Cava は、OpenSearch エンジンチームが低レベル仮想マシン (LLVM) プロジェクトをベースに開発したプログラミング言語です。Java に似た構文を使用し、オブジェクト指向設計、Just-In-Time (JIT) コンパイル、組み込みのセキュリティチェックにより、C++ レベルのパフォーマンスを実現します。
Cava を使用して、OpenSearch の高度なソート用のカスタムソートプラグインを作成します。OpenSearch の式と比較して、Cava ソートプラグインには次の特徴があります。
| ディメンション | Cava ソートプラグイン | 式 |
|---|---|---|
| 構文の特徴 | for ループ、関数定義、クラス定義 | 限定された演算子とビルトイン関数 |
| カスタマイズ | コードによるビジネスロジックの完全な実装 | 式の文法による制約 |
| 保守性 | 可読性が高く構造化されたコード | コンパクトだが、大規模になると可読性が低下 |
| 学習曲線 | Java 開発者にとって馴染みやすい | 式の構文を学習する必要がある |
Cava ベースのソートプラグインは、専用アプリケーションでのみ機能し、高度なソートにのみ適用されます。Cava の構文の詳細については、『開発者ガイド』の Cava ベースのソートプラグインに関するトピックをご参照ください。
仕組み
Cava ソートポリシーには、ランキングロジックを実装する 1 つ以上の Cava スクリプトファイルが含まれます。ワークフローは以下の通りです。
タイプが [Cava Script] で、範囲が [Fine Sort] のソートポリシーを作成します。
コンソールでスクリプトファイルを追加・編集するか、JSON フォーマットでアップロードします。
すべてのスクリプトファイルをコンパイルし、ポリシーを公開します。
SDK または検索テストでポリシー名とタイプを参照します。
公開されると、Cava スクリプトは高度なソート中に実行され、ロジックに従ってドキュメントのスコアリングとランキングを行います。Cava は for ループ、関数定義、クラス定義などの構文機能をサポートしており、OpenSearch の式で許可されている範囲を超えて、ランキングロジックを完全に制御できます。
前提条件
開始する前に、以下をご確認ください。
OpenSearch の専用アプリケーションがあること
OpenSearch コンソールの [ポリシー管理] ページへのアクセス権があること
Cava ソートプラグインの作成とデプロイ
ステップ 1:ソートポリシーの作成
[ポリシー管理] に移動し、[作成] をクリックします。
[ポリシーの作成] ページで、[範囲] を [高度なソート] に、[タイプ] を [Cava スクリプト] に設定します。
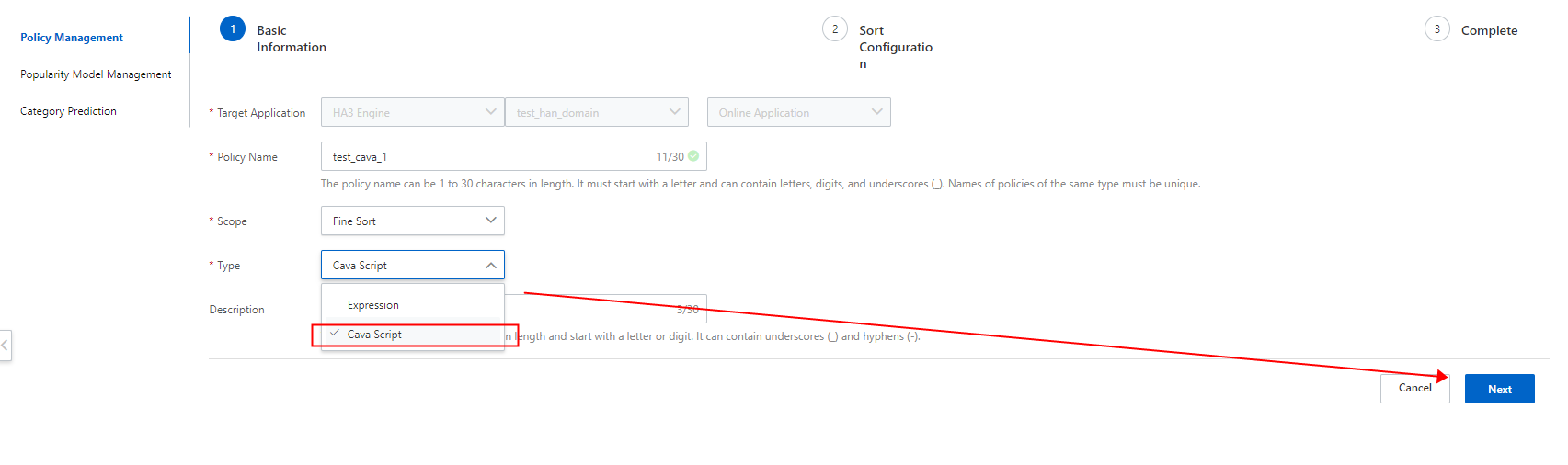
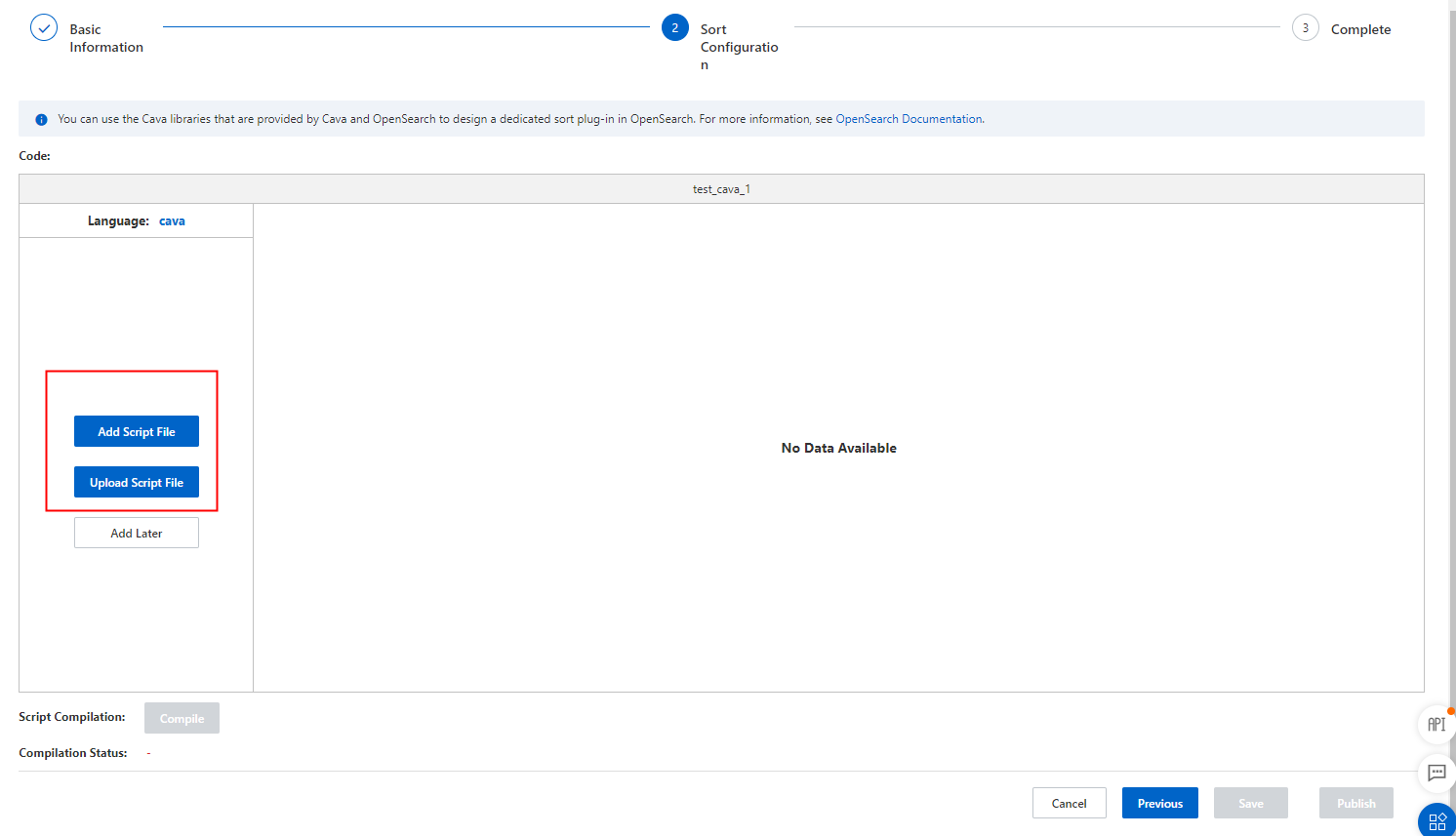
ステップ 2:スクリプトファイルの追加
いずれかの方法でスクリプトファイルを追加します。
コンソールエディターで Cava スクリプトを直接編集します。
ローカルのスクリプトファイルを JSON フォーマットでアップロードします。
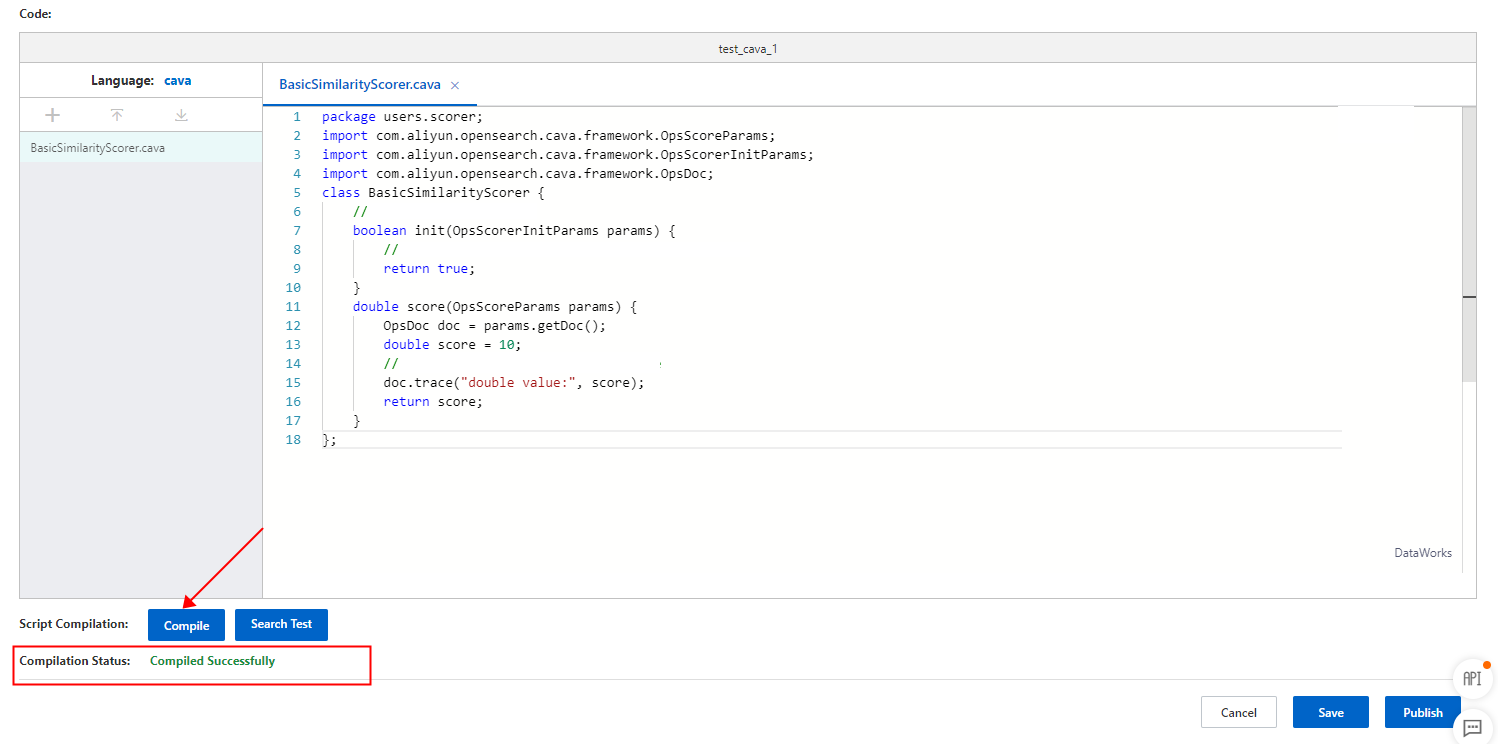
ステップ 3:コンパイルと公開
[コンパイル] をクリックして、すべてのスクリプトファイルをコンパイルします。コンパイルステータスは [コンパイル] ボタンの下に表示されます。
コンパイルが成功したら、[公開] をクリックします。
公開されたスクリプトは変更できません。公開済みのポリシーを更新するには、[ポリシー管理] ページでポリシーを複製し、そのコピーを編集してください。
ステップ 4:ソートポリシーのテスト
ポリシーの [検索テスト] ページで、以下のパラメーターを設定します。
| パラメーター | 値 |
|---|---|
second_rank_name | ソートポリシーの名前 |
second_rank_type | cava_script |

以下の Java の例は、SDK でこれらのパラメーターを設定する方法を示しています。
// SearchParams オブジェクトを作成します
SearchParams searchParams = new SearchParams(config);
// Cava ソートポリシーを設定します
Rank rank = new Rank();
rank.setSecondRankName("Cava script name"); // 公開されたソートポリシーの正確な名前
rank.setSecondRankType(RankType.CAVA_SCRIPT); // 高度なソート中に Cava スクリプトを呼び出します
// rank 設定を検索リクエストにアタッチします
searchParams.setRank(rank);SDK で参照されるスクリプトは公開されている必要があります。未公開のスクリプトは、検索テストでのみ使用できます。
共通パラメーターの取得
ベクトルインデックスのスコア
ProximaScore を使用して、ベクトルインデックスから類似度スコアを取得します。ProximaScore.create() を呼び出して名前付きインデックスにバインドし、次に evaluate() を呼び出して各ドキュメントのスコアを取得します。
import com.aliyun.opensearch.cava.features.similarity.ProximaScore;
// ターゲットのベクトルインデックスにバインドします
ProximaScore _proximaScoreVector;
_proximaScoreVector = ProximaScore.create(params, "{{indexes.vector_index}}"); // ご利用のベクトルインデックス名に置き換えてください
// 現在のドキュメントの類似度スコアを取得します
float proximaScoreVector = _proximaScoreVector.evaluate(params);制限事項
| 制限 | 値 |
|---|---|
| 最大スクリプトファイルサイズ | ファイルあたり 10 KB |
| ソートポリシーあたりの最大スクリプトファイル数 | 5 |
| アプリケーションインスタンスあたりの最大 Cava ソートポリシー数 | 50 |
| 公開後のスクリプトの変更 | サポートされていません — ポリシーを複製して変更を加えてください |
| SDK スクリプト | 使用前に公開する必要があります |
| 未公開のスクリプト | 検索テストでのみ利用可能 |
次のステップ
Cava 言語の構文を学習する:『開発者ガイド』の Cava ベースのソートプラグインに関するトピックをご参照ください。