SQLSERVER",
"PRESTO": "EMR_PRESTO",
"POSTGRESQL": "POSTGRESQL",
"ORACLE": "Oracle",
"ATHENA": "MYSQL"
},
// DolphinScheduler と DataWorks のデータソース名のマッピング
"workflow.converter.connection.mapping": {
"mysqlDb1": "dataworks_mysqlDb1",
"srDb1": "dataworks_srDb1"
},
// DataWorks にバインドされたメインコンピュートエンジン (EMR/MaxCompute/Hologres)
"workflow.converter.target.engine.type": "EMR",
// DolphinScheduler Spark ノードを DataWorks MaxCompute Spark ノードに変換
"workflow.converter.sparkSubmitAs": "ODPS_SPARK",
"workflow.converter.sparkVersion": "3.x",
}
}
}
]
},
"schedule_datasource": {
"name": "DsProject",
"type": "DolphinScheduler"
},
"target_schedule_datasource": {}
}2.2. オーナーマッピング
DolphinScheduler は各ワークフローのオーナーを記録します。オーナーはチーム開発にとって重要な情報です。このツールは、DolphinScheduler ユーザーを DataWorks ユーザーにマッピングして、ワークフローとノードに対応するオーナーを割り当てることをサポートしています。
DolphinScheduler のユーザー名と ID は、ユーザー管理ページから取得できます。
DataWorks ワークスペースでは、ユーザーをメンバーとして追加できます。ユーザー ID は右上隅から取得できます。
DataStudio ページのオーナーのドロップダウンリストから ID を取得することもできます。
2.3. ノード変換ルール
2.3.1. ルールの範囲
ノード変換ルールの範囲を設定できます。たとえば、すべてのノードを統一されたルールに従って変換するには、`"nodes": "all"` を設定し、`Settings` を入力します。通常、`all` ルールグループを 1 つ設定するだけで十分です。
ファイルを使用する前に、JSON コード内のコメントを削除してください。
{
"conf": {},
"self": {
"conf": [
{
"nodes": "all", // ルールグループの範囲は ALL です。すべてのノードがこのルールに従って変換されます。
"rule": {
"settings": {
// 設定
}
}
]
}
}一部のノードに個別の変換ルールが必要な場合は、`nodes` でルールの範囲をタスク ID または名前を入力して指定できます。ノードのバッチにルールを設定するには、ID または名前をカンマで区切ります。名前を使用すると設定が不正確になる可能性があるため、ID を使用して範囲を指定することを推奨します。正規表現を使用してノード名を照合することもできます。さらに、残りのノードにデフォルトの変換ルールを提供するために、`normal` ルールグループを設定することを強く推奨します。
ファイルを使用する前に、JSON コード内のコメントを削除してください。
{
"conf": {},
"self": {
"conf": [
{
"nodes": "node1Name, node2Id", // ルールグループの範囲は node1 と node2 です。
"rule": {
"settings": {
// 設定 1
}
},
{
"nodes": "node3Name, node4Id", // ルールグループの範囲は node3 と node4 です。
"rule": {
"settings": {
// 設定 2
}
},
{
"nodes": "regexExpression", // 正規表現によるノード名のフィルタリングをサポートします。
"rule": {
"settings": {
// 設定 3
}
},
{
"nodes": "normal", // 残りのノードの変換ルール。
"rule": {
"settings": {
// 設定 4
}
}
]
}
}2.3.2. 変換ルール
DolphinScheduler 1.x、2.x、3.x は異なるタイプのノードをサポートしています。したがって、変換ソリューションと設定項目は異なります。詳細は次のとおりです。
2.3.2.1. DolphinScheduler 3.x の変換設定
このツールは現在、次の DolphinScheduler 3.x ノードタイプの変換をサポートしています:
SHELL, SQL, PYTHON, DATAX, SQOOP, SEATUNNEL, HIVECLI, SPARK (Java, Python, Sql), MR, PROCEDURE, HTTP, CONDITIONS, SWITCH, DEPENDENT, SUB_PROCESS
DataWorks マッピングルールを設定できるタイプは次のとおりです:
SHELL (workflow.converter.shellNodeType):
DIDE_SHELL、EMR_SHELL、または VIRTUAL ノードに変換することを推奨します。
SQL (workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
さまざまな SQL ノードまたはデータベースノードに変換することを推奨します。
PROCEDURE (workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
さまざまな SQL ノードまたはデータベースノードに変換することを推奨します。
PYTHON (workflow.converter.pyNodeType):
PYTHON、PYODPS、PYODPS3、または EMR_SHELL に変換することを推奨します。
HIVECLI (workflow.converter.dolphinscheduler.sqlNodeTypeMapping/HIVE):
EMR_HIVE または ODPS_SQL に変換することを推奨します。
SPARK (workflow.converter.sparkSubmitAs):
SparkJava および SparkPython ノードを ODPS_SPARK または EMR_SPARK ノードに変換することを推奨します。
SparkSql ノードを ODPS_SQL または EMR_SPARK_SQL ノードに変換することを推奨します。
MR (workflow.converter.mrNodeType):
ODPS_MR または EMR_MR ノードに変換することを推奨します。
DataWorks のノードタイプの詳細については、次の列挙クラスをご参照ください:
固定の変換ルールを持つノードタイプ:
DATAX: これらのノードは DI ノードに変換されます。変換は、カスタムテンプレートモード (JSON スクリプトモード) と通常モード (フロントエンドフォーム入力モード) の両方をサポートします。
次のデータソースリーダープラグイン設定がサポートされています:MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb。
次のデータソースライタープラグイン設定がサポートされています:MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb。
SQOOP: これらのノードは DI ノードに変換されます。
次のデータソースリーダープラグイン設定がサポートされています:Mysql -> mysql, Hive -> hive, HDFS -> hdfs。
次のデータソースライタープラグイン設定がサポートされています:Mysql -> mysql, Hive -> hive, HDFS -> hdfs。
SEATUNNEL:コンポーネントを DI ノードに変換します。
スクリプト変換はまだサポートされていません。ノードとそのスケジューリング情報のみが変換されます。
HTTP: これらのノードは DIDE_SHELL (汎用 Shell) ノードに変換されます。移行ツールはリクエストパラメーターを自動的に curl コマンドに連結します。
SWITCH: これらのノードは CONTROLLER_BRANCH (ブランチ) ノードに変換されます。機能は移行前後で同じです。
SUB_PROCESS: これらのノードは SUB_PROCESS ノードに変換されます。機能は移行前後で同じです。DataWorks にインポートする際、移行ツールは参照されるワークフローの「参照可能」スイッチを有効にすることに注意してください。参照されるワークフローは、SUB_PROCESS 呼び出しによってのみ開始でき、単独で実行するようにスケジュールすることはできません。
DEPENDENT: これらのノードは VIRTUAL ノードに変換されます。依存関係はノードの系統依存関係に変換されます。たとえば、Dependent ノードがワークフロー A に依存している場合、依存関係はワークフロー A の末尾ノードから Dependent ノードへの系統に変換されます。Dependent ノードがノード A に依存している場合、依存関係はノード A から Dependent ノードへの系統に変換されます。次の図はこれらの例を示しています:
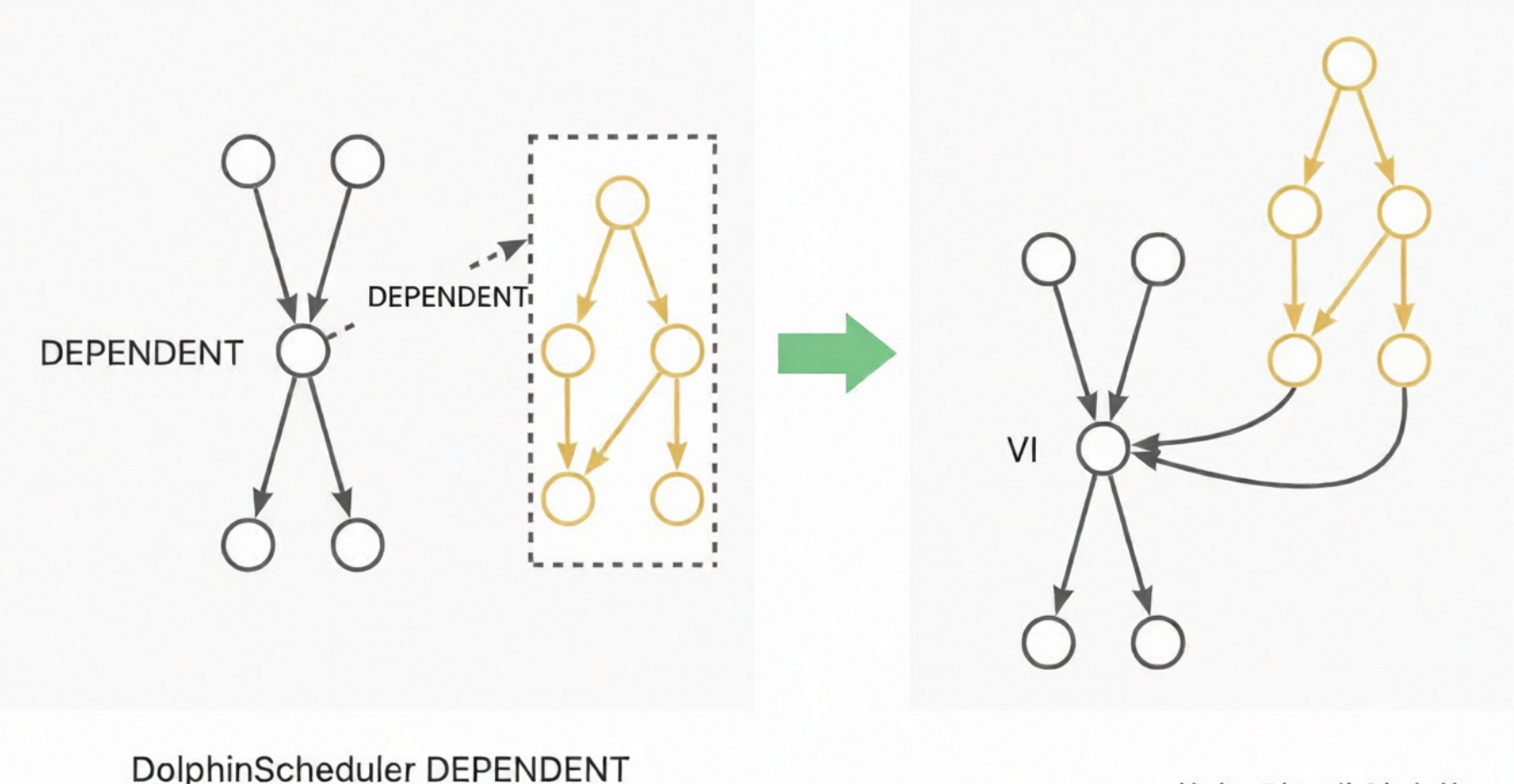
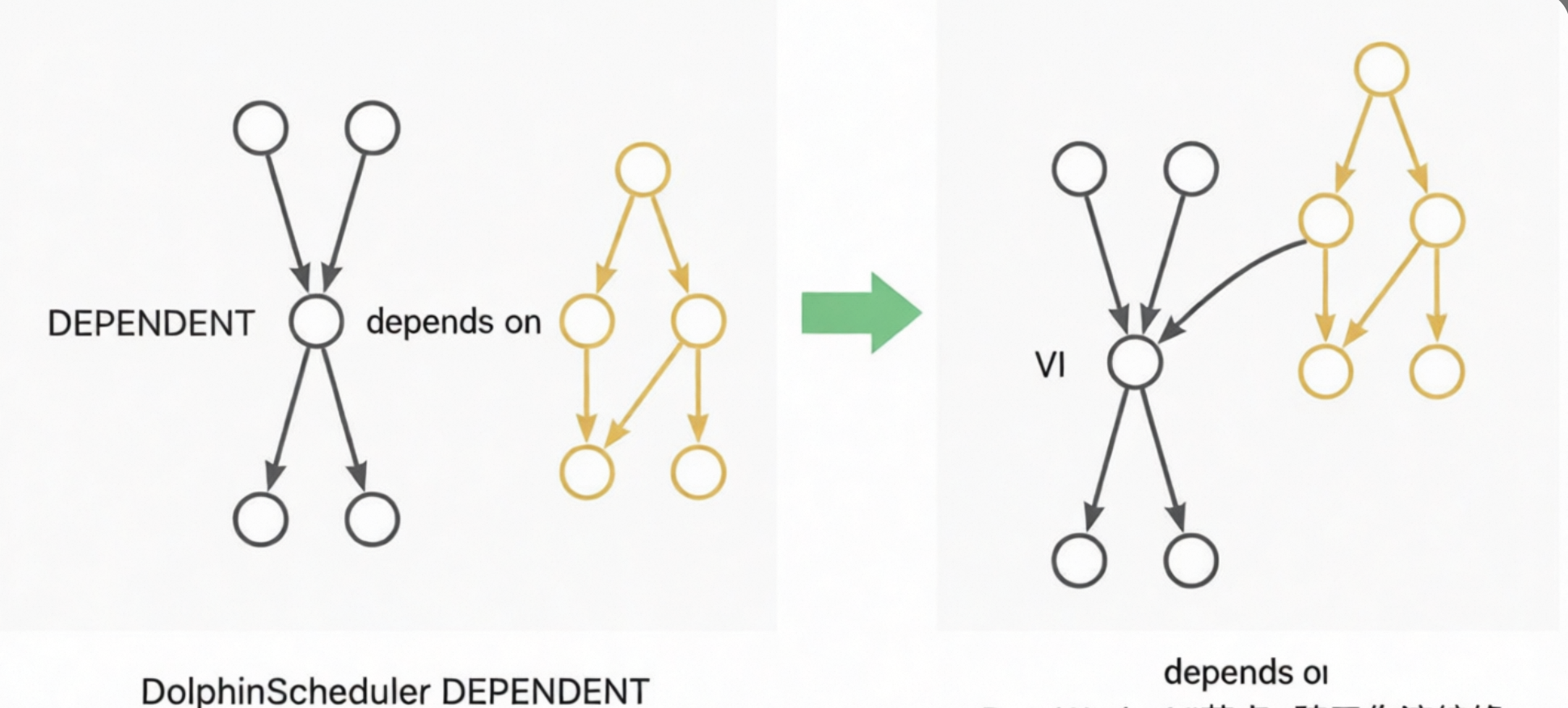
CONDITIONS: このノードには 2 層のロジックが含まれており、2 層の CONTROLLER_JOIN (join) ノードを使用して実装されます。CONDITIONS ノードには 2 つの上流ノード A と B、および 2 つの下流ノード C と D があります。論理式は `((!A&B)|(A&!B)|(!A&!B))` です。式が true の場合、フローは C に進みます。式が false の場合、フローは D に進みます。上層は `!A&B`、`A&!B`、`!A&!B` の結果を計算するために 3 つの join ノードを生成します。下層は 2 つのノードを生成します。1 つのノードは `((!A&B)|(A&!B)|(!A&!B))==true` の場合に下流ノード C の実行をトリガーします。もう 1 つのノードは `(!(!A&B)&!(A&!B)&!(!A&!B))==true` の場合に下流ノード D の実行をトリガーします。このプロセスは、元の CONDITIONS ノードと同じ効果を実現します。
2.3.2.2. DolphinScheduler 2.x の変換設定
このツールは現在、次の DolphinScheduler 2.x ノードタイプの変換をサポートしています:
SHELL, SQL, PYTHON, DATAX, SQOOP, HIVECLI, SPARK (Java, Python, Sql), MR, PROCEDURE, HTTP, CONDITIONS, SWITCH, DEPENDENT, SUB_PROCESS
バージョン 2.x と比較して、DolphinScheduler 3.x は SEATUNNEL ノードタイプのみを追加しています。他のノードの変換ソリューションと設定項目は DolphinScheduler 3.x と同じです。詳細については、前のセクションをご参照ください。
2.3.2.3. DolphinScheduler 1.x の変換設定
このツールは現在、次の DolphinScheduler 1.x ノードタイプの変換をサポートしています:
SHELL, SQL, PYTHON, DATAX, SQOOP, SPARK (Java, Python, Sql), MR, CONDITIONS, DEPENDENT, SUB_PROCESS
これらのノードの変換ソリューションと設定項目は DolphinScheduler 3.x と同じです。詳細については、前のセクションをご参照ください。
3. スケジューリング変換ツールの実行
コマンドラインから変換ツールを呼び出すことができます。コマンドは次のとおりです:
sh ./bin/run.sh convert \
-c ./conf/<your_config_file>.JSON \
-f ./data/1_ReaderOutput/<source_discovery_export_package>.zip \
-o ./data/2_ConverterOutput/<transformation_result_package>.zip \
-t <PluginName>`-c` パラメーターは設定ファイルのパスを指定します。`-f` パラメーターは ReaderOutput パッケージのストレージパスを指定します。`-o` パラメーターは ConverterOutput パッケージのストレージパスを指定します。`-t` パラメーターは変換プラグインの名前を指定します。DolphinScheduler 1.x、2.x、3.x の変換プラグインは、それぞれ `dolphinv1-dw-converter`、`dolphinv2-dw-converter`、`dolphinv3-dw-converter` です。
たとえば、DolphinScheduler 3.x からプロジェクト A を変換する場合:
sh ./bin/run.sh convert \
-c ./conf/projectA_convert.JSON \
-f ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-o ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-t dolphinv3-dw-converter変換ツールは、操作中にプロセス情報を出力します。発生する可能性のあるエラーに注意してください。変換が完了すると、成功した変換と失敗した変換の統計がコマンドラインに出力されます。一部のノードの変換に失敗しても、変換プロセス全体には影響しないことに注意してください。少数のノードの変換に失敗した場合は、DataWorks に移行した後に手動で修正できます。
4. 変換結果の表示
`./data/2_ConverterOutput/` ディレクトリに生成された `ConverterOutput.zip` パッケージを開いて、変換結果をプレビューできます。
統計レポートは、変換されたワークフロー、ノード、リソース、関数、データソースに関する基本情報の概要を提供します。
`data/project` フォルダは、変換されたスケジューリング移行パッケージの主要部分です。
統計レポートには、2 つの特別な機能があります:
1. レポートでワークフローとノードの一部のプロパティを変更できます。編集可能なフィールドは青いフォントでマークされています。次の段階である DataWorks へのインポート中に、ツールはテーブルからプロパティの変更を取得して適用します。
2. レポートでは、ワークフローの子テーブル (ワークフローブラックリスト) で対応する行を削除することで、DataWorks へのインポート時に特定のワークフローをスキップできます。注意:ワークフローが相互に依存している場合、関連するワークフローは同じバッチでインポートする必要があります。ブラックリストを使用してそれらを分離しないでください。分離すると例外が発生します。
詳細については、「スケジューリング移行の概要レポートを使用してスケジューリングプロパティを補足・修正する」をご参照ください。
3. DataWorks へのインポート
LHM 移行ツールの異種変換機能は、ソースシステムのスケジューリング要素を DataWorks のスケジューリングフォーマットに変換します。このツールは、さまざまな移行シナリオに対して統一されたアップロードエントリを提供し、ワークフローを DataWorks にインポートできます。
インポートツールは複数回の書き込みをサポートし、上書きモードでワークフローを自動的に作成または更新します。
1. 前提条件
1.1. 変換の成功
変換ツールが正常に実行され、ソースのスケジューリング情報が DataWorks のスケジューリングフォーマットに変換され、`ConverterOutput.zip` ファイルが生成されていること。
(任意ですが推奨) 変換出力パッケージを開き、統計レポートをチェックして、移行の範囲が正常に変換されたことを確認します。
1.2. DataWorks の設定
DataWorks で、次の操作を実行します:
1. ワークスペースを作成します。
2. AccessKey ペアを作成し、ワークスペースの管理者権限があることを確認します。書き込みの問題が発生した場合のトラブルシューティングを容易にするために、アカウントにバインドされた AccessKey ペアを作成することを強く推奨します。
3. ワークスペースで、データソースを作成し、コンピュートリソースをバインドし、リソースグループを作成します。
4. ワークスペースで、リソースファイルをアップロードし、UDF を作成します。
1.3. ネットワーク接続の確認
DataWorks エンドポイントに接続できることを確認します。
エンドポイントのリスト:
ping dataworks.aliyuncs.com2. インポート設定項目
プロジェクトディレクトリの `conf` フォルダに、`writer.json` などのエクスポート用の JSON 設定ファイルを作成できます。
ファイルを使用する前に、JSON コード内のコメントを削除してください。
{
"schedule_datasource": {
"name": "YourDataWorks", // DataWorks データソースに名前を付けます。
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // エンドポイント
"project_id": "YourProjectId", // ワークスペース ID
"project_name": "YourProject", // ワークスペース名
"ak": "************", // AK
"sk": "************", // SK
},
"operaterType": "MANUAL"
},
"conf": {
"di.resource.group.identifier": "Serverless_res_group_***_***", // Data Integration リソースグループ
"resource.group.identifier": "Serverless_res_group_***_***", // スケジューリングリソースグループ
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls", // DataWorks ノードタイプテーブルへのパス
"qps.limit": 5 // DataWorks への API リクエスト送信の QPS 制限
}
}2.1. エンドポイント
DataWorks ワークスペースが配置されているリージョンに基づいてエンドポイントを選択します。詳細については、以下をご参照ください:
2.2. ワークスペース ID と名前
DataWorks コンソールを開きます。ワークスペース製品ページに移動し、ページの右側にある基本情報からワークスペース ID と名前を取得します。
2.3. AccessKey ペアの作成と権限付与
ユーザーページで、AccessKey ペアを作成します。AccessKey ペアは、ターゲットの DataWorks ワークスペースに対する管理者としての読み取りおよび書き込み権限を持っている必要があります。
権限管理は 2 か所で行われます。アカウントが RAM ユーザーの場合、まず RAM ユーザーに DataWorks 操作の権限を付与する必要があります。
ポリシーページ: https://ram.console.alibabacloud.com/policies
次に、DataWorks ワークスペースで、アカウントにワークスペースの権限を付与します。
注意:AccessKey にはネットワークアクセス制限ポリシーを設定できます。移行ツールが実行されているマシンの IP アドレスがアクセスを許可されていることを確認してください。
2.4. リソースグループ
DataWorks ワークスペース製品ページの左側のナビゲーションウィンドウで、[リソースグループ] を選択します。[リソースグループ] ページで、リソースグループをアタッチし、その ID を取得します。
汎用リソースグループは、ノードスケジューリングと Data Integration の両方に使用できます。スケジューリングリソースグループ (`resource.group.identifier`) と Data Integration リソースグループ (`di.resource.group.identifier`) を同じ汎用リソースグループに設定できます。
2.5. QPS 設定
このツールは、DataWorks API を呼び出すことによってデータをインポートします。DataWorks のエディションによって、読み取りおよび書き込み OpenAPI 呼び出しのクエリ/秒 (QPS) 制限と 1 日あたりの呼び出し制限が異なります。詳細については、「制限事項」をご参照ください。
DataWorks Basic Edition、Standard Edition、Professional Edition の場合、`"qps.limit"` を `5` に設定することを推奨します。Enterprise Edition の場合、`"qps.limit"` を `20` に設定することを推奨します。
注:複数のインポートツールを同時に実行しないでください。
2.6. DataWorks ノードタイプ ID の設定
DataWorks では、一部のノードタイプにリージョンごとに異なる TypeID が割り当てられます。特定の TypeID は、DataWorks の DataStudio インターフェイスに依存します。この特性は主にデータベースノードに適用されます。詳細については、「データベースノード」をご参照ください。
たとえば、MySQL ノードの NodeTypeId は、中国 (杭州) リージョンでは 1000039、中国 (深セン) リージョンでは 1000041 です。
DataWorks のこれらのリージョン差分に適応するために、ツールは、ツールが使用するノード TypeID テーブルを指定するための設定可能な方法を提供します。
インポートツールの設定項目を使用してテーブルを指定できます:
"conf": {
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls" // DataWorks ノードタイプテーブルへのパス
}DataWorks の DataStudio インターフェイスからノードタイプ ID を取得するには、ワークフローを作成し、ワークフロー内にノードを作成して、[保存] をクリックします。その後、ワークフローの Spec を表示できます。
ノードタイプが正しく設定されていない場合、ワークフローが公開されるときに次のエラーが報告されます。
3. DataWorks インポートツールの実行
コマンドラインから変換ツールを実行します。コマンドは次のとおりです:
sh ./bin/run.sh write \
-c ./conf/<your_config_file>.json \
-f ./data/2_ConverterOutput/<conversion_result_output_package>.zip \
-o ./data/4_WriterOutput/<import_result_storage_package>.zip \
-t dw-newide-writerコマンドでは、`-c` は設定ファイルのパスを指定し、`-f` は ConverterOutput パッケージのストレージパスを指定し、`-o` は WriterOutput パッケージのストレージパスを指定し、`-t` はサブミッションプラグイン名を指定します。
たとえば、プロジェクト A を DataWorks にインポートする場合:
sh ./bin/run.sh write \
-c ./conf/projectA_write.json \
-f ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-o ./data/4_WriterOutput/projectA_WriterOutput.zip \
-t dw-newide-writerインポートツールは、操作中にプロセス情報を出力します。プロセス中にエラーが発生していないか確認してください。インポートが完了すると、成功したインポートと失敗したインポートの統計がコマンドラインに出力されます。一部のノードのインポートに失敗しても、インポートプロセス全体には影響しないことに注意してください。少数のノードのインポートに失敗した場合は、DataWorks で手動で修正できます。
4. インポート結果の表示
インポートが完了したら、DataWorks で結果を表示できます。ワークフローが 1 つずつインポートされるのを監視することもできます。問題を発見し、インポートを停止する必要がある場合は、`jps` コマンドを実行して `BwmClientApp` を見つけ、`kill -9` コマンドを実行してインポートを停止できます。
5. よくある質問
5.1. ソースは継続的に開発されています。これらの増分や変更を DataWorks に送信するにはどうすればよいですか?
移行ツールは上書きモードで実行されます。エクスポート、変換、インポートのプロセスを再実行して、ソースからの増分変更を DataWorks に送信できます。ツールは完全なパスでワークフローを照合して、作成するか更新するかを決定することに注意してください。変更を移行するには、ワークフローを移動しないでください。
5.2. ソースは継続的に開発されており、DataWorks でもワークフローを修正・管理しています。増分移行は DataWorks 上の変更を上書きしますか?
はい、上書きされます。移行ツールは上書きモードで実行されます。移行が完了した後に、DataWorks でさらに修正を行うことを推奨します。あるいは、バッチで移行することもできます。移行されたワークフローのバッチが再度上書きされないことを確認した後、DataWorks での修正を開始できます。異なるバッチは互いに影響しません。
5.3. パッケージ全体のインポートに時間がかかりすぎます。一部だけをインポートすることはできますか?
はい、できます。インポートするパッケージを手動で切り取って、部分的なインポートを実行できます。`data/project/workflow` フォルダで、インポートする必要があるワークフローを保持し、その他を削除します。フォルダをパッケージに再圧縮してから、インポートツールを実行します。相互に依存関係のあるワークフローは一緒にインポートする必要があることに注意してください。そうしないと、ワークフロー間のノード系統が失われます。