OpenSearch Retrieval Engine Edition は、Alibaba が開発した大規模な分散検索エンジンです。Taobao、Tmall、Cainiao、Youku、および中国以外のEコマースビジネスを含む Alibaba Group 全体の検索サービスを支えています。また、Alibaba Cloud の OpenSearch サービスもサポートしています。長年の開発を経て、OpenSearch Retrieval Engine Edition は、高可用性 (HA)、リアルタイム性能、低コストといったビジネスニーズを満たすように進化しました。また、成熟した自動化された運用保守 (O&M) システムも含まれています。このシステムにより、ビジネスニーズに合わせて検索サービスを簡単に構築できます。
サービスアーキテクチャ
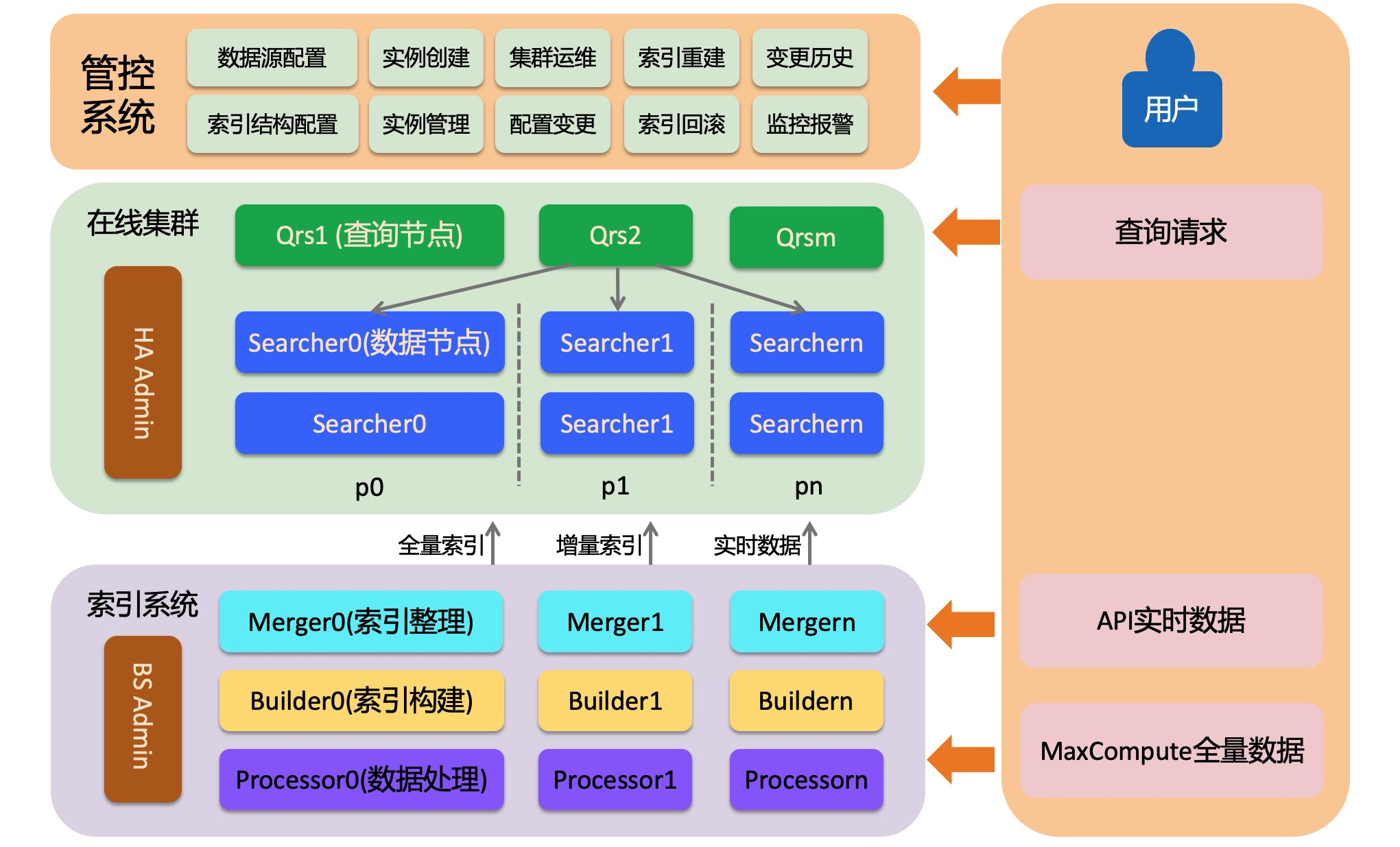
OpenSearch Retrieval Engine Edition は、オンラインシステム、オフラインインデックス構築システム、コントロールシステムの3つの主要部分で構成されています。オンラインシステムはインデックスをロードし、検索サービスを提供します。オフラインインデックス構築システムは、ユーザーデータからインデックスを構築します。これには、フルインデックス、バッチ増分インデックス、およびリアルタイムインデックスが含まれます。コントロールシステムは、自動化された運用保守サービスを提供し、クラスターの作成と管理を支援します。
オンラインシステム
オンラインシステムは、分散情報検索システムです。admin、Qrs、Searcher の3つのロールで構成されています。以下のセクションでは、各ロールについて説明します。
HA Admin
HA Admin は、オンラインシステムの頭脳です。各物理クラスターには少なくとも1つの admin があります。HA Admin は、コントロールシステムからコマンドを受信し、Qrs および Searcher ノードに運用保守指示を送信します。admin は、Qrs および Searcher ノードのリアルタイムモニタリングも実行します。ノードのハートビートが異常な場合、admin は自動的にノードを置き換えます。
Qrs (QRS ワーカー)
Qrs は、QRS ワーカーまたはクエリおよび結果処理ノードとも呼ばれます。受信したクエリリクエストを解析、検証、または書き換えます。その後、解析されたリクエストを Searcher に転送して実行します。Searcher からの結果を収集およびマージし、結果を処理してユーザーに返します。QRS ワーカーは、コンピューティング最適化ノードです。ユーザーデータをロードせず、通常は多くのメモリを必要としません。ただし、多くのドキュメントが返される場合や、多くの統計エントリが生成される場合は、大量のメモリを消費する可能性があります。QRS ワーカーの処理能力がボトルネックになった場合は、バックアップノードの数を増やすか、ノードスペックをアップグレードできます。
Searcher (データノード)
Searcher は、ユーザーインデックスデータをロードします。クエリに基づいてドキュメントを取得し、フィルタリング、統計、ソートなどの操作を実行します。Searcher 上のインデックスはシャーディングできます。シャーディングでは、シャーディングフィールドを 0 から 65,535 の間の値にハッシュ化します。この範囲は、指定されたシャード数に分割されます。シャード数はインデックス構築時に指定されます。大量のデータや高いクエリ性能要件を持つクラスターの場合、シャーディングはシングルリクエストの処理性能を向上させることができます。クラスター全体の処理能力を、例えば 1,000 QPS から 10,000 QPS に増やすには、バックアップを追加することでスケールアウトできます。バックアップのスケールアウトには、単一ノードだけでなく、すべてのデータをホストするために複数の Searcher ノードを追加することが含まれます。複数のシャードは、完全な [0, 65,535] 範囲をカバーする必要があります。
オフラインインデックス構築システム
OpenSearch Retrieval Engine Edition は、読み書き分離を使用する検索エンジンです。データ書き込みはオンライン検索サービスに影響を与えません。これにより、大規模なリアルタイムデータ書き込みをサポートしながら、安定したクエリサービスを保証します。インデックス構築システムには、フルと増分の2つの主要なフローが含まれています。各フローでは、3つのロールがデータ処理とインデックス構築を担当します。
フルフロー
OpenSearch Retrieval Engine Edition のインデックスは、複数バージョンをサポートしています。各インデックスバージョンは、生データ (API データソースはデフォルトで空) から構築されます。最初のビルドでフルデータ処理フローが開始されます。このフローは、データを処理してフルインデックスを生成するワンタイムジョブです。生成されたフルインデックスは、オンラインクラスターに切り替えられ、検索サービスを提供します。その後の増分データ更新は、新しいフルインデックスに適用されます。現在、フルジョブは MaxCompute または Hadoop 分散ファイルシステム (HDFS) データソースからのみフルデータを読み取ることができます。
複数のインデックスバージョンは、データ変更時の安定性を保証します。インデックススキーマまたはデータ構造が変更された場合、フルビルドによって新しいインデックスが生成され、古いバージョンから完全に分離されます。これにより、変更によって問題が発生した場合でも、迅速にロールバックできます。
フルインデックス生成には、データ処理、インデックス構築、インデックスマージなどの複数のステージが含まれます。生成速度を向上させるには、各ステージのインデックス処理の同時実行数を設定することができます。
増分フロー
フルインデックスが生成された後、その後のデータ更新は API を介してプッシュされます。API を介してプッシュされたデータは、2つの処理パイプラインによって処理されます。データは、プロセッサによって処理され、リアルタイムインデックスをメモリ内に構築するためにデータノードに直接プッシュされるか、または Builder と Merger によって処理され、増分インデックスが作成されます。このインデックスは、増分スイッチを介してデータノードに適用されます。増分スイッチ中に、メモリ内のリアルタイムインデックスはクリアされ、増分インデックスに既に含まれているデータはリアルタイムインデックスから削除され、データノードのメモリ負荷を軽減します。
各インデックステーブルは、常駐ジョブである増分フローに対応しています。フロー内の各ノードの同時実行数を制御することで、リアルタイムデータ処理を向上させることができます。
プロセッサ
プロセッサは、生ドキュメントを処理します。主なタスクには、ビジネスロジックに基づいてフィールドコンテンツの形態素解析または書き換えが含まれます。増分フローでは、プロセッサは長時間実行される分散サービスです。構成を通じて同時実行数を調整することで、データ処理能力を向上させることができます。プロセッサは、複数のデータ処理プラグインの構成をサポートしています。この機能はまだ公開されていません。ご希望の場合は、お問い合わせください。
Builder
Builder は、処理されたドキュメントからインデックスを構築します。Builder は長時間実行されるジョブではありません。Merger と交互に実行されます。各データビルドの後、依存する Merger タスクがインデックスの整理を開始します。整理されたインデックスのみがデータノードに切り替えられます。
Merger
Merger は、Builder によって生成されたインデックスデータを統合および整理します。これにより、結果のインデックスはより整然としてコンパクトになります。データが更新されると、レガシーインデックスには削除対象としてマークされた多くのレコードが含まれます。Merger は、指定されたインデックスマージポリシーに従ってこのデータをクリーンアップおよびマージします。
Retrieval Engine Edition のインデックス構造
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary|
構造名 |
説明 |
|
generation |
`generation_x` は、エンジンがフルインデックスの異なるバージョンを区別するために使用する識別子です。 |
|
partition |
パーティションは、Searcher がインデックスをロードするための基本単位です。1つのパーティションにデータが多すぎると、Searcher のパフォーマンスが低下する可能性があります。オンラインデータは通常、各 Searcher の検索効率を確保するために複数のパーティションに分割されます。 |
|
schema.json |
インデックス構成ファイル。主にフィールド、インデックス、属性、サマリーなどの情報を記録します。エンジンはこのファイルを使用してインデックスをロードします。 |
|
version.0 |
バージョンファイル。主にエンジンが現在のパーティションにロードする必要があるセグメントと、最新のドキュメントのタイムスタンプを記録します。リアルタイムビルド中に、エンジンは増分バージョンのタイムスタンプに基づいてレガシーな生ドキュメントをフィルタリングします。 |
|
segment |
セグメントは、インデックスの基本単位です。セグメントには、ドキュメントの転置インデックスおよびフォワードインデックス構造が含まれます。インデックスビルダーは、各ダンプでセグメントを生成します。複数のセグメントは、マージポリシーに基づいてマージできます。パーティション内の利用可能なセグメントは、バージョンファイルで指定されます。 |
|
segment_info |
セグメント情報サマリー。現在のセグメント内のドキュメント数、セグメントがマージされたかどうか、ロケーター情報、および最新のドキュメントのタイムスタンプを記録します。 |
|
index |
転置インデックスディレクトリ。 |
|
attribute |
フォワードインデックスディレクトリ。 |
|
deletionmap |
削除されたドキュメントレコード。 |
|
summary |
サマリーインデックスディレクトリ。 |
コントロールシステム
コントロールシステムは、OpenSearch Retrieval Engine Edition インスタンスの運用保守プラットフォームです。このプラットフォームは、運用保守コストを大幅に削減します。この運用保守プラットフォームの詳細については、「Retrieval Engine Edition プロダクトドキュメント」をご参照ください。
プロダクト機能
安定性
Retrieval Engine Edition の基盤レイヤーは C++ で実装されています。10年以上の開発を経て、複数のコアビジネスをサポートし、高い安定性が証明されています。高い安定性を必要とするコア検索シナリオに最適です。
効率性
OpenSearch Retrieval Engine Edition は分散検索エンジンです。膨大な量のデータの取得を効率的にサポートします。また、数秒で反映されるリアルタイムデータ更新もサポートしています。クエリレイテンシーに敏感で、リアルタイムデータを必要とする検索シナリオに最適です。
低コスト
OpenSearch Retrieval Engine Edition は、複数のインデックス圧縮ポリシーをサポートしています。また、マルチバリューインデックスロードもサポートしています。これにより、低コストでユーザーのクエリニーズを満たすことができます。
豊富な機能
OpenSearch Retrieval Engine Edition は、さまざまなアナライザタイプ、複数のインデックスタイプ、および強力なクエリ構文をサポートしています。これらの機能は、ユーザーの検索ニーズを効果的に満たすことができます。また、ビジネス処理ロジックをカスタマイズできるプラグインメカニズムも提供しています。
SQL クエリ
OpenSearch Retrieval Engine Edition は、SQL クエリ構文とオンラインマルチテーブル結合をサポートしています。豊富な組み込みユーザー定義関数 (UDF) と UDF カスタマイズメカニズムを提供し、さまざまなユーザーの検索ニーズを満たします。SQL Studio は、SQL クエリの開発とテストを支援するために、まもなく運用保守システムに統合される予定です。