体験センターでは、コードを記述することなく、ビジュアルインターフェイスを通じて、ドキュメント解析、テキスト埋め込み、再ランキングなどの AI 検索サービスをテストできます。サービスが要件を満たしていることを確認した後、サンプルコードをダウンロードしてビルドを開始できます。
利用可能なサービス
| サービスカテゴリ | 説明 |
|---|---|
| ドキュメント/画像解析 | 非構造化ドキュメントから論理構造 (タイトル、段落、テーブル、画像) を抽出し、構造化フォーマットでコンテンツを出力します。また、マルチモーダル大規模言語モデル (LLM) を使用した画像内容認識や、画像内のテキストに対する光学文字認識 (OCR) も含まれます。 |
| ドキュメントスライス | HTML、Markdown、TXT 形式のコンテンツを、段落、セマンティクス、またはカスタムルールに基づいてチャンクに分割します。コード、画像、テーブルをリッチテキストとして抽出することをサポートします。 |
| テキスト埋め込み | セマンティック検索や検索拡張生成 (RAG) パイプラインのために、テキストを密ベクトルに変換します。6 つのモデルが利用可能です。詳細については、「テキスト埋め込みモデル」をご参照ください。 |
| マルチモーダルベクター | 画像とテキストをベクターに変換し、クロスモーダル検索を実現します。2 つのバイリンガル (中国語と英語) モデルが利用可能です。詳細については、「マルチモーダルベクターモデル」をご参照ください。 |
| 疎テキスト埋め込み | テキストを、キーワードと単語頻度を表す疎ベクトルに変換します。密ベクトルと組み合わせてハイブリッド検索を行うことで、検索精度を向上させます。OpenSearch 疎テキストベクトル化サービスは 100 以上の言語をサポートし、最大入力は 8,192 トークンです。 |
| 次元削減 | ベクターモデルをファインチューニングして埋め込み次元を削減し、検索品質を大幅に損なうことなく、ストレージとコンピューティングコストを削減します。 |
| クエリ分析 | LLM と自然言語処理 (NLP) を使用してユーザークエリを分析します。インテント認識、クエリ拡張、NL2SQL 変換をサポートし、RAG シナリオでの検索と Q&A パフォーマンスを向上させます。 |
| ソートサービス | クエリに対するセマンティック関連性に基づいてドキュメントをスコアリングし、再ランキングします。3 つの再ランキングモデルが利用可能です。詳細については、「再ランキングモデル」をご参照ください。 |
| 音声認識 | 音声および動画コンテンツを構造化テキストに変換します。複数の言語をサポートします。 |
| ビデオスナップショット | 動画ファイルからキーフレームを抽出します。マルチモーダル埋め込みや画像解析と組み合わせて、クロスモーダル検索を可能にします。 |
| 大規模モデル | LLM を使用して自然言語の質問に対する応答を生成します。Qwen3-235B-A22B、DeepSeek-R1、OpenSearch-Qwen-Turbo など、10 のモデルが利用可能です。詳細については、「大規模モデル」をご参照ください。 |
| インターネット検索 | プライベートナレッジベースをリアルタイムの Web 結果で補完し、LLM が正確な応答を生成するためのコンテキストを増やします。 |
テキスト埋め込みモデル
| モデル | 言語 | 最大入力 | 出力次元 |
|---|---|---|---|
| OpenSearch テキストベクトル化サービス-001 | 40+ | 300 トークン | 1,536 |
| OpenSearch ユニバーサルテキストベクトル化サービス-002 | 100+ | 8,192 トークン | 1,024 |
| OpenSearch テキストベクトル化サービス-Chinese-001 | 中国語 | 1,024 トークン | 768 |
| OpenSearch テキストベクトル化サービス-English-001 | 英語 | 512 トークン | 768 |
| GTE テキスト埋め込み-multilingual-Base | 70+ | 8,192 トークン | 768 |
| Qwen3 テキスト埋め込み-0.6B | 100+ | 32k トークン | 1,024 |
マルチモーダルベクターモデル
M2-Encoder-multimodal vector model:BM-6B に基づいて 60 億の画像とテキストのペア (中国語 30 億、英語 30 億) でトレーニングされたバイリンガル (中国語と英語) のマルチモーダルサービスです。このモデルは、Text-to-Image および Image-to-Text 検索を含む画像とテキストのクロスモーダル検索、および画像分類タスクをサポートします。
M2-Encoder-Large-multimodal vector model:バイリンガル (中国語と英語) のマルチモーダルサービスです。M2-Encoder モデルと比較して、モデルサイズが 10 億 (1B) パラメーターと大きく、より強力な表現能力とマルチモーダルタスクでの優れたパフォーマンスを提供します。
再ランキングモデル
| モデル | 言語 | 最大入力 |
|---|---|---|
| BGE 再構成モデル | 中国語、英語 | 512 トークン (クエリ + ドキュメント) |
| OpenSearch 自己開発再ソートモデル | 中国語、英語 | 512 トークン (クエリ + ドキュメント) |
| Qwen3 ソート-0.6B | 100+ | 32k トークン (クエリ + ドキュメント) |
大規模モデル
Qwen3-235B-A22B:Qwen シリーズの次世代大規模言語モデルです。広範なトレーニングに基づき、Qwen3 は推論、命令追従、エージェント機能、および多言語サポートにおいてブレークスルーを遂げました。100 以上の言語と方言をサポートし、強力な多言語理解、推論、および生成能力を備えています。
OpenSearch-Qwen-Turbo:Qwen-Turbo 大規模言語モデル上に構築され、このモデルは教師あり学習でファインチューニングされており、検索を強化し、有害なコンテンツを削減します。
Qwen-Turbo:Qwen シリーズの中で最も高速でコスト効率の高いモデルです。単純なジョブに適しています。詳細については、「モデルリスト」をご参照ください。
Qwen-Plus:能力の面でバランスの取れたモデルです。その推論性能、コスト、速度は Qwen-Max と Qwen-Turbo の中間に位置します。中程度に複雑なジョブに適しています。詳細については、「モデルリスト」をご参照ください。
Qwen-Max:Qwen シリーズで最も性能の高いモデルです。複雑でマルチステップのジョブに適しています。詳細については、「モデルリスト」をご参照ください。
QwQ 深層思考モデル:Qwen2.5-32B モデルでトレーニングされた QwQ 推論モデルです。その推論能力は強化学習によって大幅に向上しています。
DeepSeek-R1:複雑な推論タスクに特化した大規模言語モデルです。複雑な命令の理解と結果の精度の確保に優れています。
DeepSeek-V3:長文テキスト、コード、数学、百科事典的知識、および中国語能力に優れた Mixture of Experts (MoE) モデルです。
DeepSeek-R1-distill-qwen-7b:知識蒸留を使用して Qwen-7B でファインチューニングされたモデルです。トレーニングサンプルは DeepSeek-R1 によって生成されます。
DeepSeek-R1-distill-qwen-14b:知識蒸留を使用して Qwen-14B でファインチューニングされたモデルです。トレーニングサンプルは DeepSeek-R1 によって生成されます。
サービスのテスト
すべてのサービスは同じパターンに従います:サービスカテゴリを選択し、入力データを提供し、[結果を取得] をクリックします。結果が表示された後、生の API 応答については [結果のソースコード] を、すぐに使える統合コードについては [サンプルコード] を表示します。
ドキュメント解析のテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [ドキュメント/画像解析] (document-analyze) を選択し、[体験サービス] からサービスを選択します。
[サンプルデータ] または [データの管理] を使用してテストデータを提供します。2 つの入力メソッドがサポートされています:
ファイル:ローカルファイルをアップロードします。サポートされているフォーマット:Txt、PDF、HTML、Doc、Docx、PPT、および PPTX。最大ファイルサイズ:20 MB。ファイルは 7 日後に削除されます — プラットフォームはご利用のデータを保持しません。
URL:1 つ以上のファイル URL をそれぞれ別の行に入力し、ファイルタイプを指定します。
重要正しいファイルタイプを選択してください。フォーマットが一致しない場合、解析は失敗します。
重要URL インポート機能は、適用される法律を遵守して使用してください。ご利用の操作がターゲットプラットフォームの利用規約およびコンテンツ所有者の権利を遵守していることを確認する責任は、お客様にあります。

独自のデータをアップロードした場合は、ドロップダウンリストからファイルまたは URL を選択します。

[結果を取得] をクリックします。
結果:解析の進捗と出力を表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:ドキュメント解析サービスを呼び出すためのすぐに使えるコードを提供します。

ドキュメントチャンキングのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [ドキュメントスライス] (document-split) を選択し、[体験サービス] からサービスを選択します。
[サンプルデータ] または [マイデータ] を使用してテストデータを提供します。独自のコンテンツを入力する場合は、正しいフォーマット (TXT、HTML、または Markdown) を選択してください。
正しいデータ形式を選択してください。フォーマットが一致しない場合、チャンキングは失敗します。
[最大スライス長] を設定します (デフォルト:300 トークン、最大:1,024 トークン)。これは、チャンクあたりの最大トークン数を制御します。チャンクが小さいほど、特定のクエリに対する検索精度が向上します。チャンクが大きいほど、結果ごとにより多くのコンテキストが保持されます。ご利用のユースケースと埋め込みモデルのトークン制限に基づいて調整してください。
必要に応じて [文レベルのスライスに戻す] を切り替えてから、[結果を取得] をクリックします。
結果:チャンキングの進捗と出力を表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:ドキュメントチャンキングサービスを呼び出すためのすぐに使えるコードを提供します。
テキスト埋め込みと疎埋め込みのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] には、[テキスト埋め込み] (text-embedding) を選択し、次に [体験サービス] からモデルを選択します。
[コンテンツタイプ] を、インデックスされたコンテンツを埋め込む場合は [ドキュメント] に、検索クエリの場合は [クエリ] に設定します。
[テキストグループを追加] または [JSON コードを直接入力] を使用して入力テキストを追加します。

[結果を取得] をクリックします。
結果:埋め込みベクターを表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:テキスト埋め込みサービスを呼び出すためのすぐに使えるコードを提供します。

マルチモーダル埋め込みのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリー] で [マルチモーダルベクトル] (multi-modal-embedding) を選択し、次に [エクスペリエンスサービス] からモデルを選択して、入力タイプとして [テキスト]、[画像]、または [テキスト + 画像] を選択します。
アップロードされた画像は 7 日後に削除されます。プラットフォームはご利用のデータを保持しません。

[結果を取得] をクリックします。
結果:マルチモーダル埋め込みベクターを表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:マルチモーダル埋め込みサービスを呼び出すためのすぐに使えるコードを提供します。

再ランキングのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
「サービスカテゴリ」で、[並べ替えサービス](ランカー)を選択し、次に[体験サービス]からモデルを選択します。
[サンプルデータ] を使用してテストデータを提供するか、独自のドキュメントを入力します。
[検索クエリ] にクエリを入力します。

[結果を取得] をクリックします。サービスは、クエリに対する関連性に基づいて各ドキュメントをスコアリングし、結果を降順で返します。
結果:関連性スコアとランク付けされたドキュメントの順序を表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:再ランキングサービスを呼び出すためのすぐに使えるコードを提供します。

ビデオスナップショットのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [ビデオスナップショット] (video-snapshot) を選択します。
[サンプルデータ] を使用して動画を提供するか、独自の動画をアップロードします。
[結果を取得] をクリックします。サービスは動画からキーフレームを抽出します。
音声認識のテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [音声認識] (audio-asr) を選択します。
[サンプルデータ] を使用して音声データを提供するか、独自のファイルをアップロードします。
[結果を取得] をクリックします。サービスは音声コンテンツを構造化テキストに変換します。
LLM サービスのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
サービスカテゴリでは、[大規模モデル] (テキスト生成) を選択し、[エクスペリエンスサービス] からモデルを選択します。[インターネット検索] サービスを有効にするには、
 をクリックします。サービスは、クエリに基づいてインターネット検索を実行するかどうかを決定します。
をクリックします。サービスは、クエリに基づいてインターネット検索を実行するかどうかを決定します。質問を入力して送信します。モデルが応答を生成します。応答ページには、セッションの入力および出力トークンの数が表示されます。必要に応じて、会話を削除したり、全文をコピーしたりできます。
重要すべてのコンテンツは AI モデルによって生成されます。正確性や完全性は保証されません。生成されたコンテンツは、当社の見解や意見を表すものではありません。
画像内容解析のテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
サービスカテゴリ では、[画像内容解析] (image-analyze) を選択します。体験サービス では、[画像内容理解サービス 001] または [画像文字認識サービス 001] を選択します。
サンプル画像を使用するか、独自の画像をアップロードして画像を提供します。

[結果を取得] をクリックします。サービスは画像を分析し、認識されたコンテンツを出力します。
結果:検出出力を表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:画像内容解析サービスを呼び出すためのすぐに使えるコードを提供します。

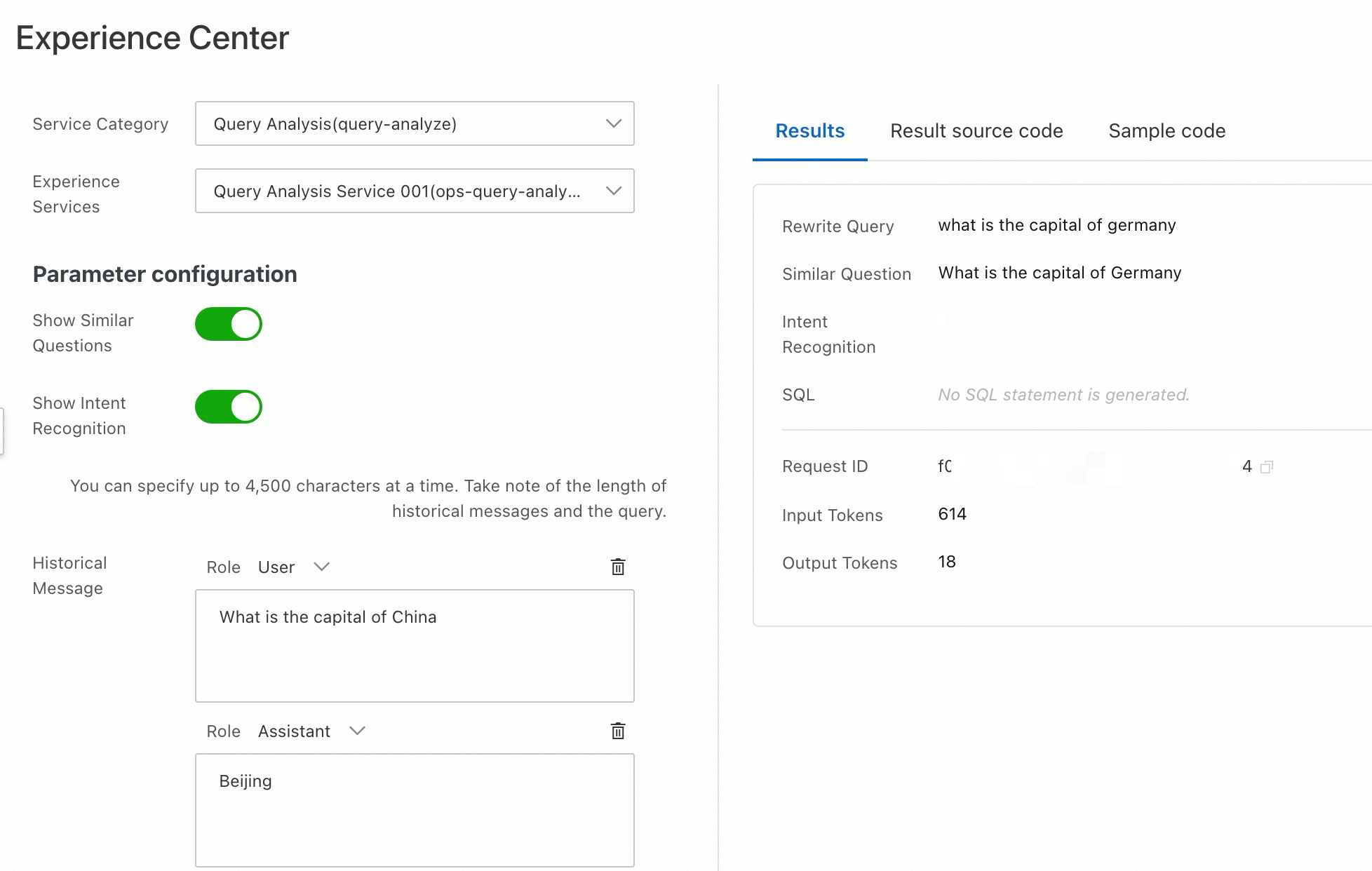
クエリ分析のテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [クエリ分析] (query-analyze) を選択します。
インテント認識のために、[検索クエリ] にクエリを入力します。マルチターン動作のテストを行うには、履歴メッセージ に会話履歴を追加します。モデルは分析時に、この履歴とクエリの両方を組み合わせます。NL2SQL のテストを行うには、[NL2SQL の表示] を有効化し、サービス構成 を選択して、自然言語クエリを SQL ステートメントに変換します。
[結果を取得] をクリックします。
結果:分析出力を表示します。
結果のソースコード:生の API 応答を表示します。[コードをコピー] または [ファイルをダウンロード] をクリックしてローカルに保存します。
サンプルコード:クエリ分析サービスを呼び出すためのすぐに使えるコードを提供します。
ベクターファインチューニングのテスト
AI 検索オープンプラットフォームコンソールにログインします。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [次元削減] (embedding-dim-reduction) を選択します。
ファインチューニングされたモデルを選択し、[生成されるベクター次元] をトレーニング中に使用された次元以下の値に設定し、元のベクターを入力します。
[結果を取得] をクリックして、次元削減された出力を表示します。
カスタム次元削減モデルのトレーニングに関する情報については、「サービスカスタマイズ」をご参照ください。
インターネット検索のテスト
インターネット検索は、スタンドアロンサービスとして、または LLM サービス内で有効にして、2 つの方法で利用できます。
AI 検索オープンプラットフォームコンソールにログインします。
ターゲットリージョンを選択し、[AI 検索オープンプラットフォーム] に切り替えます。
左側のナビゲーションウィンドウで、[体験センター] をクリックします。
[サービスカテゴリ] で [インターネット検索] (web-search) を選択します。
[検索クエリ] にクエリを入力し、結果を確認します。