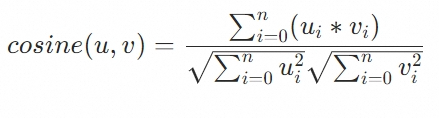このトピックでは、OpenSearch Vector Search Edition でサポートされているベクトルインデックスタイプについて説明します。
ベクトル取得の概要
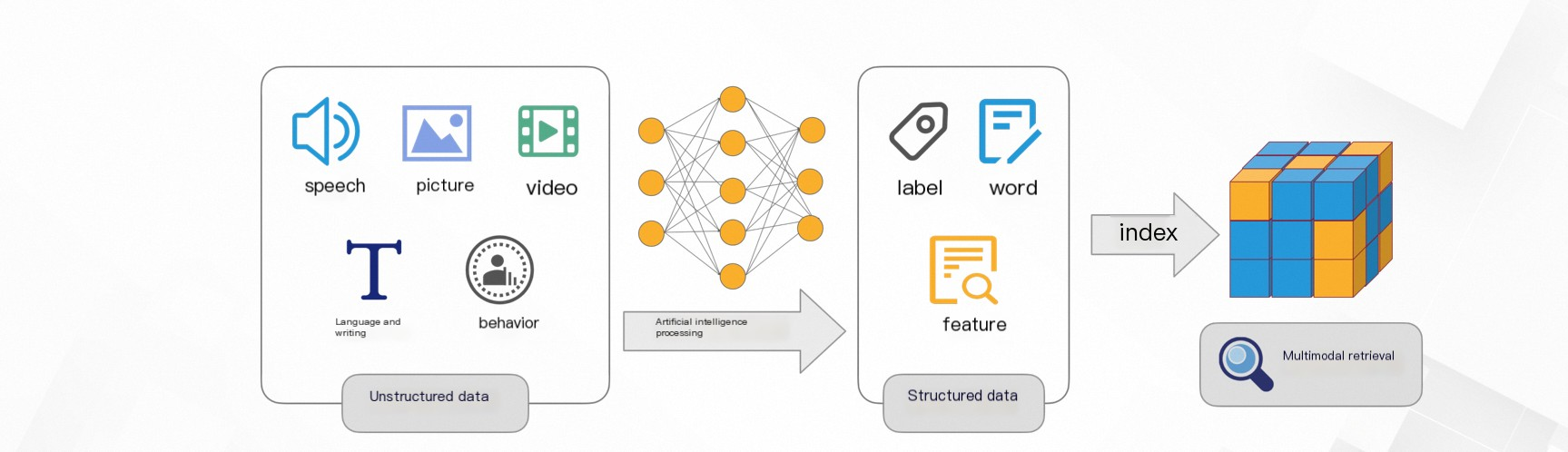
情報化時代において、データはテキスト、画像、動画、音声など、複数のモダリティで存在します。このマルチモーダルデータは、テキストでは伝えきれない詳細、例えば色、形、動き、音、空間的関係などを伝えることができます。

情報のモダリティも、さまざまな分野で多様化しています。

マルチモーダルシナリオでは、情報は構造化と非構造化の 2 つのカテゴリに分類されます。
非構造化データは、コンピュータが理解するのが難しいことがよくあります。テキストのトークン化に依存する従来の取得方法では、さまざまな分野での検索要求を満たすことができません。ベクトル検索は、この問題に対する理想的なソリューションです。
では、ベクトルとは何で、ベクトル取得はどのように機能するのでしょうか?
物理世界の非構造化データは、多次元ベクトルに変換されます。これらのベクトルは、エンティティとそれらの間の関係を表します。
次に、ベクトル間の距離が計算されます。通常、距離が小さいほど類似性が高いことを示します。システムは最も類似した結果を取得して検索を完了します。
アルゴリズム
linear
線形アルゴリズムは、すべてのベクトルデータの距離を線形に計算します。
シナリオ: 100% の取得率が必要な場合は、このアルゴリズムを使用します。
デメリット: このアルゴリズムは非効率的であり、大量のデータを処理する際に CPU やメモリなどのリソースを大量に消費します。
クラスタリング
Quantized Clustering
概要:
Quantized Clustering は、Alibaba が k-means クラスタリングに基づいて開発したベクトル取得アルゴリズムです。このアルゴリズムは、まずベクトルドキュメントを n 個の重心にクラスタリングします。次に、各ドキュメントを最も近い重心に割り当て、n 個の転置リストを構築します。これら n 個の重心と対応する転置リストが、Quantized Clustering (QC) インデックスの主要な内容を構成します。取得中、クエリはまず重心のサブセットとの距離を計算し、最も近いものを選択します。次に、クエリは選択された重心の転置リスト内のドキュメントとの距離を計算します。最後に、クエリに最も近い上位 k 個のドキュメントを返します。
特筆すべきは、QC が fp16 および int8 の数値量子化をサポートしていることです。これにより、インデックスサイズを削減し、取得パフォーマンスを向上させることができます。ただし、これにより取得率がわずかに低下する可能性があります。要件に応じてこの機能を設定できます。
QC アルゴリズムは、リアルタイムデータシナリオや、GPU リソースがあり低待機時間が要求されるシナリオに適しています。
パラメータ調整:
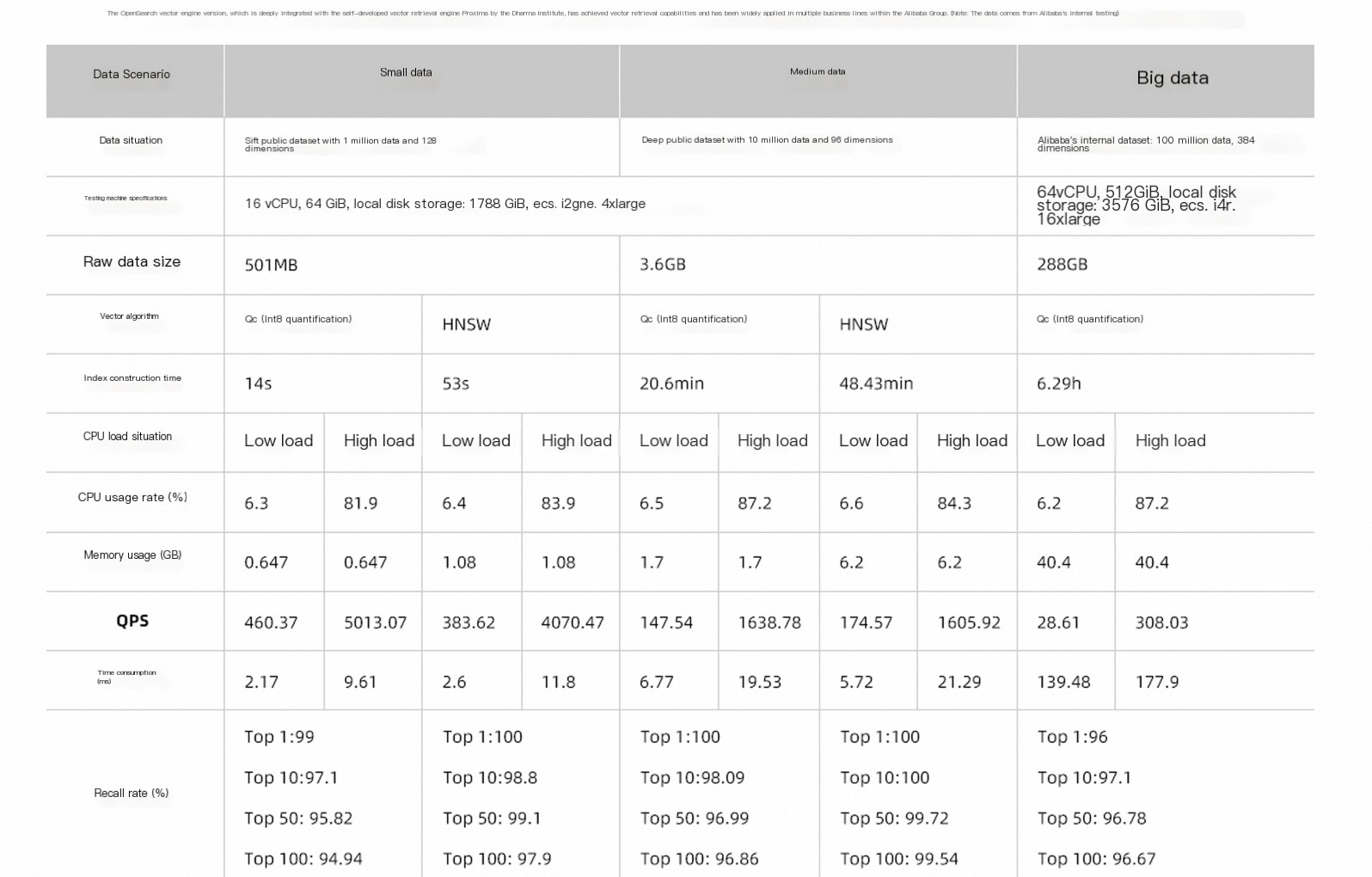
パフォーマンス比較:
HNSW
概要:

Hierarchical Navigable Small World (HNSW) は、近接グラフに基づくベクトル取得アルゴリズムです。まず、互いに近いベクトル間にエッジが作成される近接グラフを構築します。ベクトルとその近接情報が HNSW インデックスの主要な内容を構成します。取得中、検索はエントリーノードから開始されます。クエリとエントリーノードのすべての隣接ノードとの距離を計算し、次に走査するノードとして最も近い隣接ノードを選択します。このプロセスは、検索が収束するまで繰り返されます。収束は、現在のノードのどの隣接ノードも、すでに見つかった最も近いノードよりもクエリに近くない場合に発生します。
収束を高速化するために、HNSW はスキップリストクエリのロジックに似た多層近接グラフ構造を構築します。取得プロセスは最上位レイヤーから始まり、下位レイヤーへと移動します。取得ロジックは各レイヤーで類似していますが、レイヤー 0 ではわずかな違いがあります。走査がレイヤー k のノードに収束した後、そのノードがレイヤー k-1 のエントリーポイントとなり、走査が続行されます。レイヤー k は、レイヤー k-1 よりもノードがまばらで、ノード間の距離が大きくなっています。これにより、レイヤー k での走査中に、より大きなステップサイズでより高速な反復が可能になります。
パラメータ調整:
QGraph
概要:
Quantized Graph (QGraph) は、OpenSearch が HNSW に基づいて開発した改良アルゴリズムです。インデックス構築中に、グラフインデックスを構築する前に生データを自動的に量子化します。HNSW と比較して、QGraph はインデックスサイズとメモリオーバーヘッドを大幅に削減でき、インデックスを元のサイズの 8 分の 1 まで小さくすることができます。さらに、整数計算に CPU 命令の最適化を使用することで、QGraph のパフォーマンスは HNSW の数倍向上します。量子化後、ベクトルの識別性が低下するため、QGraph の取得率は HNSW よりも低くなります。実際のシナリオでは、より多くの結果を取得することでこの効果を軽減できます。
QGraph は、データの int4、int8、および int16 量子化をサポートしています。量子化レベルが異なると、ベクトルインデックスのメモリ使用量、クエリパフォーマンス、および取得率に異なる影響を与えます。一般的に、整数ビット幅が小さいほど、ベクトルインデックスのメモリフットプリントは小さくなり、パフォーマンスは高くなりますが、取得率は低くなります。基盤となる CPU 命令セットの性質上、int16 量子化は非量子化データとほぼ同じパフォーマンスと取得率を持ちます。
パラメータチューニング:
CAGRA
概要:
CUDA ANN GRAph-based (CAGRA) は、近接グラフに基づくベクトル取得アルゴリズムです。NVIDIA GPU に最適化されており、高い同時実行性とバッチリクエストを伴うシナリオに適しています。
HNSW とは異なり、CAGRA は並列計算を容易にするために単一層の近接グラフのみを構築します。クエリ中、アルゴリズムは順序付けられた候補セットを反復的に維持します。各反復で、候補セットから上位 k 個のノードを検索開始点として選択し、それらの隣接ノードでセットを更新しようとします。このプロセスは、候補セット内のすべての上位 k 個のノードが検索開始点として使用されるまで続き、その時点でアルゴリズムは収束します。
CAGRA アルゴリズムは、single-CTA と multi-CTA の 2 つのポリシーで実装されています。single-CTA ポリシーは、単一のベクトルクエリを単一のスレッドブロックにマッピングし、大きなバッチサイズに対して効率的です。multi-CTA ポリシーは、複数のスレッドブロックを使用して単一のベクトルクエリを実行します。このポリシーは、GPU の並列計算能力をより有効に活用し、バッチサイズが小さい場合に高い取得率を達成します。ただし、バッチサイズが大きい場合のスループットは single-CTA ポリシーよりも低くなります。システムは、実行時にワークロードに基づいて最適なポリシーを自動的に選択します。
パラメータチューニング:
DiskANN
概要:
DiskANN は、非常に大規模なデータセットを処理するために設計されたディスクベースの近似最近傍 (ANN) 検索技術です。Vamana グラフアルゴリズムを使用して、利用可能なメモリを超えるデータセットに対してディスクストレージを効率的に使用し、パフォーマンス専有型のベクトルインデックス作成と取得を維持します。
DiskANN アルゴリズムは、データノードファミリーが SSD の場合にのみサポートされます。
パラメータチューニング:
CagraHnsw
概要:
CagraHnsw は、OpenSearch が開発したベクトル取得アルゴリズムです。CAGRA と HNSW アルゴリズムの利点を組み合わせ、大規模なデータセットに対して迅速なインデックス構築が必要なシナリオに適しています。
CagraHnsw アルゴリズムは、インデックス構築フェーズでは CAGRA に似ています。GPU を使用してインデックスを構築し、インデックスファイルを HNSW アルゴリズムと互換性のあるフォーマットに変換します。取得フェーズでは、CPU 上の HNSW アルゴリズムが検索を実行します。この戦略は、CAGRA の効率的な GPU ベースのインデックス構築と、コスト効率の高い CPU ベースの取得を組み合わせたものです。このアプローチにより、取得時に高価な GPU インスタンスが不要になります。その結果、CagraHnsw は、持続的な高同時実行性クエリを必要としないシナリオにおいて、CAGRA よりもコスト効率が高くなります。
ベクトル距離タイプ
ベクトル取得は、ベクトル間の類似性を計算し、最も類似した上位 k 個のベクトルを返すことによって機能します。このプロセスでは、類似性は距離を計算することによって決定されます。通常、距離スコアが小さいほどベクトルが近く、スコアが大きいほど遠いことを示します。

異なるベクトル空間では、ベクトル間の距離を計算するために異なる距離メトリックが使用されます。OpenSearch Vector Search Edition は、二乗ユークリッド距離、内積、コサイン距離のメトリックをサポートしています。
二乗ユークリッド距離 (SquareEuclidean)
ユークリッド距離は、最も一般的な距離メジャーの 1 つで、2 つのベクトル間の直線距離を表します。これは、それらの座標間の差の二乗和の平方根を取ることによって計算されます。ユークリッド距離が小さいほど、2 つのベクトルはより類似していることを示します。ユークリッド距離の数式は次のとおりです。
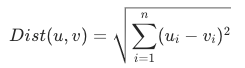
内積距離 (InnerProduct)
内積は、2 つのベクトルのドット積またはスカラー積です。内積の結果が大きいほど、ベクトル間の類似性が高いことを示します。これは、2 つのベクトルの対応する要素を乗算し、その積を合計することによって計算されます。内積メトリックは、検索および推奨シナリオで一般的です。内積メトリックを使用するかどうかの選択は、通常、アルゴリズムが内積モデルを使用するかどうかに依存します。内積の数式は次のとおりです。

コサイン距離
コサイン距離は、2 つのベクトル間の角度のコサインに基づいて、それらの類似性を測定します。結果の値の範囲は -1 から 1 です。値が 1 の場合は、ベクトルが同じ方向を向いていることを示し、最高の類似性を表します。値が -1 の場合は、反対方向を向いていることを示し、最低の類似性を表します。値が 0 の場合は、ベクトルが垂直であることを示します。値が 1 に近いほど、ベクトルはより類似しています。このメトリックは、テキスト類似性取得シナリオでよく使用されます。数式は次のとおりです。