アプリケーションスキーマ
Industry Algorithm Edition インスタンスにプッシュされたデータは、まずオフラインデータテーブルに保存されます。データプッシュプロセスを簡素化するために、複数のテーブルを定義し、データ処理プラグインを使用できます。テーブルの外部キーフィールドを指定する必要があります。データ処理が完了すると、テーブルが結合されてインデックステーブルが形成されます。このインデックステーブルは、エンジンがインデックスを構築し、クエリを実行するために使用する検索属性を定義します。
データテーブルのフィールド
データテーブルはデータのインポートに使用されます。フィールドタイプの要件は、データ処理プラグインによって異なります。フィールドの値の範囲に関する詳細については、「制限事項」の「フィールドの制限」セクションをご参照ください。値が指定された範囲外の場合、オーバーフローまたは切り捨てが発生します。したがって、正しいフィールドタイプを選択するようにしてください。
タイプ | 説明 |
INT | 64 ビット整数。 |
INT_ARRAY | 64 ビット整数配列。 |
FLOAT | 浮動小数点数。 |
FLOAT_ARRAY | 浮動小数点数配列。 |
DOUBLE | 浮動小数点数。 |
DOUBLE_ARRAY | 浮動小数点数配列。 |
LITERAL | 文字列リテラル。完全一致のみをサポートします。 |
LITERAL_ARRAY | 文字列リテラル配列。単一の要素は完全一致のみをサポートします。 |
SHORT_TEXT | ショートテキスト。長さは 100 バイト以内である必要があります。いくつかのトークン化メソッドをサポートします。 |
TEXT | ロングテキスト。いくつかのトークン化メソッドをサポートします。 |
TIMESTAMP | 64 ビット符号なし整数。タイムスタンプデータ。 |
GEO_POINT | 文字列リテラル。「経度 緯度」のフォーマットの経度と緯度のフィールド。 |
JSON オブジェクト配列を表します。フラット化ストレージを使用し、オブジェクトの境界を失います。 | |
JSON オブジェクト配列を表します。プライマリドキュメントとセカンダリドキュメントに対して独立したストレージを使用し、オブジェクトの完全性を保持します。 |
予約語に関する注意事項:
次の予約語はフィールド名として使用できません:['service_id', 'ops_app_name', 'inter_timestamp', 'index_name', 'pk', 'ops_version', 'ha_reserved_timestamp', 'summary']。
ARRAY 型に関する注意事項:
ARRAY 型のアプリケーションフィールドを作成する場合、フィールドマッピング中にデータソースから varchar や string などの文字列型のフィールドにマッピングできます。その後、データ処理プラグインを使用してデータソースフィールドを解析できます。詳細については、「データ処理プラグイン」をご参照ください。
API または SDK を使用して ARRAY 型のフィールドをプッシュする場合、文字列としてではなく、配列としてプッシュしてください。例:String[] literal_array = {"Alibaba Cloud","OpenSearch"};
タイムスタンプフィールドに関する注意事項:
INT および TIMESTAMP 型のフィールドを、データソース内の datetime または timestamp フィールドにマッピングできます。値は自動的にミリ秒に変換されます。検索中、範囲クエリを使用して、時間間隔に基づいて結果をフィルター処理および取得できます。
サポートされているデータソースのフィールドタイプ
データソース | サポートされているフィールドタイプ |
RDS | TINYINT,SMALLINT,INTEGER,BIGINT,FLOAT,REAL,DOUBLE,NUMERIC,DECIMAL,TIME,DATE,TIMESTAMP,VARCHAR |
PolarDB | TINYINT,SMALLINT,INTEGER,BIGINT,FLOAT,REAL,DOUBLE,NUMERIC,DECIMAL,TIME,DATE,TIMESTAMP,VARCHAR |
MaxCompute (旧称 ODPS) | BIGINT,DOUBLE,BOOLEAN,DATETIME,STRING,DECIMAL,MAP,ARRAY,TINYINT,SMALLINT,INT,FLOAT,CHAR,VARCHAR,DATE,TIMESTAMP,BINARY,INTERVAL_DAY_TIME,INTERVAL_YEAR_MONTH,STRUCT |
Industry Algorithm Edition テーブルとデータベーステーブルのフィールドタイプのマッピング
Industry Algorithm Edition テーブル | RDS テーブル | PolarDB テーブル | MaxCompute テーブル |
INT | BIGINT,TINYINT,SMALLINT,INTEGER | BIGINT,TINYINT,SMALLINT,INTEGER | BIGINT,TINYINT,SMALLINT,INT |
INT_ARRAY | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 |
FLOAT | FLOAT,NUMERIC,DECIMAL | FLOAT,NUMERIC,DECIMAL | FLOAT,DECIMAL |
FLOAT_ARRAY | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 |
DOUBLE | DOUBLE,NUMERIC,DECIMAL | DOUBLE,NUMERIC,DECIMAL | DOUBLE,DECIMAL |
DOUBLE_ARRAY | VARCHAR などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 |
LITERAL | VARCHAR などの文字列型。 | VARCHAR などの文字列型。 | VARCHAR や STRING などの文字列型。 |
LITERAL_ARRAY | VARCHAR などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 | VARCHAR や STRING などの文字列型。MultiValueSpliter データ処理プラグインを使用してデータを変換する必要があります。 |
SHORT_TEXT | VARCHAR などの文字列型。 | VARCHAR などの文字列型。 | VARCHAR や STRING などの文字列型。 |
TEXT | VARCHAR などの文字列型。 | VARCHAR などの文字列型。 | VARCHAR や STRING などの文字列型。 |
TIMESTAMP | datetime または timestamp 型。 | datetime または timestamp 型。 | datetime または timestamp 型。 |
GEO_POINT | VARCHAR などの文字列型。 | VARCHAR などの文字列型。 | 「lon lat」フォーマットの VARCHAR や STRING などの文字列型。「lon」は経度、「lat」は緯度を表します。両方の値は double 型で、スペースで区切られている必要があります。「lon」の値の範囲は [-180, 180]、「lat」の値の範囲は [-90, 90] です。 |
注:
データソースのフィールドが FLOAT または DOUBLE 型の場合、その型を DECIMAL に変更してください。そうしないと、精度の問題が発生する可能性があります。
アプリケーションスキーマの作成方法
Industry Algorithm Edition は、アプリケーションスキーマ (Industry Algorithm Edition のテーブルスキーマ) を作成するために、次の 4 つの方法を提供します:
データソース (RDS、MaxCompute、または PolarDB) から作成。
手動で作成 (下記の テーブル結合の設定 セクションをご参照ください)。
テーブル結合の設定
このセクションでは、アプリケーションスキーマを手動で作成してテーブル結合を設定する方法について説明します。この例では、main (プライマリテーブル) と test_tb_1 (セカンダリテーブル) の 2 つのテーブルを使用します。
コンソールにログインし、[設定] をクリックします:

プライマリテーブルを選択して、プライマリキーを設定します。
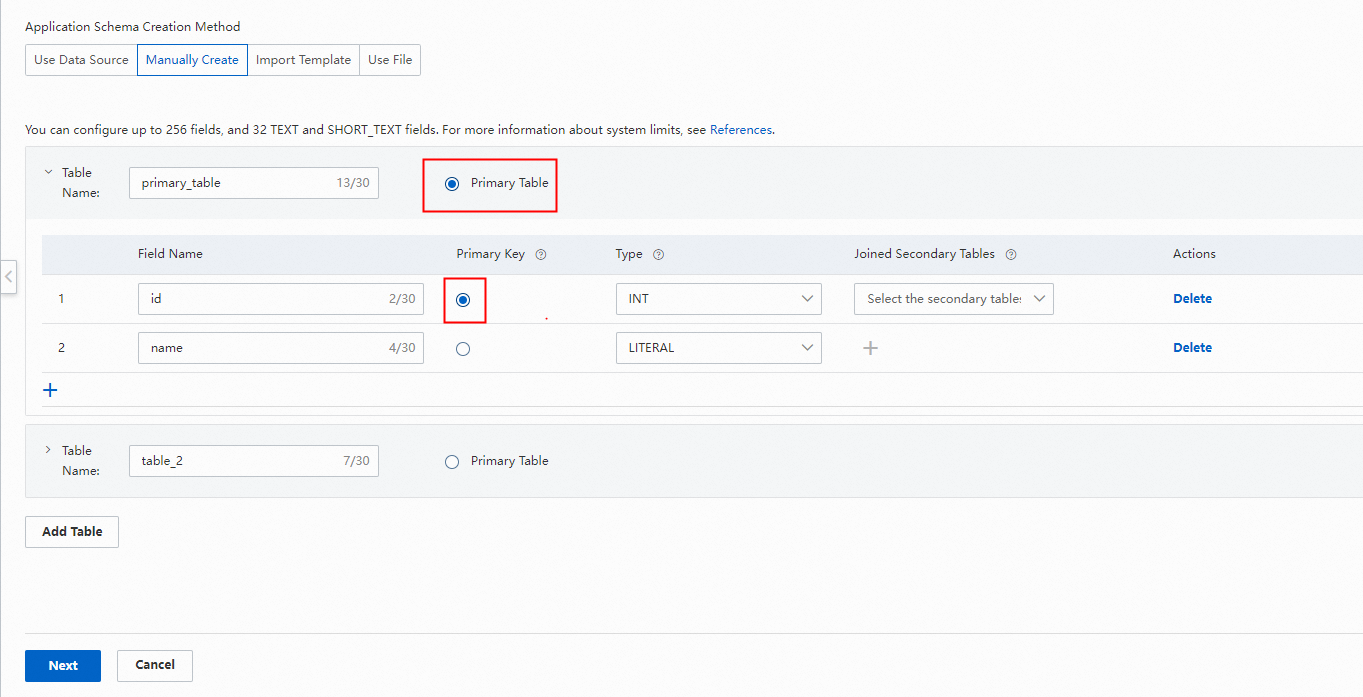
セガンダリテーブルのプライマリキーを設定します。
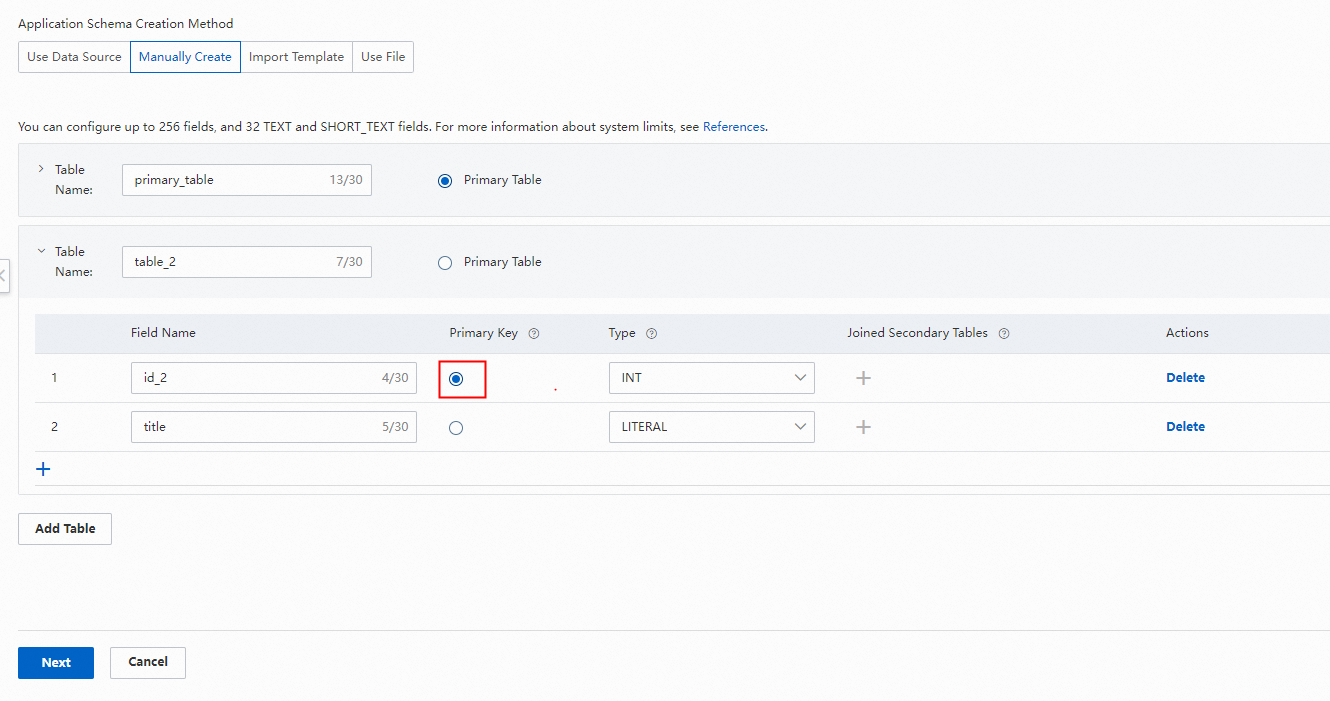
プライマリテーブルとセカンダリテーブルの関連付けを設定します。これはプライマリテーブルで設定します。
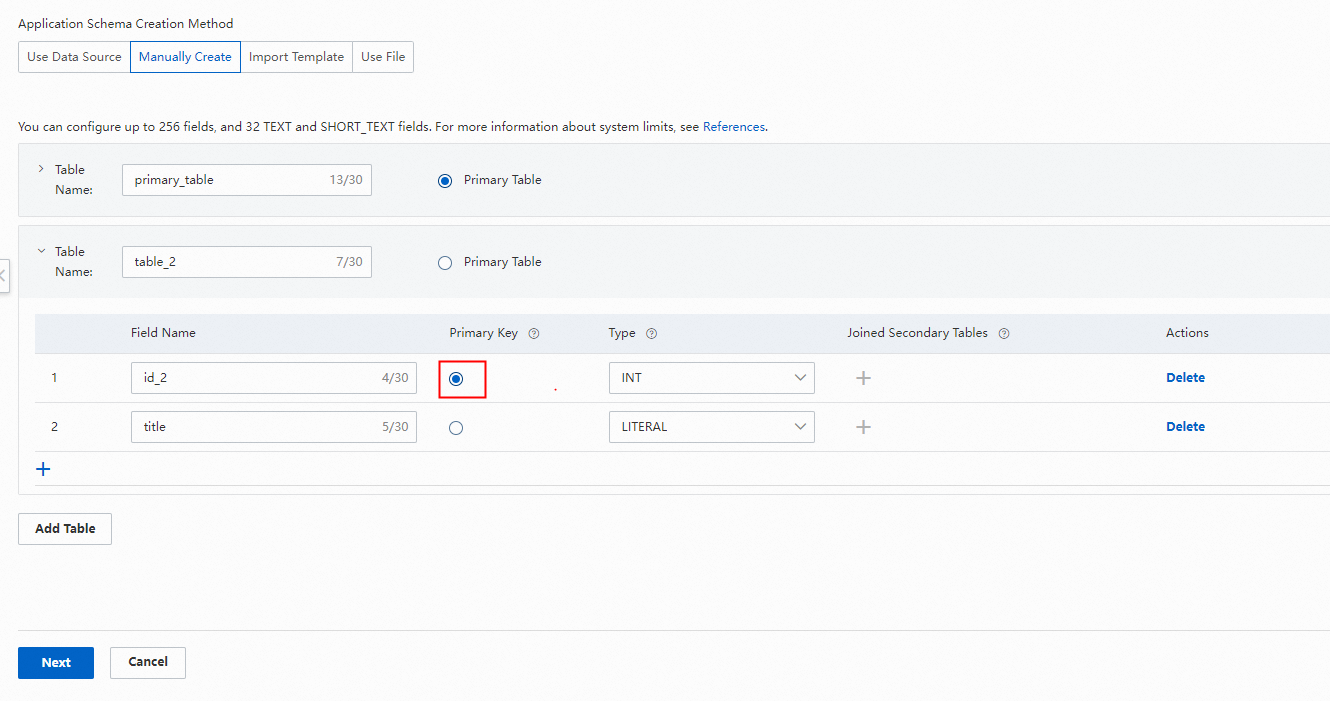
Industry Algorithm Edition でサポートされているプライマリ/セカンダリテーブルのデータ関連付けの詳細については、「テーブル結合の作成」をご参照ください。
int または literal 型のフィールドのみが外部キーフィールドとして使用できます。
プライマリテーブルとセカンダリテーブルを結合する場合、結合フィールドは同じデータ型である必要があります。たとえば、一方のフィールドが int 型の場合、もう一方も int 型である必要があります。一方のフィールドが literal 型の場合、もう一方も literal 型である必要があります。
セカンダリテーブルをプライマリテーブルに結合する場合、セカンダリテーブルのプライマリキーを使用してプライマリテーブルのフィールドと結合する必要があります。セカンダリテーブルの非プライマリキーフィールドを結合に使用することはできません。