前提条件
以前 ODPS として知られていた MaxCompute について理解していること。MaxCompute の詳細については、「OpenSearch とは」をご参照ください。
OpenSearch コンソールへのログインに使用するアカウントには、構成する MaxCompute テーブルに対する次の権限が付与されていること。テーブルに対する DESCRIBE、SELECT、および DOWNLOAD 権限、テーブルのフィールドに対する LABEL 権限。
次のステートメントを実行して、必要な権限をアカウントに付与できます。
-- アカウントを追加します。
add user ****@aliyun.com;
-- 必要な権限をアカウントに付与します。
GRANT describe,select,download ON TABLE table_xxx TO USER ****@aliyun.com
GRANT describe,select,download ON TABLE table_xxx_done TO USER ****@aliyun.com
-- MaxCompute テーブルに対してフィールド権限検証を有効にしている場合、データのプル時に権限の高いフィールドへのアクセスがシステムによって禁止され、テーブルのインデックスを作成できません。この場合、フィールドにアクセスするための権限をアカウントに付与する必要があります。
-- プロジェクト全体に対する権限を付与します。
SET LABEL 3 to USER ****@aliyun.com
-- 単一のテーブルに対する権限を付与します。
GRANT LABEL 3 ON TABLE table_xxx(col1, col2) TO ****@aliyun.comMaxCompute テーブルに含まれるフィールドは、STRING、BOOLEAN、DOUBLE、BIGINT、DATETIME のいずれかのデータ型であること。
テーブル作成ステートメントと MaxCompute データソースを追加するためのパラメーターの詳細については、「MaxCompute データソースにテーブルを作成するための CREATE TABLE ステートメント」をご参照ください。
MaxCompute データソースを構成する
1. OpenSearch コンソールにログインします。左上隅で、OpenSearch Vector Search Edition を選択します。 [インスタンス管理] ページで、管理するインスタンスを見つけ、[操作] 列の [管理] をクリックします。
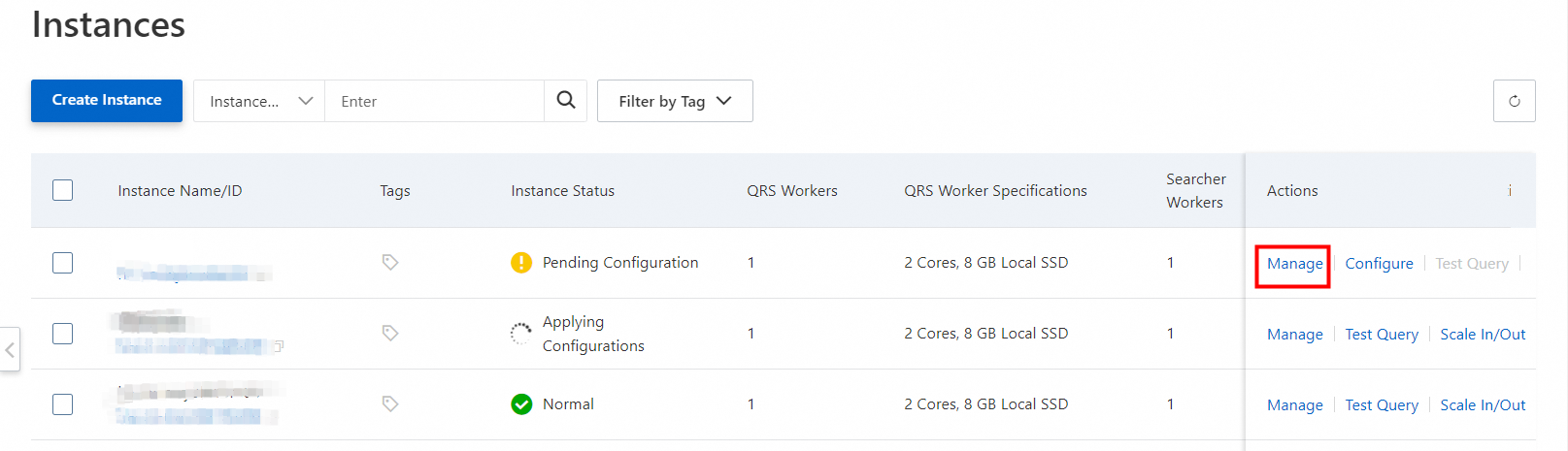
左側のナビゲーションウィンドウで、[構成センター] > [データソース] を選択します。 [データソースの追加] をクリックします。表示されるパネルで、データソースの種類として MaxCompute を選択し、[データソース名]、[プロジェクト]、[AccessKey ID]、[AccessKey Secret]、[テーブル]、[パーティションキー]、データ ソースを追加 などのパラメーターを構成します。
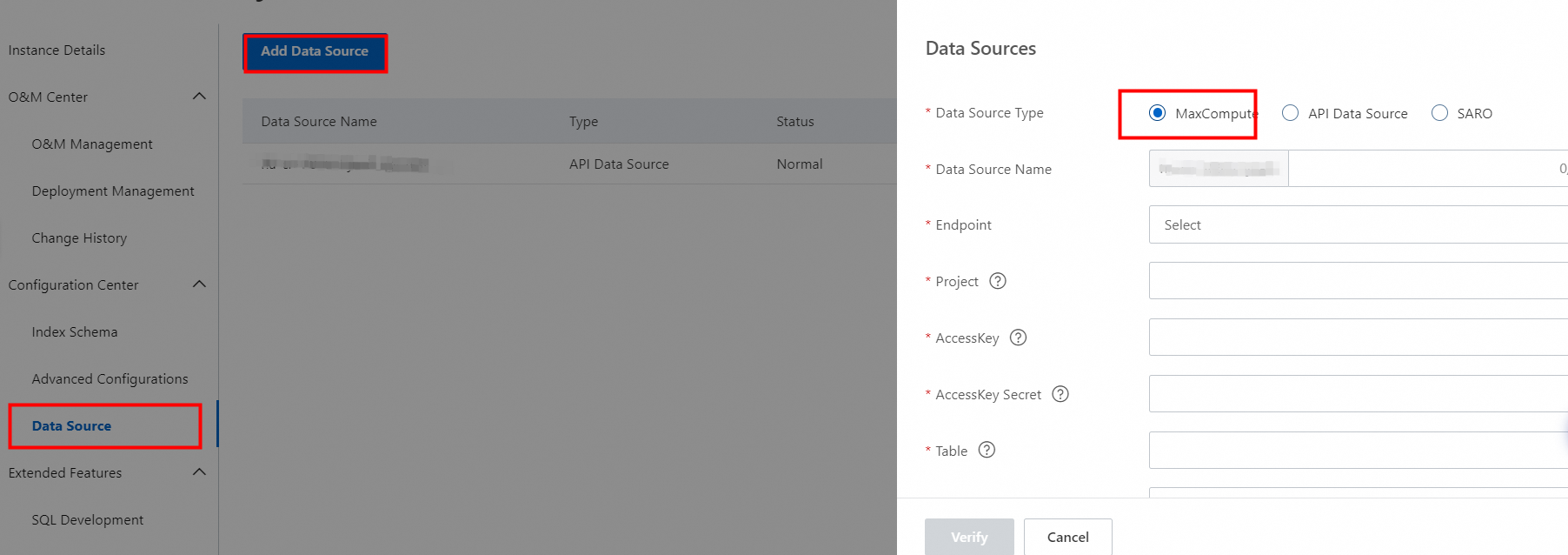
3. パラメーターを構成した後、[チェック] をクリックします。構成がチェックに合格したら、[OK] をクリックします。
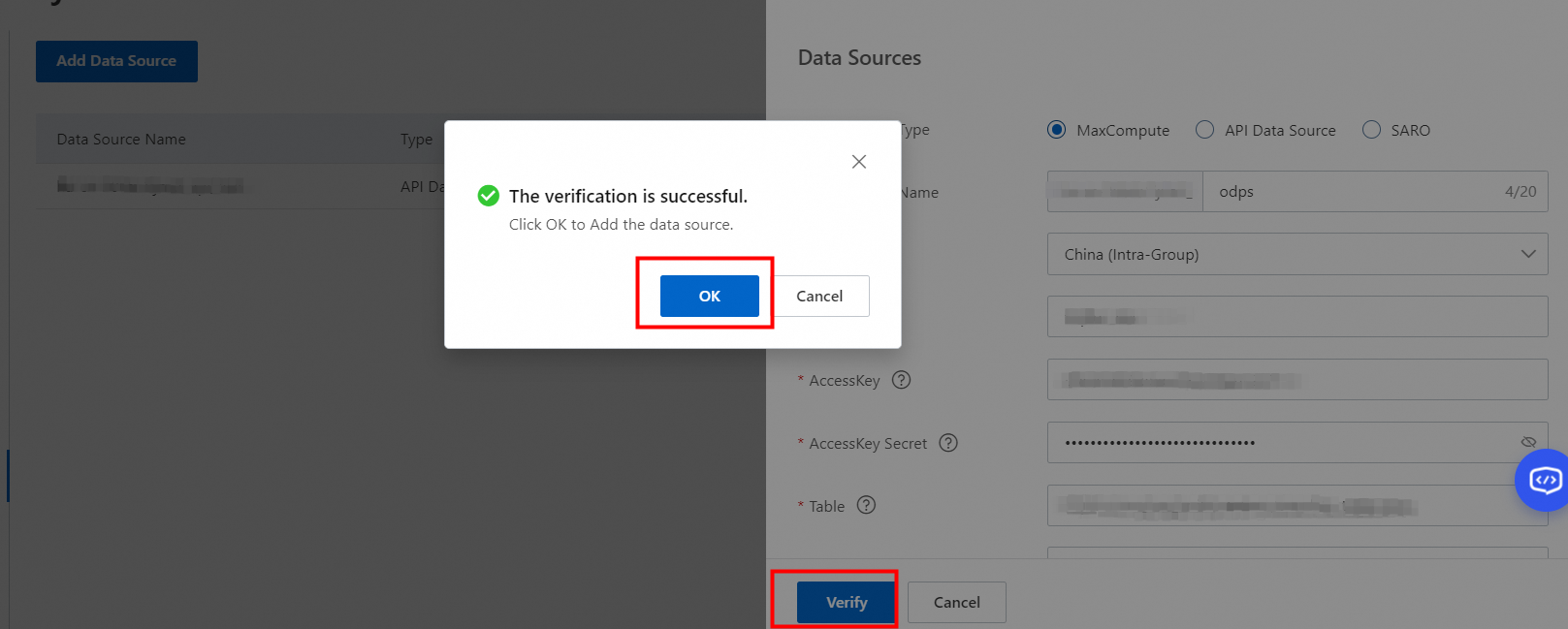
4. データソースを作成した後、インデックススキーマを構成して、データソースのインデックステーブルを作成します。詳細については、「インデックススキーマ」の「インデックステーブルを追加する」セクションをご参照ください。
5. インデックステーブルを構成した後、データソースの構成を更新し、再インデックスをトリガーして、データソースをオンラインクラスターで使用できるようにします。詳細については、「構成を更新する」をご参照ください。
パラメーターの説明
[データソース名]: データソースの名前。InstanceName_CustomName 形式で名前を指定します。
[プロジェクト]、[AccessKey ID]、[AccessKey Secret]、[テーブル]、[パーティションキー]: MaxCompute データソースに接続するために必要なパラメーター。
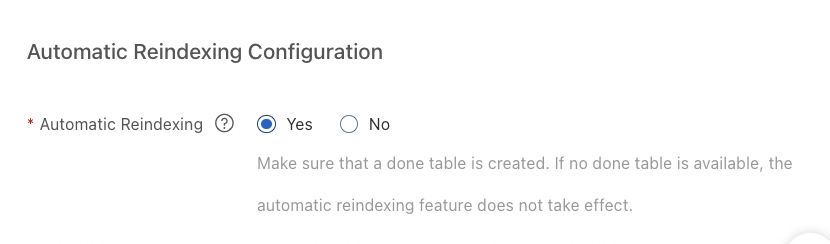
[自動再インデックス]: 自動再インデックス機能を有効にするかどうかを指定します。自動再インデックス機能が有効になっている場合、システムはデータソースのデータ変更を検出するたびに、データソースを参照するインデックステーブルのインデックスを自動的に再構築します。
自動再インデックスを有効にする場合は、完了テーブルを作成する必要があります。詳細については、「自動再インデックスを構成する」セクションをご参照ください。
自動再インデックスを構成する
完了テーブルの説明: データソースを構成するときに自動再インデックスを有効にすると、OpenSearch Vector Search Edition は完了テーブルの変更に基づいてインデックスを自動的に再構築します。
例: MaxCompute データソースを構成するときに、MaxCompute テーブルとして mytable を指定し、パーティションとして ds=20220113 を指定します。データソースの再インデックスを初めて構成した後、システムは毎日新しいパーティションを生成します。新しいパーティションにはそれぞれ、テーブルの完全データが含まれています。新しいパーティションが生成されるたびに、OpenSearch Vector Search Edition は新しいパーティションをスキャンし、新しいパーティションのデータに基づいてインデックスを自動的に再構築する必要があります。この要件を満たすために、自動再インデックス機能と完了テーブルを使用できます。
手順
1. データソースを作成するときに自動再インデックスを有効にします。
2. MaxCompute で対応する完了テーブルを構成します。データテーブルの名前が mytable で、データテーブルのパーティションキーの名前が ds の場合、完了テーブルの名前は mytable_done で、完了テーブルのパーティションキーの名前は ds です。次のコードブロックは、2 つのテーブルが MaxCompute にどのように表示されるかを示しています。
odps:sql:xxx> show tables;
InstanceId: xxx
SQL: .
ALIYUN$****@aliyun.com:mytable # データソースの完全データを格納するテーブル。
ALIYUN$****@aliyun.com:mytable_done # ソーステーブルの完全データが自動的に同期される完了テーブル。次の図は、完了テーブルを示しています。
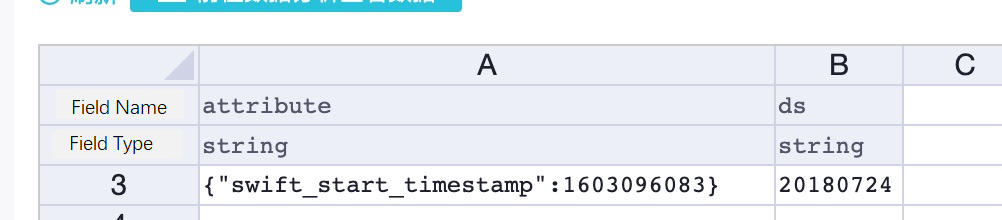
次のステートメントを実行して、完了テーブルを作成できます。
create table mytable_done (attribute string) partitioned by (ds string);3. mytable テーブルの ds=20220114 パーティションが生成されたら、完了テーブルを構成して、OpenSearch Vector Search Edition がインデックスを再構築するようにトリガーします。
-- パーティションを追加します。
alter table mytable_done add if not exists partition (ds="20220114");
-- セマフォを挿入して、自動完全データ同期を有効にします。
insert into table mytable_done partition (ds="20220114") select '{"swift_start_timestamp":1642003200}';完了テーブルには次の内容が含まれています。
odps:sql:xxx> select * from mytable_done where ds=20220114 limit 1;
InstanceId: xxx
SQL: .
+-----------+----+
| attribute | ds |
+-----------+----+
| {"swift_start_timestamp":1642003200} | 20220114 |
+-----------+----+自動完全データ同期のセマフォが完了テーブルに挿入されると、OpenSearch Vector Search Edition は完了テーブルのセマフォをスキャンし、再インデックス タスクを自動的にトリガーします。
完了テーブルには少なくとも 1 つのパーティションキーを指定してください。完了テーブルのパーティションキーの名前は、データテーブルのパーティションキーの名前と同じである必要があります。データテーブルのパーティションキーが ds の場合、完了テーブルのパーティションキーは ds に設定する必要があります。
完了テーブルには、STRING データ型のフィールドが 1 つだけ含まれています。フィールド名は attribute である必要があります。
完了テーブルに追加するパーティションは、データテーブルに存在する必要があります。たとえば、データテーブルに ds=20220114、ds=20220115、ds=20220116 パーティションが含まれている場合、完了テーブルに追加するパーティションを 3 つのパーティションから選択する必要があります。
完了テーブルにデータを挿入する場合、attribute フィールドの値は
{"swift_start_timestamp":1642003200}などの JSON 文字列である必要があります。タイムスタンプは、リアルタイム増分同期の開始オフセットを指定します。
MaxCompute データソースを変更する
[データソース] ページで、変更するデータソースを見つけ、[操作] 列の [変更] をクリックします。
[データソースの変更] パネルで、[プロジェクト]、[AccessKey ID]、[AccessKey Secret]、[テーブル]、データ ソースの変更 などのパラメーターを変更します。
[チェック] をクリックします。変更された構成がチェックに合格したら、[OK] をクリックして変更を保存します。
データソースを変更した後、データソースの構成を更新し、再インデックスをトリガーして、データソースをオンラインクラスターで使用できるようにします。詳細については、「構成を更新する」をご参照ください。
2022011314 などの yyyymmddhh 形式の時間別パーティションを指定することをお勧めします。こうすることで、データソースに対して毎日複数の完全インデックス作成タスクをトリガーできます。
MaxCompute データソースを削除する
[データソース] ページで、削除するデータソースを見つけ、データ ソース削除 列の をクリックします。
[削除] をクリックすると、システムはデータソースがインデックステーブルによって参照されているかどうかを確認します。
データソースがインデックステーブルによって参照されていない場合は、[OK] をクリックしてデータソースを削除します。次に、データソースの構成を更新し、インデックスを再構築して、データソースが削除されていることを確認します。
データソースがインデックステーブルによって参照されている場合、[削除] をクリックすると、システムは次のエラーを返します。
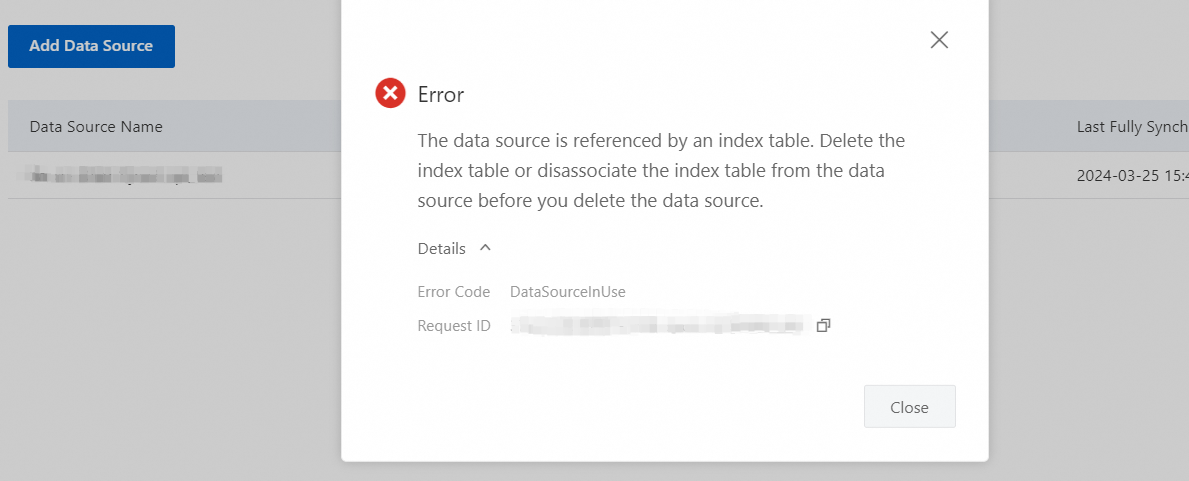
データソースを削除する前に、データソースを参照するインデックステーブルを削除する必要があります。詳細については、「インデックススキーマ」の「インデックステーブルを削除する」セクションをご参照ください。
使用上の注意
データソースを変更する場合、データソースの名前を変更することはできません。
MaxCompute データソースは外部テーブルをサポートしていません。内部テーブルを作成する必要があります。
MaxCompute データソースを作成するときに指定するテーブルは、パーティションテーブルである必要があります。
MaxCompute テーブルの完全データをデータソースとして使用して、OpenSearch Vector Search Edition にインデックスを作成し、API データソースを使用して増分データをリアルタイムで同期できます。