シナリオ
オブジェクトタイプは、主にオブジェクトなどのネストされた構造化データを格納するために使用されます。複数のフィールドを組み合わせてネスト構造を形成できます。これは、ユーザー情報や注文の詳細など、複雑なデータの処理に特に適しています。オブジェクトタイプを適切に使用することで、ネストされた複雑なデータ構造をより効果的に管理およびクエリし、検索と分析の効率を高めることができます。
手順
はじめに を参照して、インスタンスを購入し、クラスタを構成できます。[インデックススキーマ] 構成ステップで、管理するフィールドのオブジェクトフィールドタイプを選択します。次に、スキーマ構成エントリが表示されます。エントリをクリックして、スキーマ構成の完全な JSON を入力して保存します。
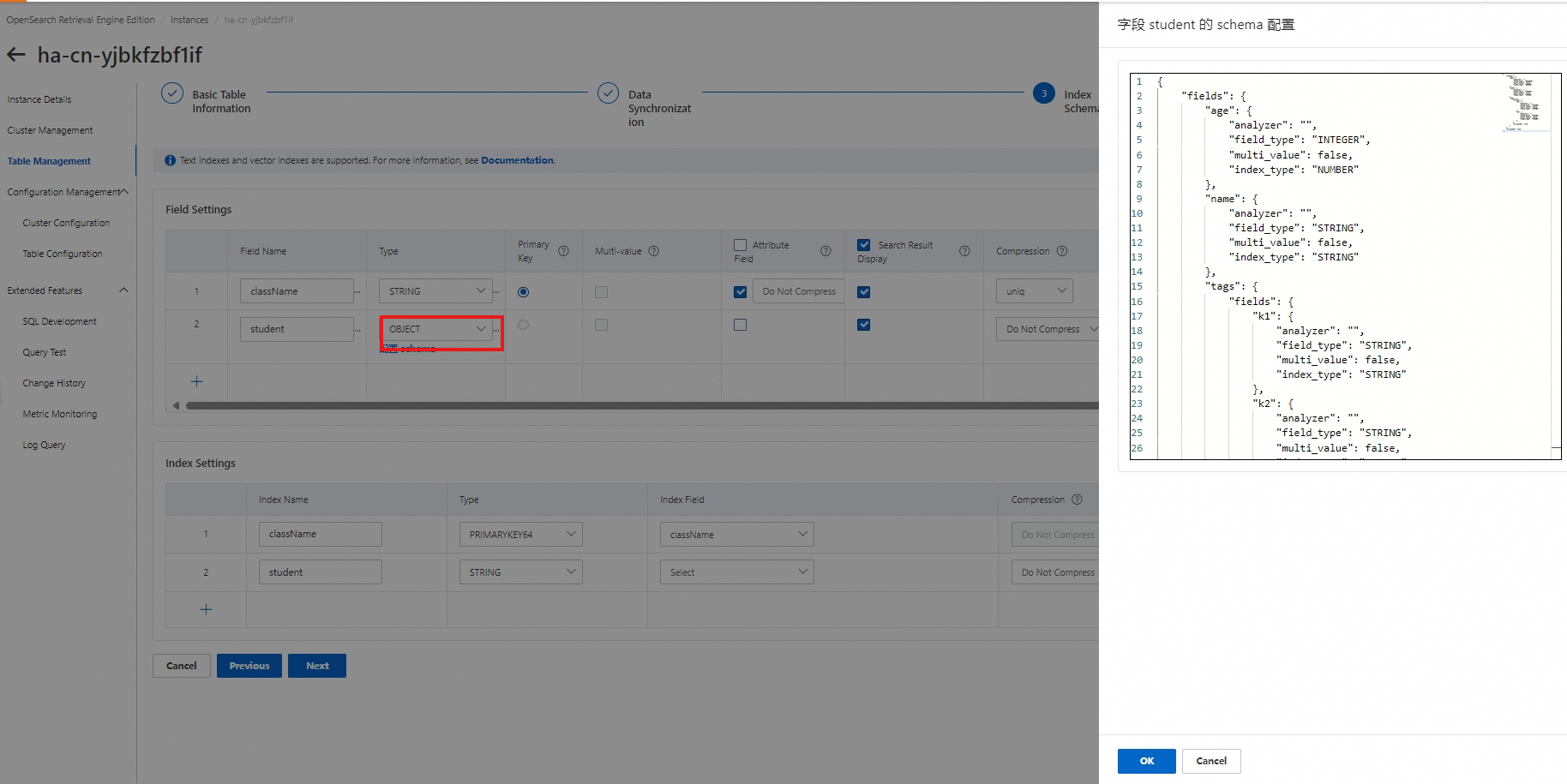
サンプルユーザーオブジェクトスキーマ構成
{
"fields": {
"age": {
"analyzer": "", // アナライザ
"field_type": "INTEGER", // フィールドタイプ
"multi_value": false, // 複数値
"index_type": "NUMBER" // インデックスタイプ
},
"name": {
"analyzer": "", // アナライザ
"field_type": "STRING", // フィールドタイプ
"multi_value": false, // 複数値
"index_type": "STRING" // インデックスタイプ
},
"tags": {
"fields": {
"k1": {
"analyzer": "", // アナライザ
"field_type": "STRING", // フィールドタイプ
"multi_value": false, // 複数値
"index_type": "STRING" // インデックスタイプ
},
"k2": {
"analyzer": "", // アナライザ
"field_type": "STRING", // フィールドタイプ
"multi_value": false, // 複数値
"index_type": "STRING" // インデックスタイプ
}
},
"is_nested": true // ネストされているか
}
},
"is_nested": true // ネストされているか
}analyzer(オプション): トークナイザ。サポートされている アナライザ を参照できます。
field_type(必須): 基本フィールドデータタイプ。詳細については、「OpeanSearch Retrieval Engine Edition の組み込みフィールドタイプ」をご参照ください。
multi_value(オプション): フィールドに複数の値があることを指定します。デフォルト値は false です。フィールドがネストされていない場合、元の値は無視され、true に設定されます。
is_attribute(オプション): デフォルト値は true です。
index_type(オプション): インデックスタイプ。pack タイプはサポートされていません。詳細については、「転置インデックスタイプ」をご参照ください。
is_nested(オプション): デフォルト値は false です。独立したストレージが必要な場合は、true に設定します。
オブジェクトタイプのフィールド:
プライマリキーとして設定できません。
分析構成をサポートしていません。
複数値をサポートしていません。
すべてのタイプのインデックスで、含まれるフィールドはオブジェクトタイプを除外します。
サンプルユーザーソースデータ
全データ
JSON 形式
{ "className": "c1", // クラス名 "students": [{ // 生徒 "age": 6, // 年齢 "name": "s1", // 名前 "tags": [{ // タグ "k1": "v1", // キー1 "k2": "v2" // キー2 }, { "k1": "v11", // キー1 "k2": "v22" // キー2 }] }] }ha3 形式
CMD=add^_ className=c1^_ // クラス名 students=[{"age":6,"name":"s1","tags":[{"k1":"v1","k2":"v2"},{"k1":"v11","k2":"v22"}]}]^_ // 生徒 ^^リアルタイム
[ { "cmd": "add", // 追加 "fields": { // フィールド "className": "c1", // クラス名 "students": "[{\"age\":6,\"name\":\"s1\",\"tags\":[{\"k1\":\"v1\",\"k2\":\"v2\"},{\"k1\":\"v11\",\"k2\":\"v22\"}]}]" // 生徒 } } ]
クエリの例
テーブル構成が完了したら、[拡張機能] -> [クエリテスト] でクエリを実行します。
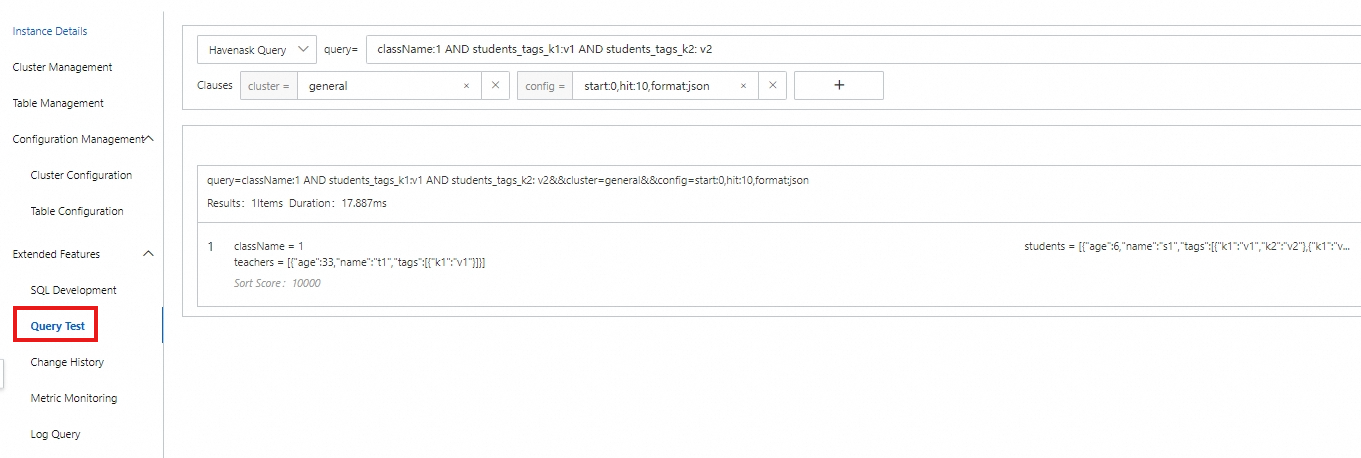
OBJECT の内部フィールドの場合は、ルートノードから _ を使用して連結します。ここで、フィールド名とインデックス名は同じです。
例 1
クエリ条件: className が c1、students -> tags -> k1 が v1、students -> tags -> k2 が v22
クエリステートメント: query=className:c1 AND students_tags_k1:v1 AND students_tags_k2:v22
クエリ結果: 独立したストレージのため、クエリでは結果が返されません。
例 2
クエリ条件: className が c1、students -> tags -> k1 が v1、students -> tags -> k2 が v2
クエリステートメント: query=className:c1 AND students_tags_k1:v1 AND students_tags_k2:v2
クエリ結果: クエリは c1 の関連情報を返します。
{
...
"className": "c1", // クラス名
"students": "[{\"age\":6,\"name\":\"s1\",\"tags\":[{\"k1\":\"v1\",\"k2\":\"v2\"},{\"k1\":\"v11\",\"k2\":\"v22\"}]}]" // 生徒
....
}