転置インデックスとは
転置インデックスは、転置ファイルとも呼ばれます。転置インデックスは、用語からドキュメントまたはドキュメントセット内の位置へのマッピングを格納するために使用されるインデックス作成方法です。転置インデックスを使用すると、高速な全文検索を実行できます。転置インデックスは、ドキュメント検索システムで最も一般的に使用されるデータ構造です。転置インデックスを使用すると、用語を含むドキュメントのリストとドキュメント内の用語の位置をすばやく見つけ、分析のために用語頻度などの他の情報を取得できます。
転置インデックスに格納されている項目
項目 | 説明 |
ttf | 総用語頻度の略です。総用語頻度は、用語がすべてのドキュメントに出現する合計回数を示します。 |
df | ドキュメント頻度の略です。ドキュメント頻度は、特定の用語を含むドキュメントの総数を示します。 |
tf | 用語頻度の略です。用語頻度は、用語がドキュメントに出現する回数を示します。 |
docid | ドキュメントIDの略です。ドキュメントIDは、エンジン内のドキュメントの一意の識別子です。ドキュメントIDを使用して、クエリ対象のドキュメントに関する他の情報を取得できます。 |
fieldmap | フィールドマップは、用語のフィールド情報を記録するために使用されます。 |
セクション情報 | 一部のドキュメントをセクションに分割し、各セクションに追加情報を指定できます。情報は、後続の処理のために取得できます。 |
position | 位置は、ドキュメント内の用語の位置を記録するために使用されます。 |
positionpayload | ドキュメント内のさまざまな位置にペイロード情報を指定できます。ペイロード情報は、後続の処理のために取得できます。 |
docpayload | ドキュメントペイロードの略です。一部のドキュメントに追加情報を指定できます。情報は、後続の処理のために取得できます。 |
termpayload | 一部の用語に追加情報を指定できます。情報は、後続の処理のために取得できます。 |
転置インデックスの基本構造
構造名 | 説明 |
dictionary | 用語と転置リスト間のマッピングを格納する辞書。エンジンはこの辞書を使用して、ドキュメント内の用語の位置を見つけることができます。 |
doclist | ドキュメントリストは、特定の用語を含むドキュメントに関する情報を格納します。 |
positionlist | 位置リストは、各ドキュメント内の用語の位置情報を格納します。 |
truncatelist | トランケートリストは、エンジンのパフォーマンスを向上させるために使用されます。指定した構成に基づいて、検索パフォーマンスを向上させるために、高品質のドキュメント用に個別に転置インデックスを作成できます。 |
bitmap | ビットマップは、エンジンのパフォーマンスを向上させるために使用されます。指定した構成に基づいて、一部の転置構造をビットマップに格納できます。これにより、転置インデックスによって占有される記憶領域を削減し、検索パフォーマンスを向上させることができます。 |
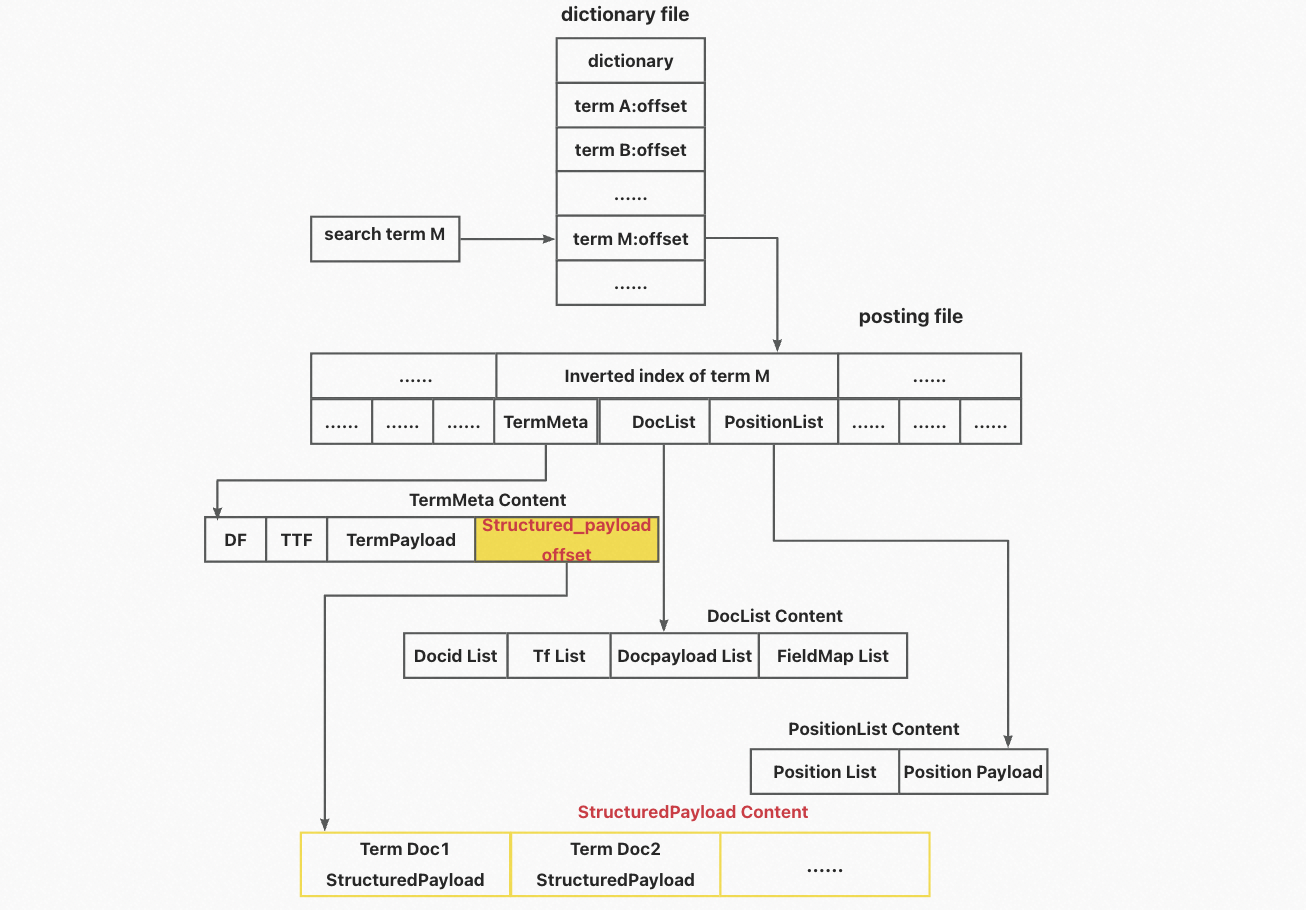
転置インデックスを使用した検索の基本手順
転置インデックスを使用して用語Mをクエリすると、エンジンは辞書ファイルをクエリして、転置ファイル内の用語Mの開始位置を見つけます。次に、エンジンは転置リストを解析して、用語M情報の次の部分を取得します:TermMeta、DocList、およびPositionList。TermMetaは、用語のdf、ttf、およびtermpayloadを含む、用語の基本的な説明を格納します。DocListには、用語を含むドキュメントに関する情報が含まれています。各ドキュメントに関する情報には、ドキュメントID、ドキュメント内の用語頻度、ドキュメントペイロード、および用語を含むフィールドが含まれます。PositionListには、各ドキュメント内の用語の位置情報が含まれています。位置情報には、ドキュメント内の用語の具体的な位置とpositionpayload情報が含まれます。