概要
各ドキュメントには複数のフィールドが含まれ、各フィールドには一連の単語が含まれています。インデックスは、データの取得を高速化するために使用されます。インデックスは、マッピングに基づいて異なるタイプに分類できます。次のセクションでは、インデックスに関するいくつかの概念について説明します。
フィールド: フィールドの名前とタイプを使用して、インデックステーブルを定義できます。
転置インデックス: インデックスは、単語からドキュメント内の場所へのマッピングを格納します。例:単語A:(Doc1、Doc2、...、DocN)。転置インデックスはデータの取得に使用され、検索するキーワードを含むドキュメントを見つけるのに役立ちます。
順方向インデックス: インデックスは、ドキュメントからフィールドへのマッピングを格納します。例:DocID(term1、term2、... termn)。順方向インデックスは、単一値インデックスと複数値インデックスに分類できます。単一値インデックスには、単一値属性のみに属するデータ値が含まれています。データ値は、Stringタイプの値を除いて、固定長です。これにより、データクエリが効率的になります。インデックスデータを更新することもできます。複数値属性は、フィールドに数量が固定されていない複数のデータが含まれていることを示します。これはクエリのパフォーマンスに悪影響を及ぼします。インデックスデータを更新することはできません。
順方向インデックスは、ドキュメントIDに基づいてデータの属性を取得するために使用されます。属性は、統計、ソート、およびフィルタリングに使用できます。OpenSearch Vector Search Editionは、順方向インデックスの次のデータ型をサポートしています。
INT8(8ビット符号付き整数型)およびUINT8(8ビット符号なし整数型)
INT16(16ビット符号付き整数型)
UINT16(16ビット符号なし整数型)
INTEGER(32ビット符号付き整数型)
UINT32(32ビット符号なし整数型)およびINT64(64ビット符号付き整数型)
UINT64(64ビット符号なし整数型)
FLOAT(32ビット浮動小数点数)
DOUBLE(64ビット浮動小数点数)
STRING(文字列型)
サマリーインデックス: インデックスは、順方向インデックスと同様の方法でデータを格納します。ただし、サマリーインデックスは、フィールドからドキュメントへのマッピングを格納します。サマリーインデックスを使用すると、ドキュメントIDに基づいてコンテンツをすばやく見つけることができます。サマリーインデックスは、検索結果を表示するために使用されます。サマリーインデックスには、大量のデータが含まれています。クエリごとに、サマリーインデックスの過剰な量のデータを取得する必要はありません。代わりに、サマリーインデックスに基づいてドキュメントから検索結果を取得するだけで済みます。OpenSearch Vector Search Editionは、サマリーインデックスの圧縮メカニズムを提供します。スキーマでサマリーインデックスの圧縮を有効にすると、OpenSearch Vector Search Editionはzlibを使用してサマリーインデックスを圧縮し、圧縮されたサマリーインデックスを格納します。OpenSearch Vector Search Editionがサマリーインデックスからデータを読み取ると、検索エンジンは圧縮されたサマリーインデックスを解凍し、取得した結果をユーザーに返します。
インデックステーブルの設定方法の詳細については、インデックステーブルの設定を参照してください。
インデックススキーマの例:
{
"summarys": {
"summary_fields": [
"pk",
"embedding",
"cate_id"
],
"parameter": {
"file_compressor": "zstd"
}
},
"indexs": [
{
"index_name": "id",
"index_type": "PRIMARYKEY64",
"index_fields": "pk",
"has_primary_key_attribute": true,
"is_primary_key_sorted": false
},
{
"index_name": "vector",
"index_type": "CUSTOMIZED",
"index_fields": [
{
"field_name": "pk",
"boost": 1
},
{
"field_name": "cate_id",
"boost": 1
},
{
"field_name": "embedding",
"boost": 1
}
],
"parameters": {
"dimension": "128",
"distance_type": "SquaredEuclidean",
"vector_index_type": "Qc",
"build_index_params": "{\"proxima.qc.builder.quantizer_class\":\"Int8QuantizerConverter\",\"proxima.qc.builder.quantize_by_centroid\":true,\"proxima.qc.builder.optimizer_class\":\"BruteForceBuilder\",\"proxima.qc.builder.thread_count\":10,\"proxima.qc.builder.optimizer_params\":{\"proxima.linear.builder.column_major_order\":true},\"proxima.qc.builder.store_original_features\":false,\"proxima.qc.builder.train_sample_count\":3000000,\"proxima.qc.builder.train_sample_ratio\":0.5}",
"search_index_params": "{\"proxima.qc.searcher.scan_ratio\":0.01}",
"embedding_delimiter": ",",
"major_order": "col",
"linear_build_threshold": "5000",
"min_scan_doc_cnt": "20000",
"enable_recall_report": "false",
"is_embedding_saved": "false",
"enable_rt_build": "false",
"builder_name": "QcBuilder",
"searcher_name": "QcSearcher"
},
"indexer": "aitheta2_indexer"
}
],
"attributes": [
{
"field_name": "pk",
"file_compress": "no_compressor"
},
{
"field_name": "embedding",
"file_compress": "no_compressor"
},
{
"field_name": "cate_id",
"file_compress": "file_compressor"
}
],
"fields": [
{
"user_defined_param": {},
"field_name": "pk",
"field_type": "INTEGER",
"compress_type": "equal"
},
{
"user_defined_param": {
"multi_value_sep": ","
},
"field_name": "embedding",
"field_type": "FLOAT",
"compress_type": "uniq",
"multi_value": true
},
{
"user_defined_param": {},
"field_name": "cate_id",
"field_type": "INTEGER",
"compress_type": "equal"
},
{
"field_name": "titile",
"field_type": "TEXT",
"analyzer": "chn_ecommerce_general"
}
],
"file_compress": [
{
"name": "file_compressor",
"type": "zstd"
},
{
"name": "no_compressor",
"type": ""
}
]
}インデックステーブルを追加する
インスタンスの詳細ページで、構成センター > インデックススキーマを選択し、インデックステーブルの作成をクリックします。
インデックステーブルを構成します。「テンプレートを選択」セクションで「共通テンプレート」を選択します。

インデックステーブル: カスタム名を入力します。
データソース: ビジネス要件に基づいてデータソースを選択します。
データシャード: 購入したSearcherワーカーの数以下の値を入力します。
フィールドを構成します。少なくとも2つのフィールドを指定する必要があります。主キーフィールドとベクトルフィールドです。ベクトルフィールドは、複数値FLOATデータ型である必要があります。
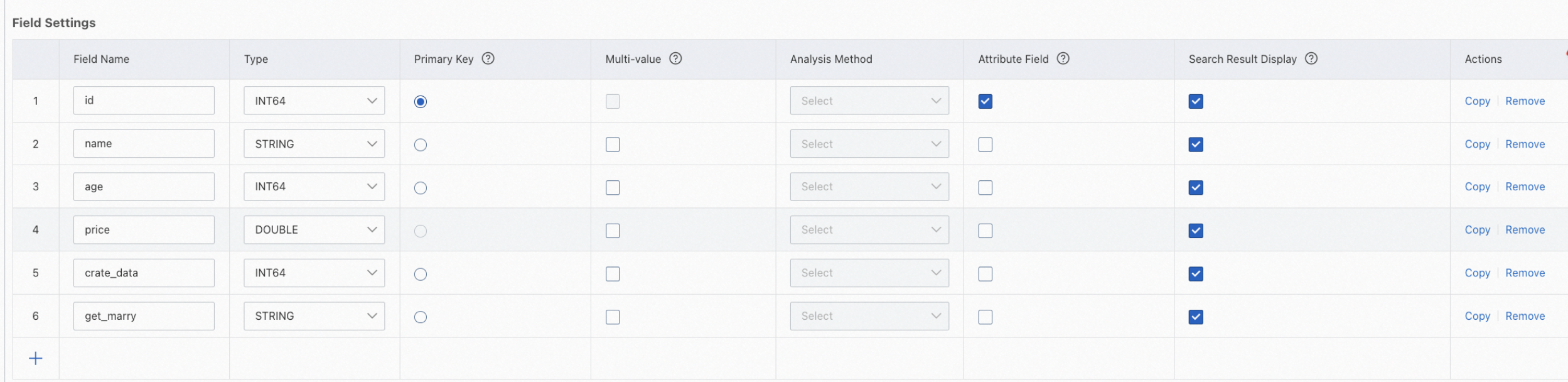
カテゴリを持つベクトルインデックスを構成する場合、主キーフィールドとベクトルフィールドの間にカテゴリフィールドを追加できます。カテゴリフィールドは、INTEGERデータ型の単一値または複数値フィールドである必要があります。
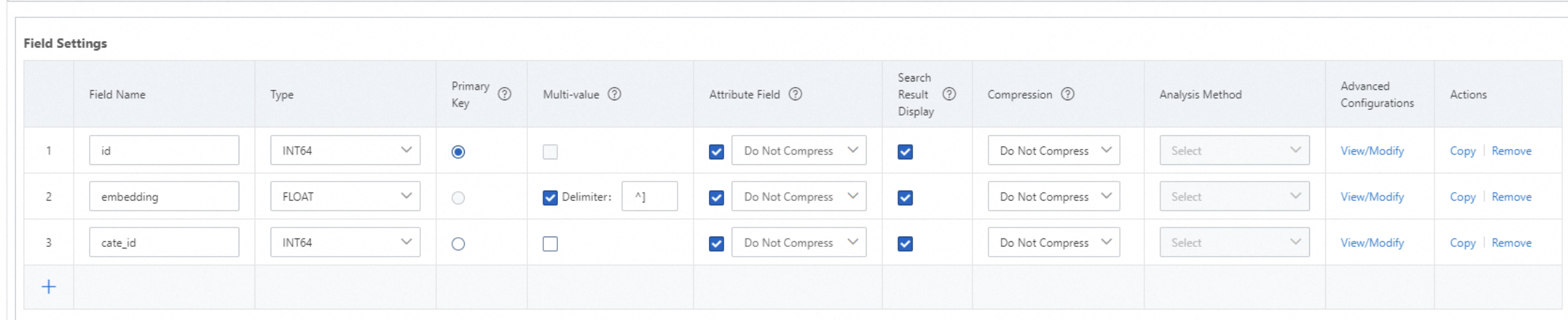
属性フィールドとフィールドデータを圧縮するかどうかを指定します:
属性フィールド: デフォルトでは、属性フィールドは圧縮されません。属性フィールドにfile_compressorが選択されている場合、属性フィールドは圧縮されます。
フィールドデータ: デフォルトでは、フィールドデータは圧縮されません。複数値フィールドまたはSTRINGタイプのフィールドの場合、デフォルトでuniqが選択されます。単一値フィールドの場合、デフォルトでequalが選択されます。
ベクトルインデックスを構成する際は、主キーフィールド、カテゴリフィールド、ベクトルフィールドの順にフィールドを指定する必要があります。カテゴリフィールドはオプションです。前の図は例を示しています。
属性フィールドを圧縮する場合は、パフォーマンスへの影響を軽減するために、インデックスのロード方法を変更することをお勧めします。インデックスのロード方法を変更するには、次の操作を実行します。インスタンスのインスタンス詳細ページで、「デプロイメント管理」をクリックします。表示されるページで、管理するSearcherワーカーをクリックします。「Searcherワーカーの構成」パネルで、「オンライントレーブルの構成」タブをクリックします。
インデックスを構成します。主キーインデックスのタイプをPRIMARYKEY64に設定し、ベクトルインデックスのタイプをCUSTOMIZEDに設定する必要があります。

インデックスフィールドを圧縮するかどうかを指定します:
デフォルトでは、インデックスフィールドは圧縮されません。インデックスフィールドにfile_compressorが選択されている場合、インデックスフィールドは圧縮されます。
主キーインデックスは圧縮できません。
インデックスフィールドを圧縮する場合は、パフォーマンスへの影響を軽減するために、インデックスのロード方法を変更することをお勧めします。インデックスのロード方法を変更するには、次の操作を実行します。インスタンスのインスタンス詳細ページで、「デプロイメント管理」をクリックします。表示されるページで、管理するSearcherワーカーをクリックします。「Searcherワーカーの構成」パネルで、「オンライントレーブルの構成」タブをクリックします。
4.1. ベクトルインデックスに含まれるフィールドを指定します。
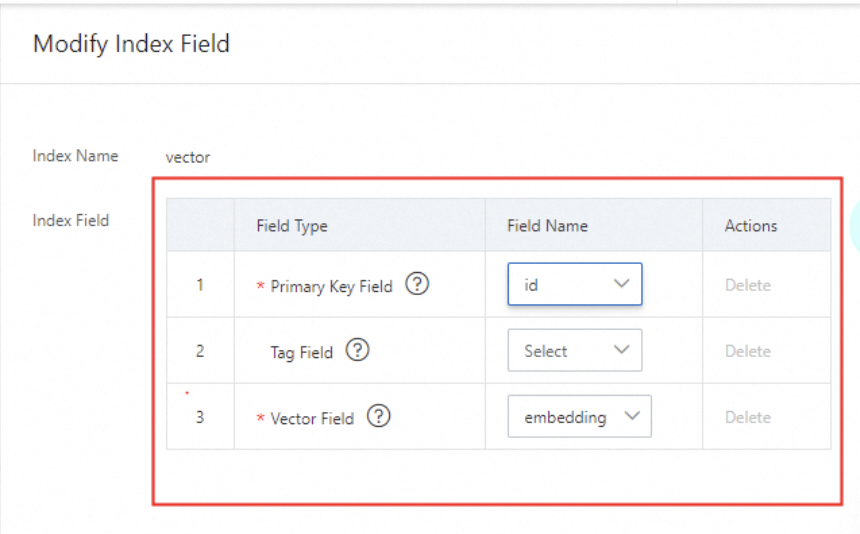
主キーフィールドとベクトルフィールドは必須です。カテゴリフィールドはオプションであり、空のままにすることができます。
3つの固定フィールドのみを選択でき、新しいフィールドを追加することはできません。
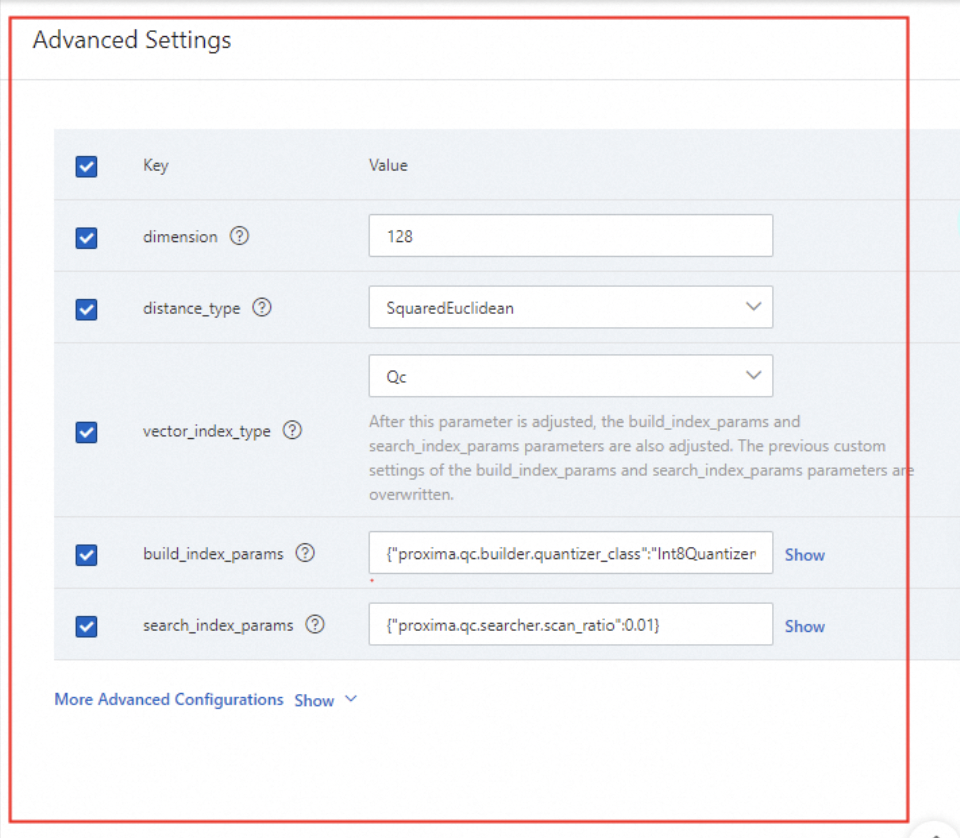
4.2. 詳細設定を構成します。ベクトルインデックスのパラメータを構成する必要があります。次の図は例を示しています。詳細については、ベクトルインデックスを参照してください。
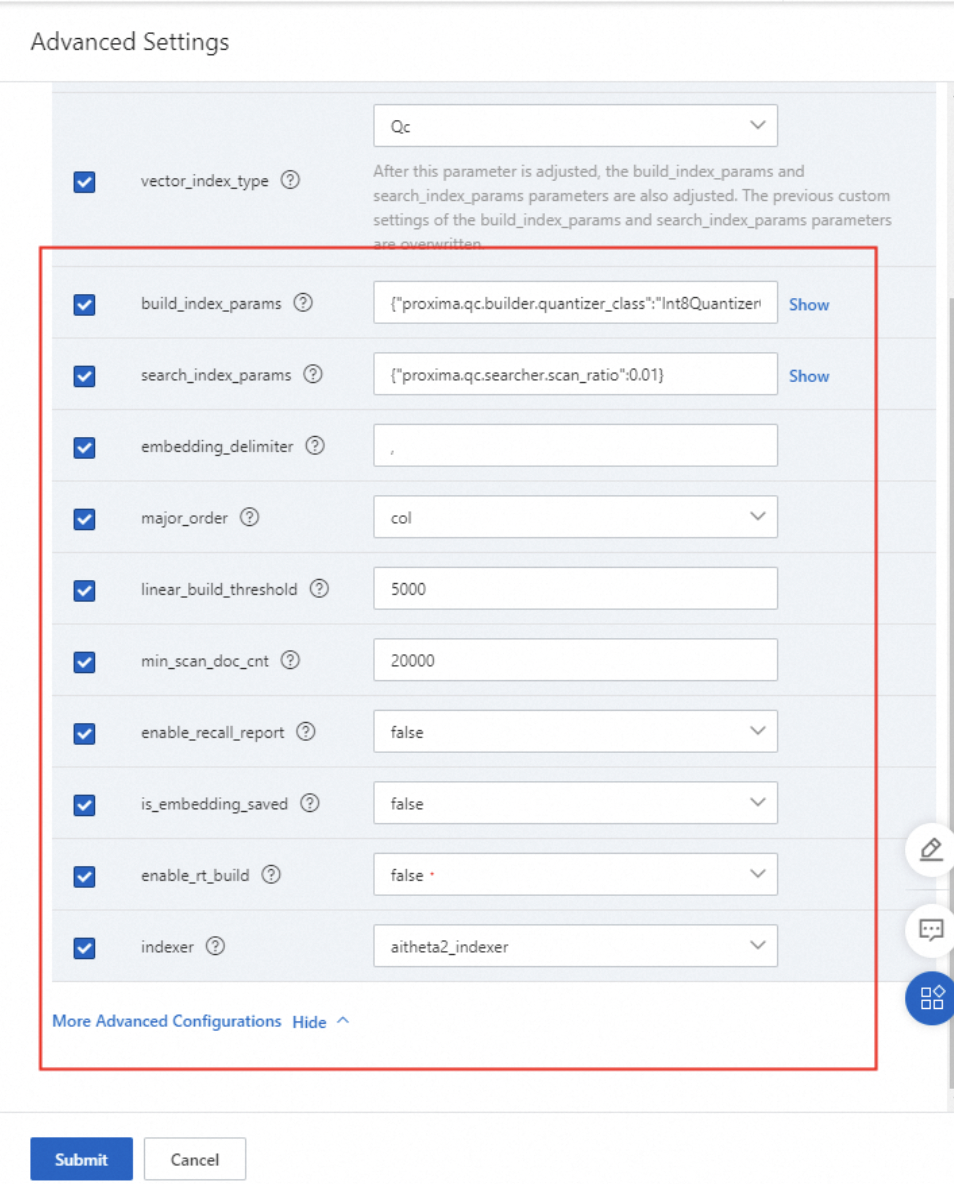
次の図は、さらに多くのパラメータを示しています。
次のサンプルコードは、build_index_paramsパラメータの設定方法の例を示しています。
{
"proxima.qc.builder.quantizer_class": "Int8QuantizerConverter", // 量子化クラス
"proxima.qc.builder.quantize_by_centroid": true, // 重心による量子化
"proxima.qc.builder.optimizer_class": "BruteForceBuilder", // 最適化クラス
"proxima.qc.builder.thread_count": 10, // スレッド数
"proxima.qc.builder.optimizer_params": {
"proxima.linear.builder.column_major_order": true // 列優先順序
},
"proxima.qc.builder.store_original_features": false, // 元の特徴量の保存
"proxima.qc.builder.train_sample_count": 3000000, // トレーニングサンプル数
"proxima.qc.builder.train_sample_ratio": 0.5 // トレーニングサンプル比率
}次のサンプルコードは、search_index_paramsパラメータの設定方法の例を示しています。
{
"proxima.qc.searcher.scan_ratio": 0.01 // スキャン比率
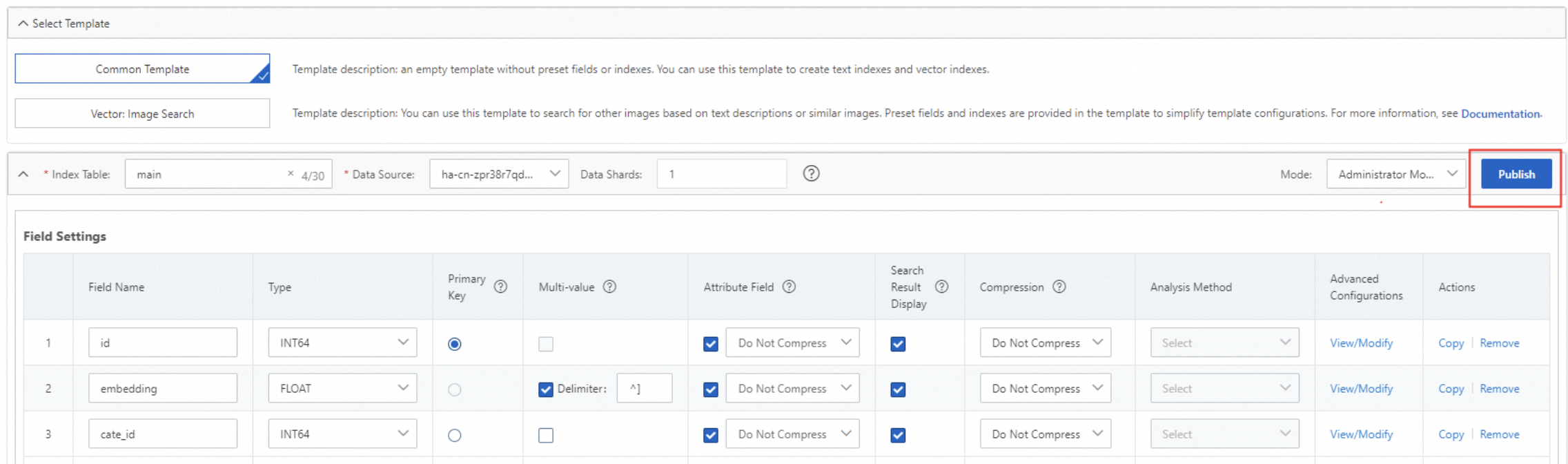
}構成が完了したら、「バージョンを保存」をクリックします。表示されるダイアログボックスで、説明を入力し、公開をクリックします。説明はオプションです。
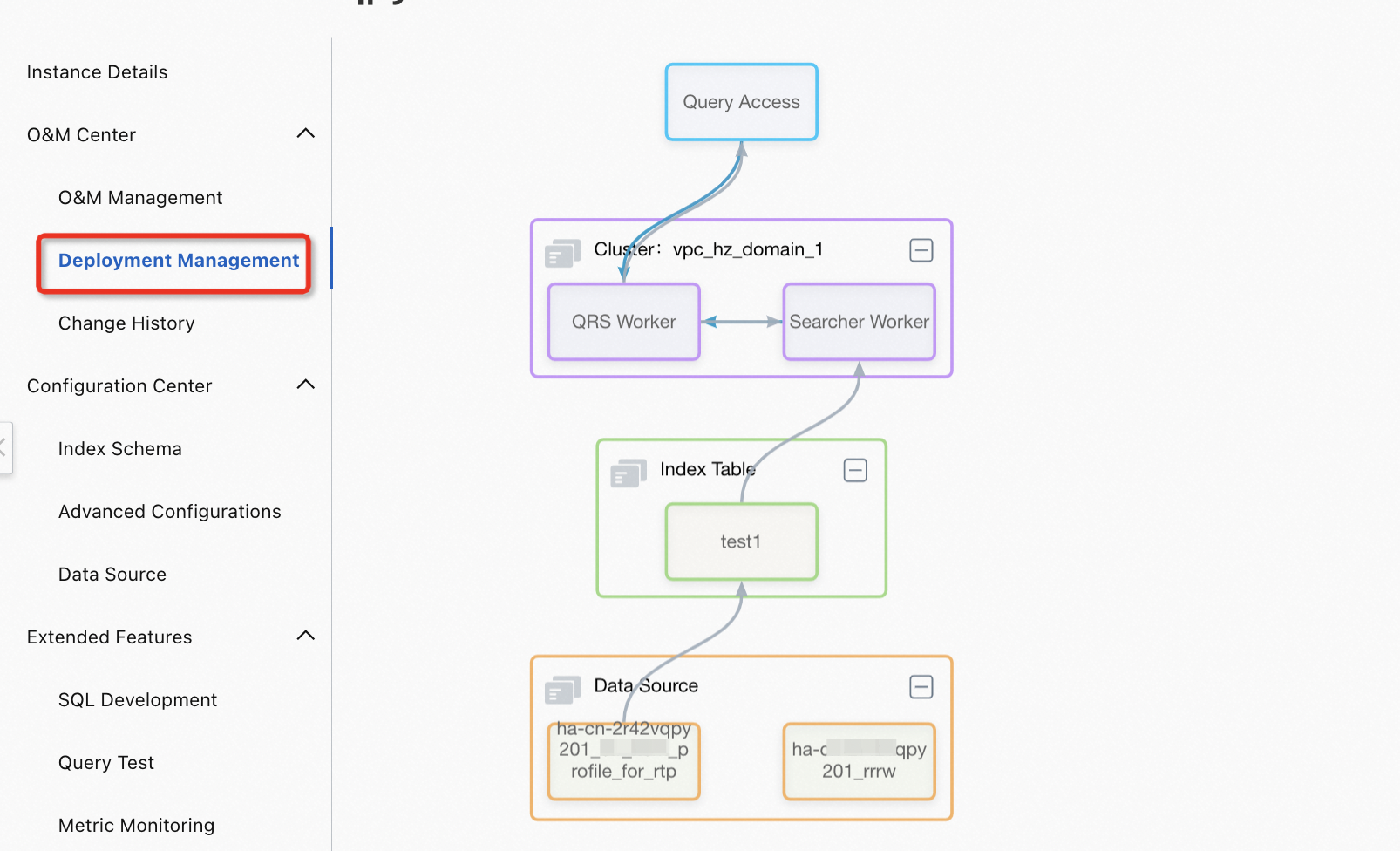
インデックステーブルが追加された後、O&Mセンター > デプロイメント管理を選択してトポロジを表示できます。
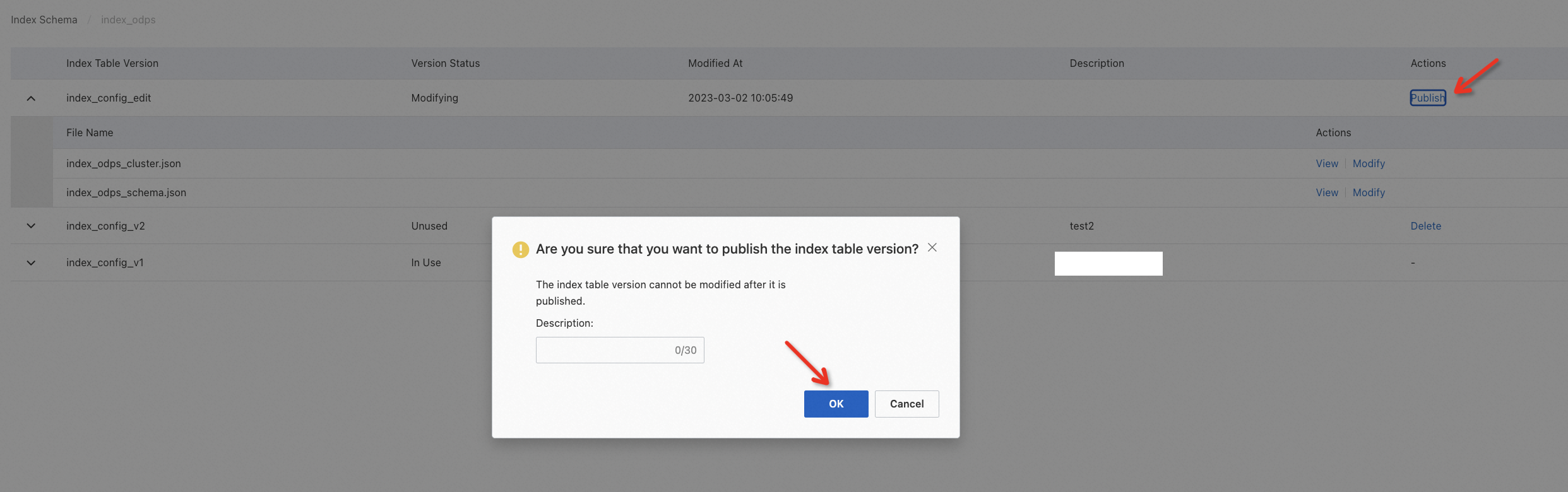
新しいインデックステーブルをクラスターで有効にする場合は、O&Mセンター > O&M管理を選択して、手動で再インデックス化をトリガーします。
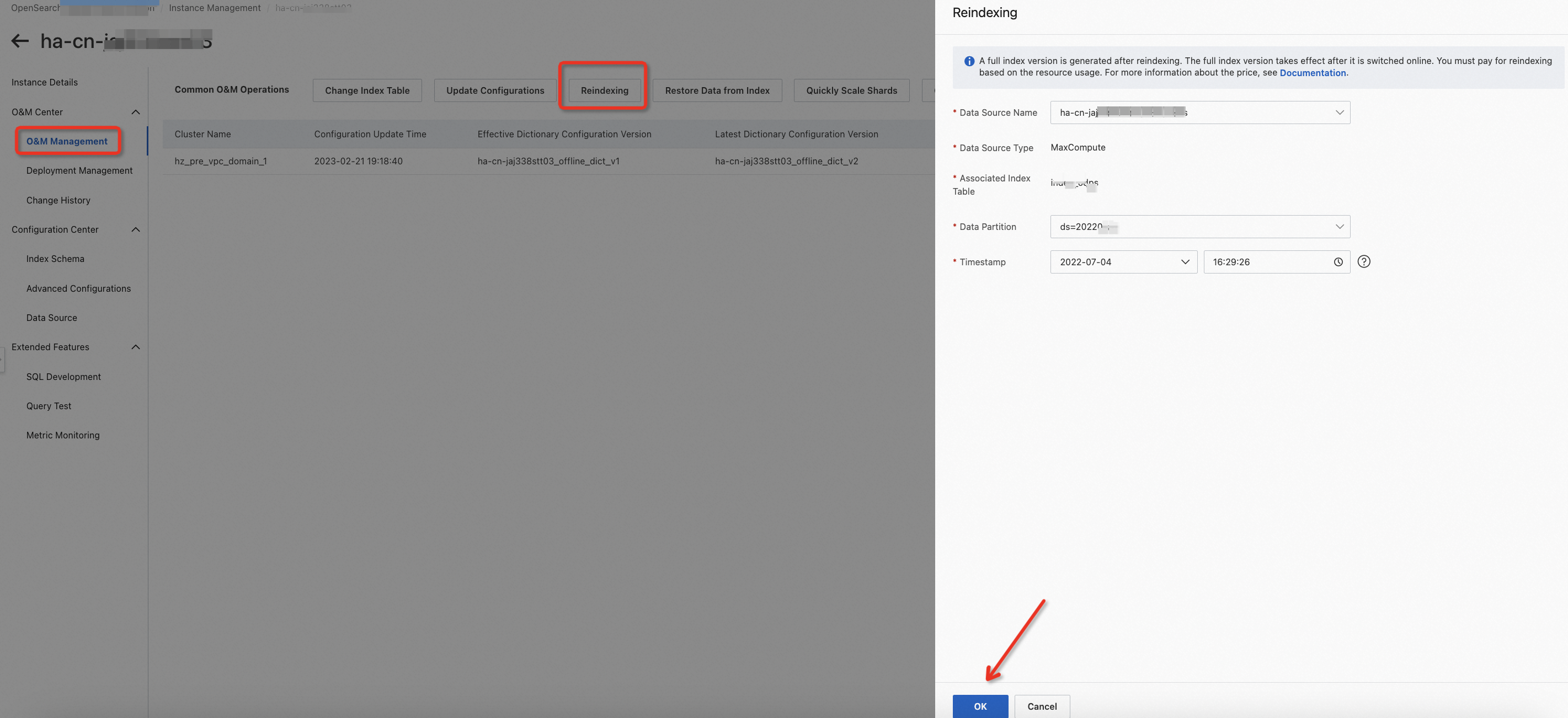
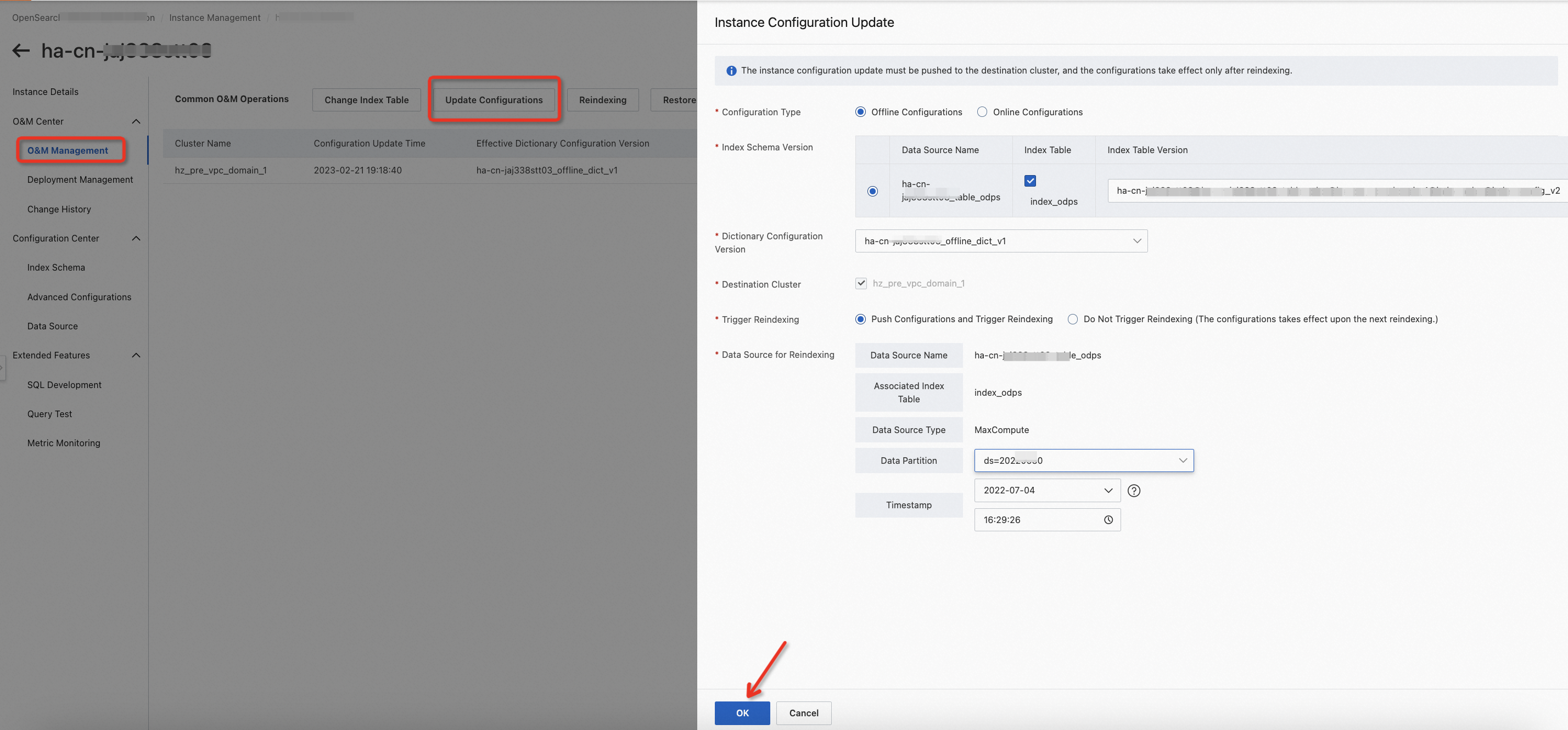
また、次の操作を実行して、この手順を完了することもできます。O&Mセンター > O&M管理を選択し、「構成の更新」をクリックして、表示されるパネルで「構成のプッシュと再インデックス化のトリガー」を選択します。
再インデックス化中に、O&Mセンター > 変更履歴を選択し、データソースの変更タブをクリックして、再インデックス化タスクの進捗状況を表示できます。

再インデックス化タスクが完了すると、新しいインデックステーブルからデータをクエリできます。
主キーフィールドは1つだけ指定できます。
フィールド設定では、少なくとも1つのフィールドに対して「検索結果表示」を選択する必要があります。
TEXTタイプのフィールドの場合、分析方法を設定する必要があります。複数値フィールドはサポートされていません。
主キーインデックスは1つだけ指定できます。
デフォルトの区切り文字に加えて、複数値フィールドを区切るために使用される区切り文字は、単一文字のみ可能です。全角文字はサポートされていません。
クラスター内のレプリカ数が2の場合、「データシャード」パラメータを2に設定します。インスタンスを購入する際は、Searcherワーカーの数が、レプリカ数にデータシャード数を掛けた値よりも大きいことを確認してください。そうでない場合、追加したインデックステーブルは使用できません。
単一シャードには、最大0.6億個のデータ(合計最大21億個)を含めることができます。単一シャードのインデックスサイズは300 GBを超えることはできません。データをリアルタイムで更新する必要がある場合、単一シャードでのデータ更新の1秒あたりのトランザクション数(TPS)の合計は4,000を超えることはできません。addコマンドを実行してドキュメントを追加する場合、更新TPSは10,000に達する可能性があります。
インデックステーブルを変更する
インデックステーブルバージョンの紹介:
デフォルトでは、新しく作成されたインデックステーブルには2つのバージョンが使用可能です。
index_config_v1: 初めて構成するインデックステーブル。構成をプッシュしてインデックスを再構築した場合、インデックステーブルのステータスは「使用中」に変わります。構成をプッシュしていないか、インデックスを再構築していない場合、インデックステーブルのステータスは「未使用」に変わります。
index_config_edit: 変更中のインデックステーブル。インデックステーブルは「変更中」状態です。
インデックステーブルのバージョンが連続して公開されている場合、バージョン番号は増分されます。たとえば、2番目のバージョンはindex_config_v2という名前になり、3番目のバージョンはindex_config_v3という名前になります。インデックステーブルのバージョンを区別するには、各バージョンの説明を入力する必要があります。
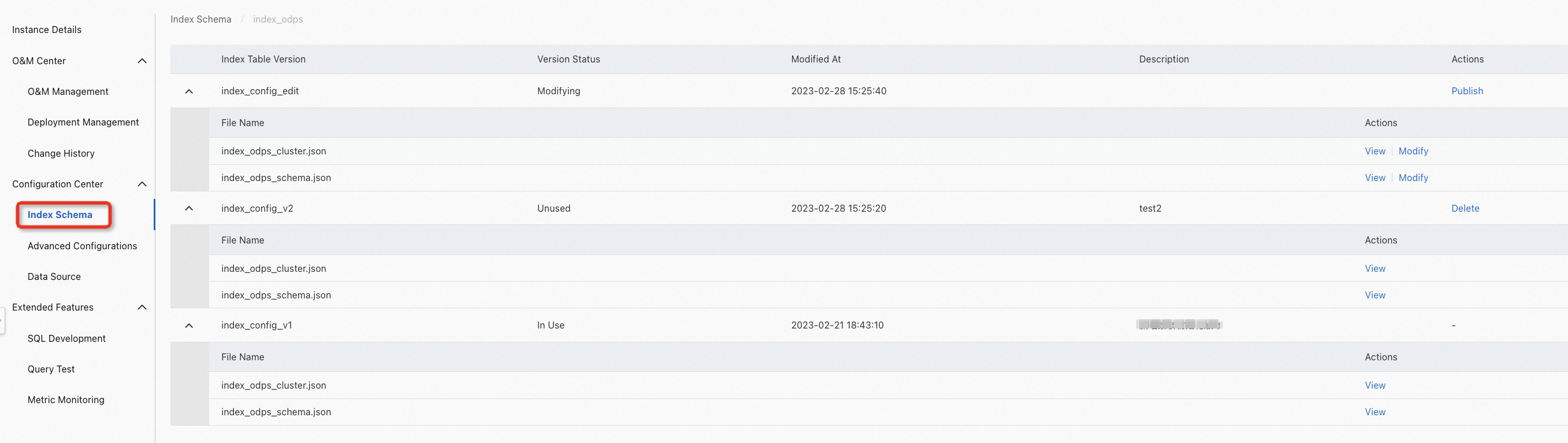
新しいインデックステーブルバージョンを変更して公開する:
「変更中」状態のバージョンを見つけて、「変更」をクリックします。

変更後、「バージョンを保存」をクリックします。
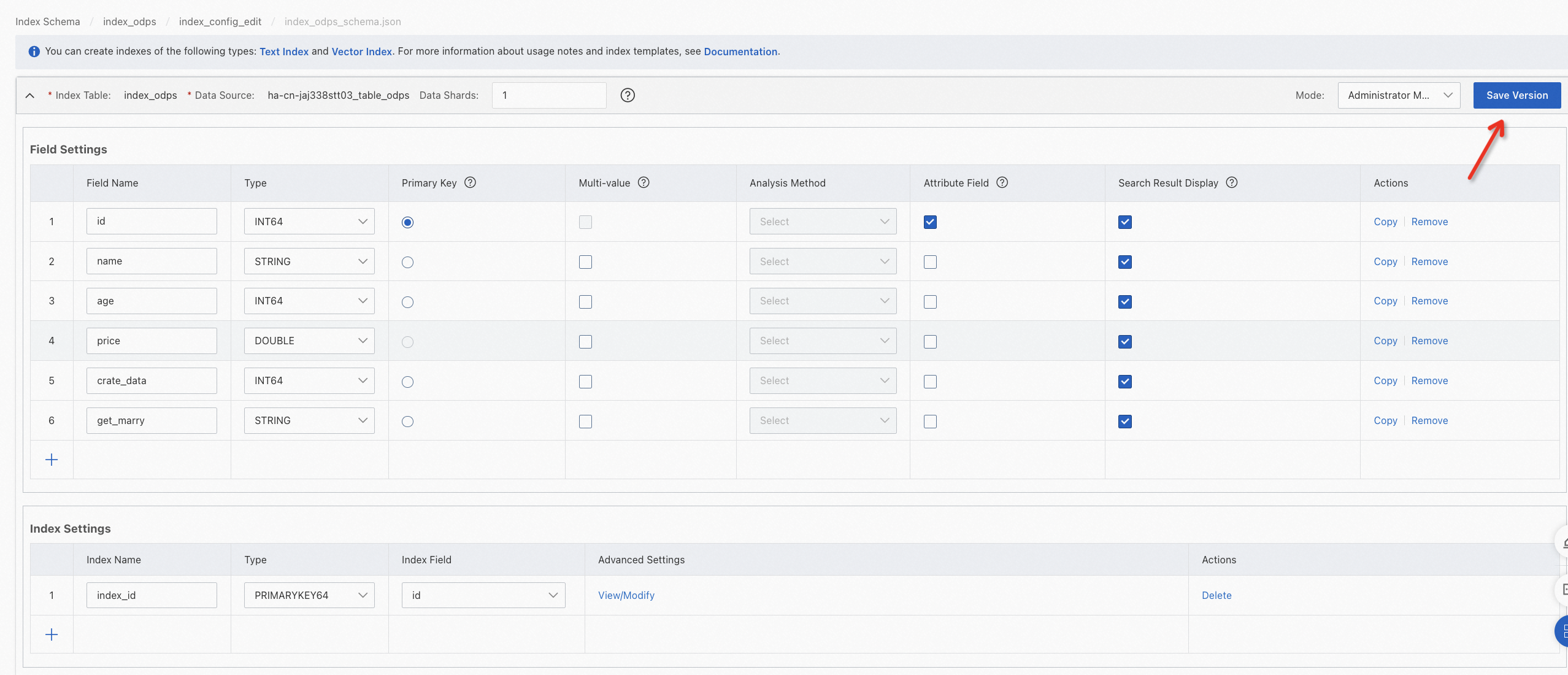
開発者モードに切り替えて、スキーマを手動で変更することもできます。
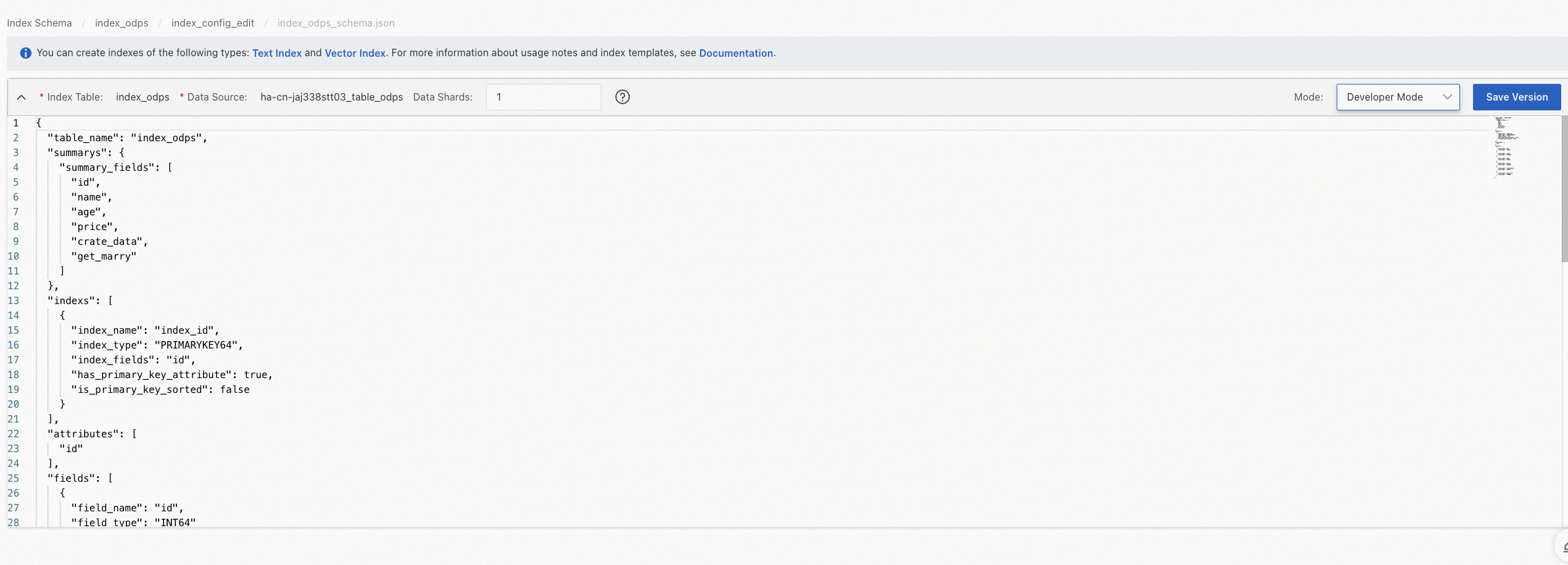
「変更中」状態のバージョンを見つけて、「公開」をクリックし、説明を入力します。次に、OKをクリックします。
この手順では、システムはインデックステーブルの新しいインデックステーブルバージョンを生成します。インデックステーブルバージョンは「未使用」状態です。
新しいインデックステーブルをクラスターで有効にする場合は、O&Mセンター > O&M管理を選択し、「構成の更新」をクリックして、表示されるパネルで構成のプッシュと再インデックス化のトリガーを選択します。
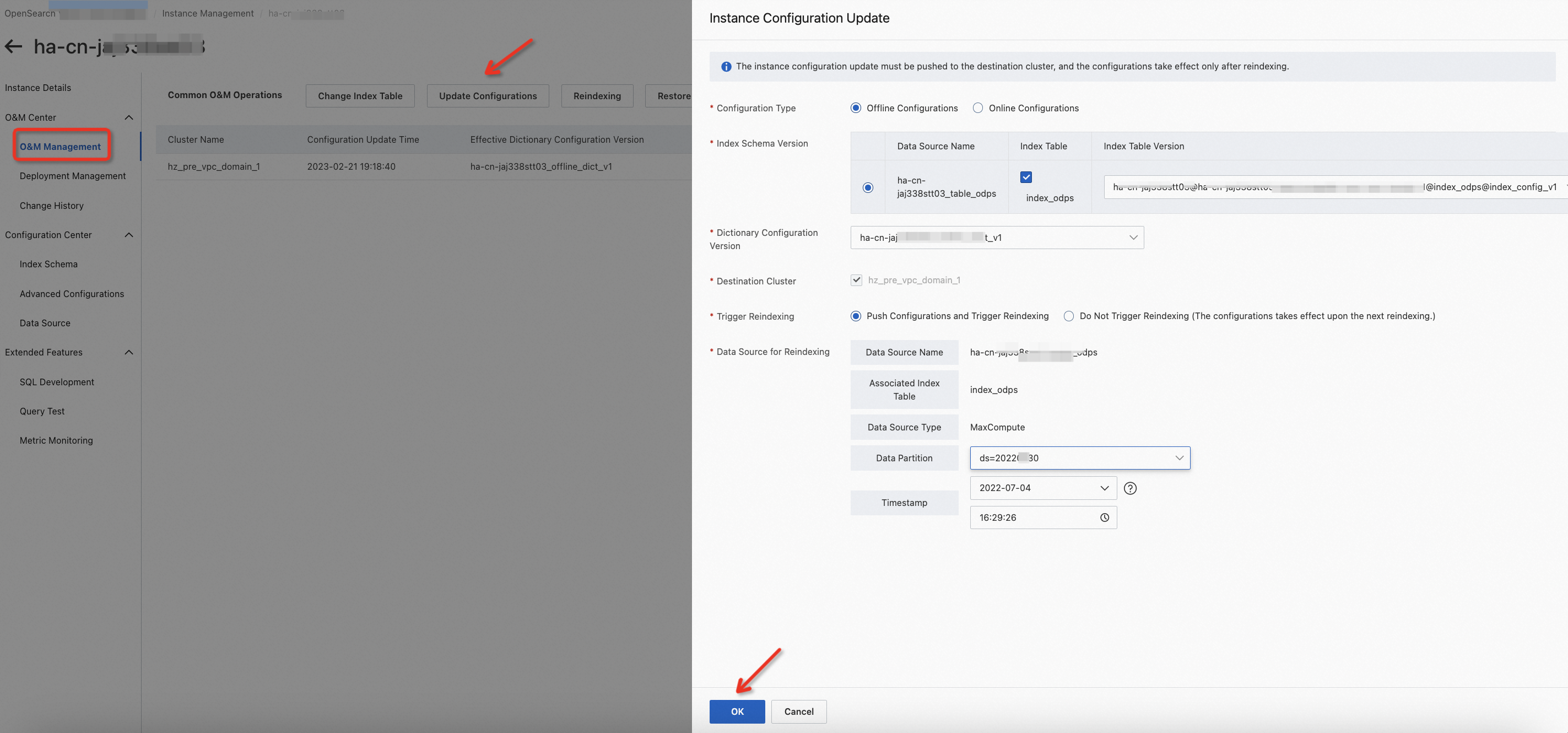
インデックステーブルバージョンを削除する:
「未使用」状態のインデックステーブルバージョンを削除できます。
インデックステーブルバージョンを表示する:
「表示」をクリックして、インデックステーブルバージョンの構成ページに移動します。ページには読み取り専用権限があります。
管理者モード:
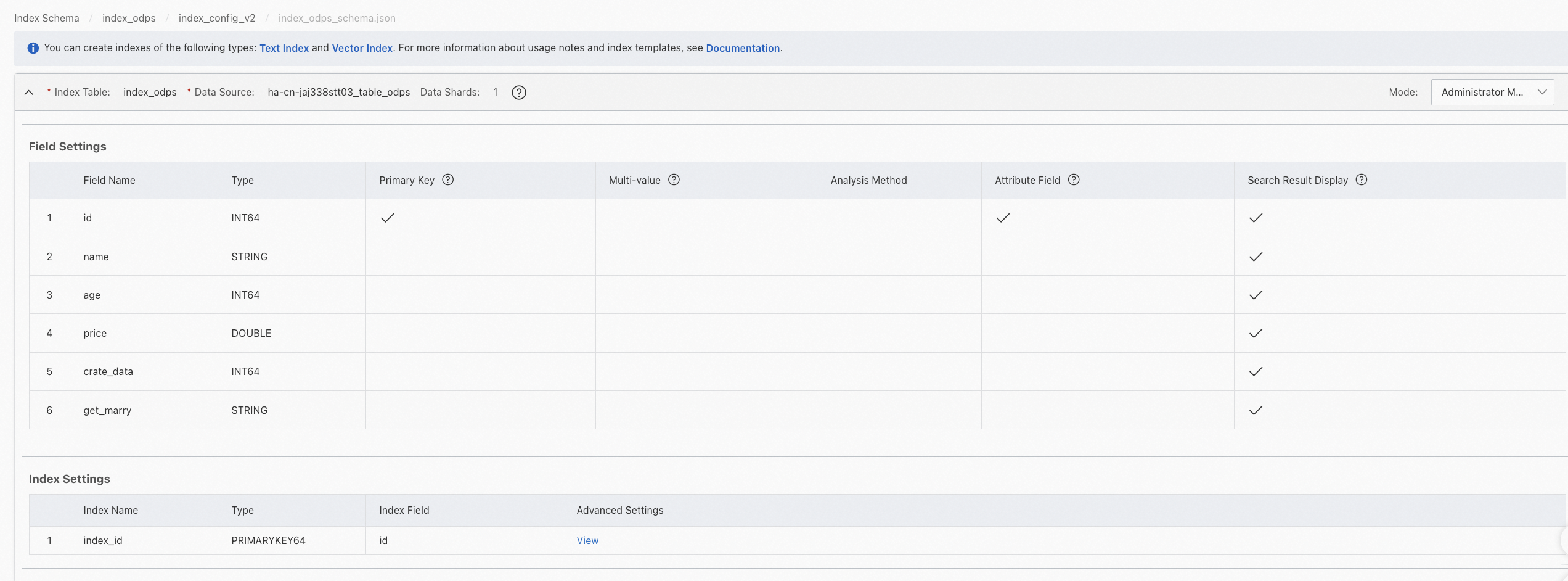
開発者モード:
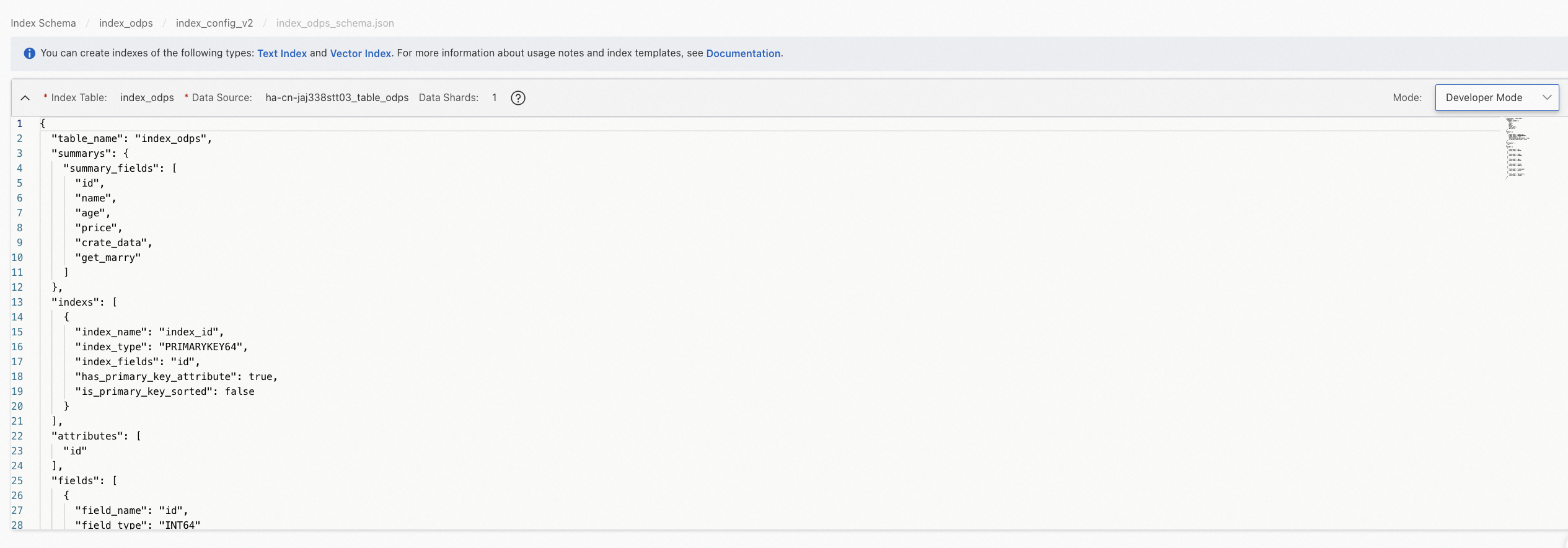
インデックステーブルを削除する
「使用中」状態のバージョンを含まないインデックステーブルを削除できます。

インデックステーブルに「使用中」状態のバージョンが含まれている場合、次の手順を実行することによってのみインデックステーブルを削除できます。

O&M管理 > デプロイメント管理を選択し、インデックステーブルを変更して、「オンラインで有効にする」をオフにします。
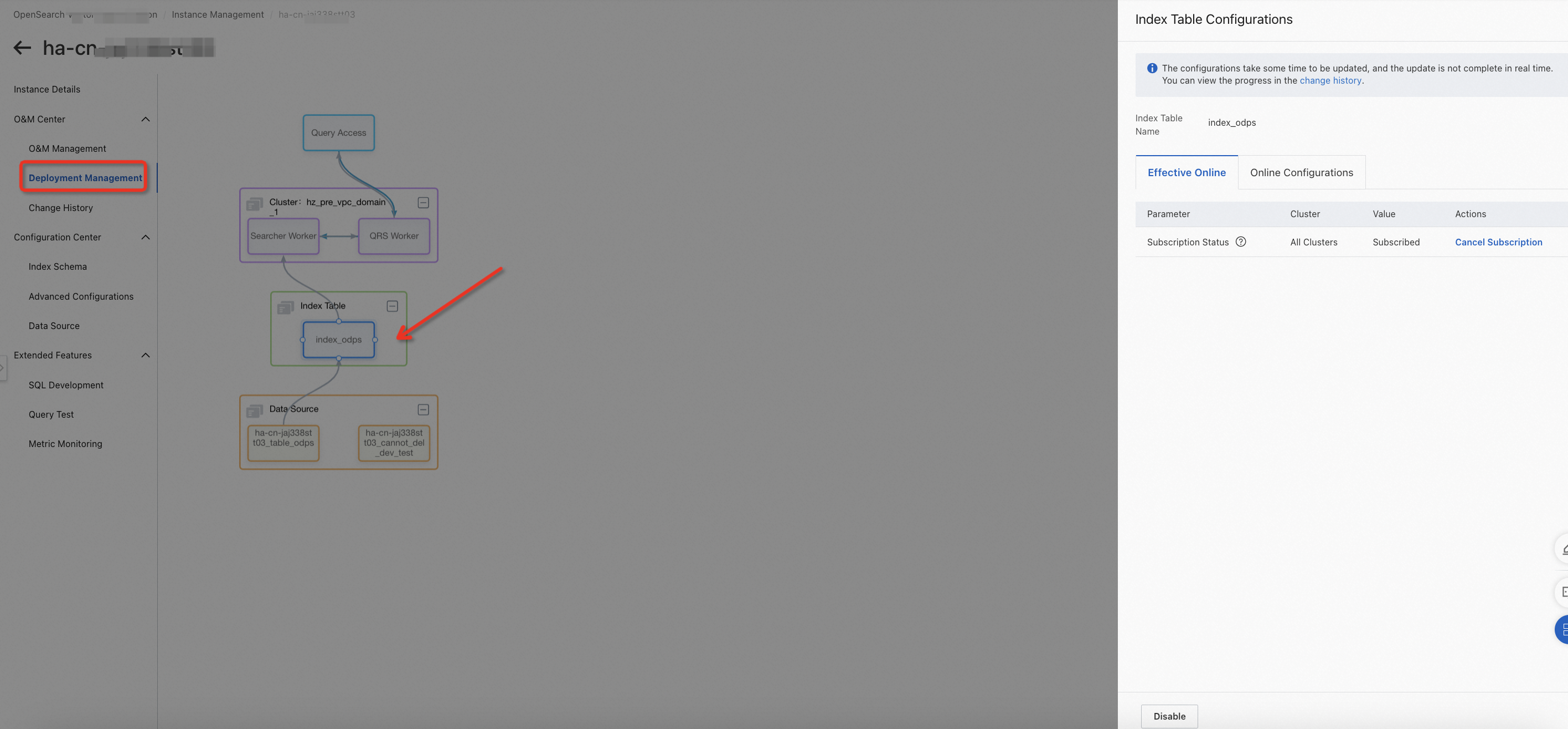
次に、構成センター > インデックススキーマを選択し、削除するインデックステーブルを見つけて、「削除」をクリックします。

注: デプロイメント管理ページで「オンラインで有効にする」がオフになっている場合は、インデックススキーマからインデックステーブルを削除する必要があります。そうでない場合、オンラインクラスターのクエリパフォーマンスに影響します。
使用上の注意:
インデックステーブルを追加する際は、データソースを指定する必要があります。データソースが存在しない場合は、インデックステーブルを追加する前にデータソースを追加する必要があります。
インデックステーブルを作成した後、インデックステーブル名を変更することはできません。
インデックステーブルに「使用中」状態のバージョンが含まれている場合、インデックステーブルを直接削除することはできません。
各インデックステーブルには、「変更中」状態のバージョンを1つだけ含めることができます。