概要
OpenSearch LLMベースの会話型検索エディションは、複数のベクトルモデル、スパースベクトルモデル、スライス方法、および画像コンテンツ認識モデルを提供します。
手順
1. インスタンスのデータ構成ページで、構成の変更をクリックします。

2. 表示されたページで、ビジネス要件に基づいて、ベクトルモデル、スパースベクトルモデル、スライス方法、および画像コンテンツ認識モデルを選択します。次に、[次へ] をクリックします。
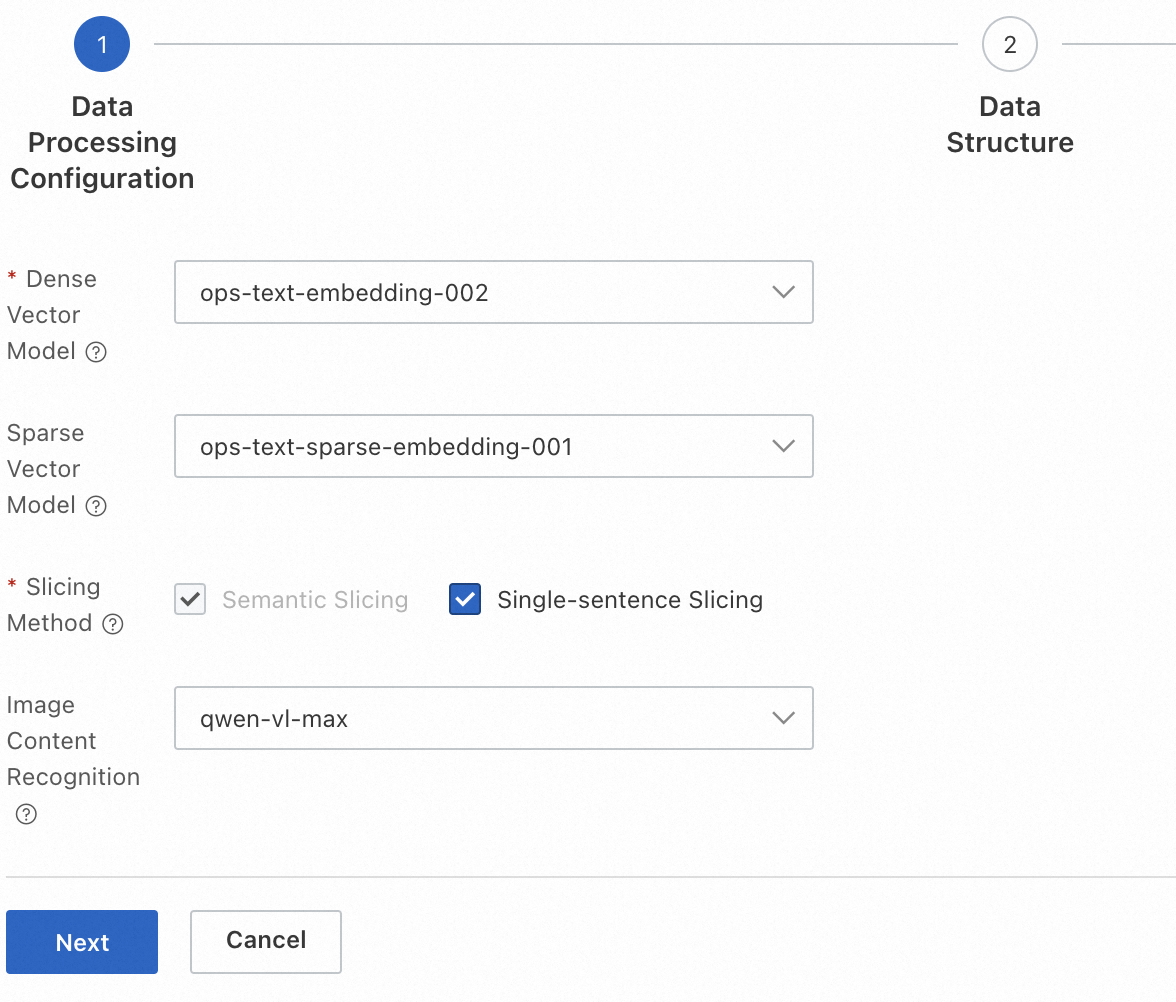
ベクトルモデル: ベクトルモデルは、テキストを密ベクトルに変換します。これにより、長いテキストや意味記述の理解が容易になり、クエリが最適化されます。
スパースベクトルモデル: スパースベクトルモデルは、テキストをスパースベクトルに変換します。これにより、フィルタリング条件を含むクエリが最適化されます。スパースベクトルモデルは、密ベクトルモデルと併用する必要があります。ほとんどの場合、スパースベクトルモデルと密ベクトルモデルの組み合わせは、密ベクトルモデル単体よりも効果的です。スパースベクトルモデルを選択することをお勧めします。
スライス方法:
セマンティックスライス: テキストは、テキストのセマンティクスに基づいてスライスされます。デフォルトでは、このスライス方法が使用されます。
単一文スライス: テキストは文ごとにスライスされます。このスライス方法は、長いドキュメントのクエリ精度を向上させます。単一文スライス方法を選択すると、単一のドキュメントが占有するストレージ容量が約6倍に増加することに注意してください。
画像コンテンツ認識: マルチモーダルモデルを使用して画像コンテンツを認識します。この機能は、参照画像の精度を向上させます。注: 画像コンテンツ認識モデルを選択すると、ドキュメントのアップロード時にモデルに必要なコンピューティングリソースに対して課金されます。
2. データ構造ステップで、ビジネス要件に基づいてカスタムテーブルフィールドを追加、削除、または変更し、[次へ] をクリックします。

メインテーブルの7つのフィールドはシステムで必須であり、変更できません。
カスタムテーブルの構成方法の詳細については、テーブルベースの会話型検索の実装を参照してください。
3. データソースステップで、テーブルにデータソースを追加する場合は、[データソースの追加] をクリックし、プロンプトに従ってデータソースを追加します。詳細については、テーブルベースの会話型検索の実装を参照してください。データソースを追加する必要がない場合は、[完了] をクリックします。

4. 新しい構成が有効になるまで待ちます。
