背景情報
現在のベクトル検索のフィルタリングメカニズムでは、各ベクトルを走査した後にフィルタ結果を計算し、ベクトルがフィルタ条件を満たしているかどうかを判断します。フィルタ条件を満たさないベクトルは破棄されます。これにより、走査完了後にフィルタ条件を満たすベクトルのみが取得されます。ただし、ベクトル検索プロセスでは、固定数のベクトルがスキャンされます。デフォルトでは、ベクトルの1%がスキャンされます。フィルタ条件を満たすドキュメントがごくわずかしかない場合、結果の数が少なくなるか、結果がまったく得られない可能性があります。検索結果を改善するには、スキャン率を調整する必要があります。場合によっては、検索結果を得るためにすべてのデータをスキャンする必要があります。ただし、スキャン率を大幅に増やすと、クエリ時間が大幅に長くなります。
最適化の原則
フィルタ条件を満たすドキュメントがごくわずかしかない場合にベクトル検索で結果が得られない問題を解決するには、まずフィルタ条件を満たすドキュメントの数を見積もることから始めます。数が少ない場合は、フィルタ結果を直接使用してベクトルの類似度を計算できます。数が大きい場合は、ベクトル検索を再度実行します。次の図は、検索プロセスを示しています。
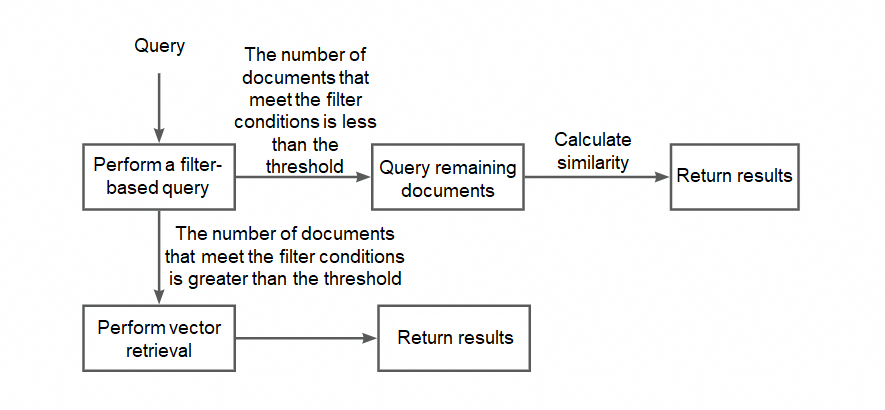
説明:転置インデックスを作成し、フィルタ式を解析してから、クエリを最適化します。
テキストフィールド以外のすべてのフィールドに対して、単一フィールドの転置インデックスを作成します。
フィルタ式を解析し、転置処理のために構文ツリーを走査します。
フィルタ条件 attrName = constValue の場合、attrName が転置インデックスが作成された属性フィールドであり、constValue が定数である場合、フィルタ条件を次の転置クエリ条件に書き換えます:attrName: constValue。
AND 条件:AND 条件の前後のフィルタ式を個別に処理します。フィルタ式を転置クエリ条件に書き換えることができる場合は、書き換えます。フィルタ式を転置クエリ条件に書き換えることができない場合は、元のフィルタ式を保持します。
OR 条件:OR 条件の前後のフィルタ式のいずれかを転置クエリ条件に書き換えることができない場合、クエリの書き換えは失敗します。この場合、ベクトル検索を直接実行します。
一部の関数の特別な処理:
in/contain:関数を OR インデックスクエリに書き換えます。
range:関数を範囲インデックスクエリに書き換えます。この機能は現在のバージョンではサポートされていません。
転置処理が完了すると、システムはクエリとフィルタ条件に基づいて、カスタマイズ可能な数の結果(例:500)を取得します。
返される結果が 500 未満の場合、それらはベクトルの類似度の計算に直接使用されます。
500 以上の結果が返された場合、システムは最後の結果のドキュメント ID が表すドキュメントセット全体の割合を評価します。
最後の結果のドキュメント ID がすべてのドキュメントのカスタマイズ可能な割合(例:80%)を超える場合、システムは一致する結果がごくわずかであると推測し、残りのドキュメントのクエリを続行します。最後に、システムはベクトルの類似度を計算します。
最後の結果のドキュメント ID がすべてのドキュメントの 80% 以下の場合、ベクトル検索結果が使用されます。
サンプルコード
たとえば、100 万個のドキュメントがあり、そのうち 600 個のドキュメントが count=1 条件を満たしているとします。フィルタの最適化を有効にした後、prefetch_size を 500 に、prefetch_coverage を 0.8 に設定します。次のクエリを実行します。
{
"vector": [0.1, 0.2, 0.3],
"topK": 10,
"namespace": "123",
"filter": "count = 1 ",
"searchParams": "{\"vector_service.search.enable_filter_optimize\":true}"
}事前クエリ:システムは、count=1 を転置クエリ条件として使用して 600 個のドキュメントを取得します。数値 600 は 500 より大きいです。この場合、システムは割合の計算に進みます。
割合の計算:システムは、500 番目の結果のドキュメント ID が表すドキュメントセット全体の割合を評価します。割合が 80% を超える場合、システムは残りのドキュメントのクエリを続行します。割合が 80% を超えない場合、ベクトル検索結果が使用されます。
パラメータ
システムは、フィルタリングに転置インデックスを使用するためにクエリを実行する必要があります。条件を満たさないドキュメントがごくわずかしか除外されない場合、クエリ時間が長くなります。この問題を解決するために、フィルタの最適化を有効にするかどうかを指定するパラメータが使用されます。
パラメータ | デフォルト値 | 説明 |
vector_service.search.enable_filter_optimize | false | フィルタの最適化を有効にするかどうかを指定します。デフォルト値:false。値 true は、フィルタの最適化が有効になっていることを指定します。値 false は、フィルタの最適化が無効になっていることを指定します。 |
vector_service.search.filter_optimize_prefetch_size | 500 | デフォルト値:500。判断のために事前に取得する結果の数。 |
vector_service.search.filter_optimize_prefetch_coverage | 0.8 | デフォルト値:0.8。事前に取得された最後の結果のドキュメント ID が表すドキュメントセット全体の割合のしきい値。割合がしきい値以上の場合、転置処理結果が使用されます。 |
サンプルコード:
{
"vector": [0.1, 0.2, 0.3],
"topK": 10,
"namespace": "123",
"filter": "count = 1 AND tag=\"text\"",
"searchParams": "{\"vector_service.search.enable_filter_optimize\":true}"
}フィルタの解析
AND
count = 1 AND tag = "text"書き換え結果(クエリ文字列を使用して表されます。実際には構文ツリーです)
QUERY: count:'1' AND tag:'text'
FILTER: NoneAND 部分
tag = 'text' AND count > 1次のように書き換えます
QUERY: tag:'text'
FILTER: count > 1OR
count = 1 OR tag = "text"次のように書き換えます
QUERY: count:'1' OR tag:'text'
FILTER: NoneOR 部分
tag = 'text' OR count > 1書き換えに失敗しました。
in/contain
in(tag, 'text|image')次のように書き換えます
QUERY: tag:'text' OR tag:'image'