このトピックでは、分散タスクスケジューラ XXL-JOB と大規模言語モデル DeepSeek を使用して、トレンドの金融ニュースを定期的に自動プッシュし、金融データを分析する方法について説明します。
背景情報
大規模 AI モデルの能力が向上するにつれて、そのビジネスアプリケーションは拡大しています。多くのビジネスシナリオは、手動で開始する代わりに、バックグラウンドで定期タスクとして自動的に実行できます。これらのタスクは、大規模言語モデルの能力で強化できます。以下は一般的なシナリオです。
リスク監視: 定期的に主要なシステムメトリックを監視し、大規模言語モデルのスマート分析を使用して潜在的な脅威を検出できます。
データ分析: 定期的にオンラインの金融データを収集し、大規模言語モデルを使用してインテリジェントな分析を行い、投資家向けの意思決定アドバイスを生成できます。
前提条件
Alibaba Cloud Model Studio コンソールで Alibaba Cloud Model Studio を有効化し、API-KEY を作成済みであること。
環境の準備
DeepSeek のセットアップ
以下の理由から、DeepSeek 大規模言語モデルを選択しました。
DeepSeek はその推論能力で知られており、データ分析に適しています。DeepSeek の親会社である High-Flyer Quant は、定量取引を専門としています。そのため、DeepSeek はデータ分析において大きな利点があると考えられます。
DeepSeek はオープンソースで軽量なため、デプロイが容易です。
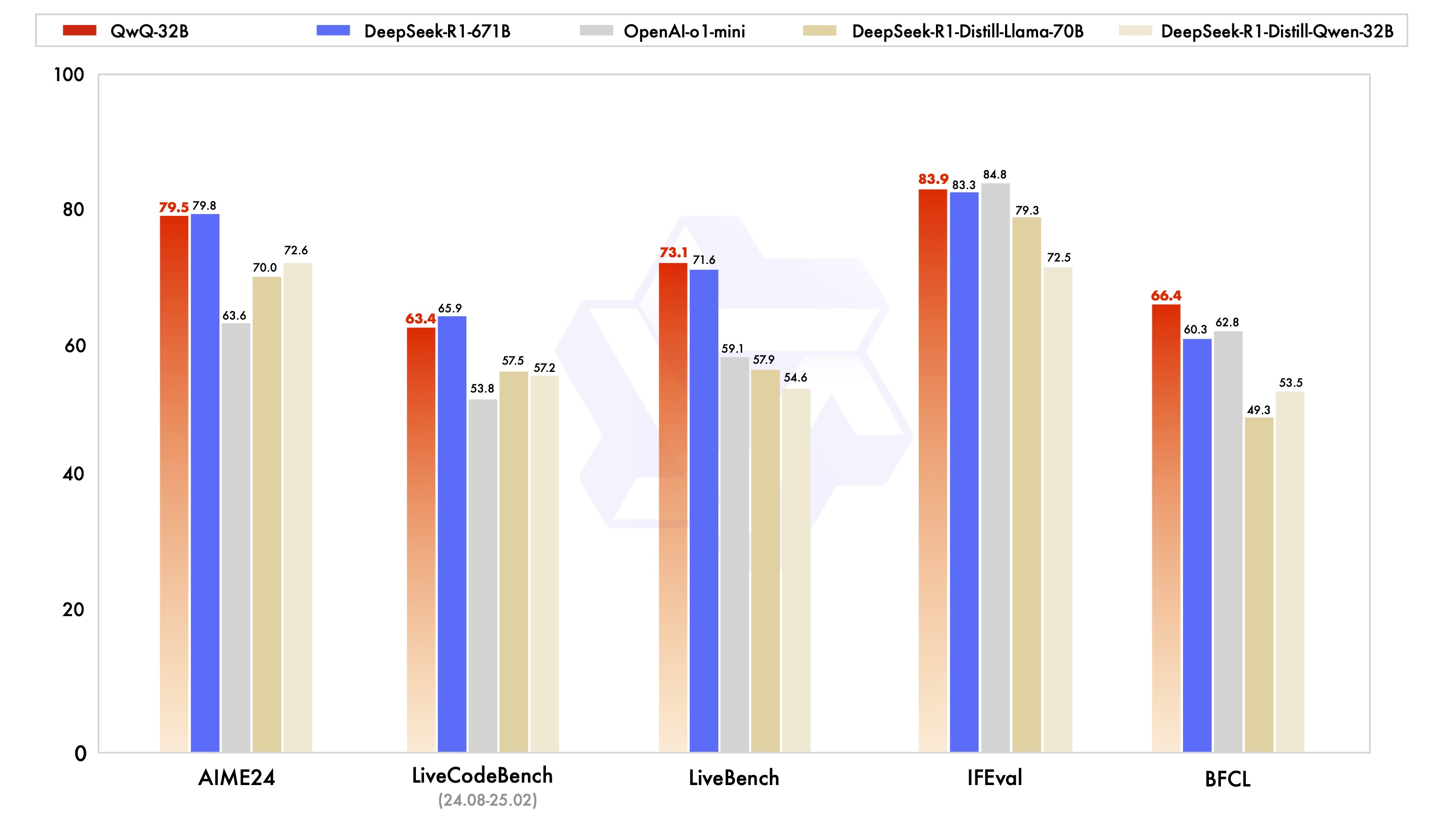
また、Alibaba Cloud の最新のオープンソースモデルである QwQ を選択することもできます。その推論能力は DeepSeek-R1 に匹敵し、複雑なデータ分析にも優れています。以下のチャートは、QwQ-32B と他の主要モデルの数学的推論、プログラミング、および一般的な能力を比較したものです。
オプション 1: ローカルでのデプロイ
DeepSeek、QwQ、または他のモデルをローカルにデプロイする手順は似ています。以下の手順では、DeepSeek を例として使用します。
https://ollama.com/download から ollama をインストールします。
DeepSeek-R1 モデルをインストールします。R1 モデルは複雑な論理的推論に重点を置いており、データ分析により適しています。
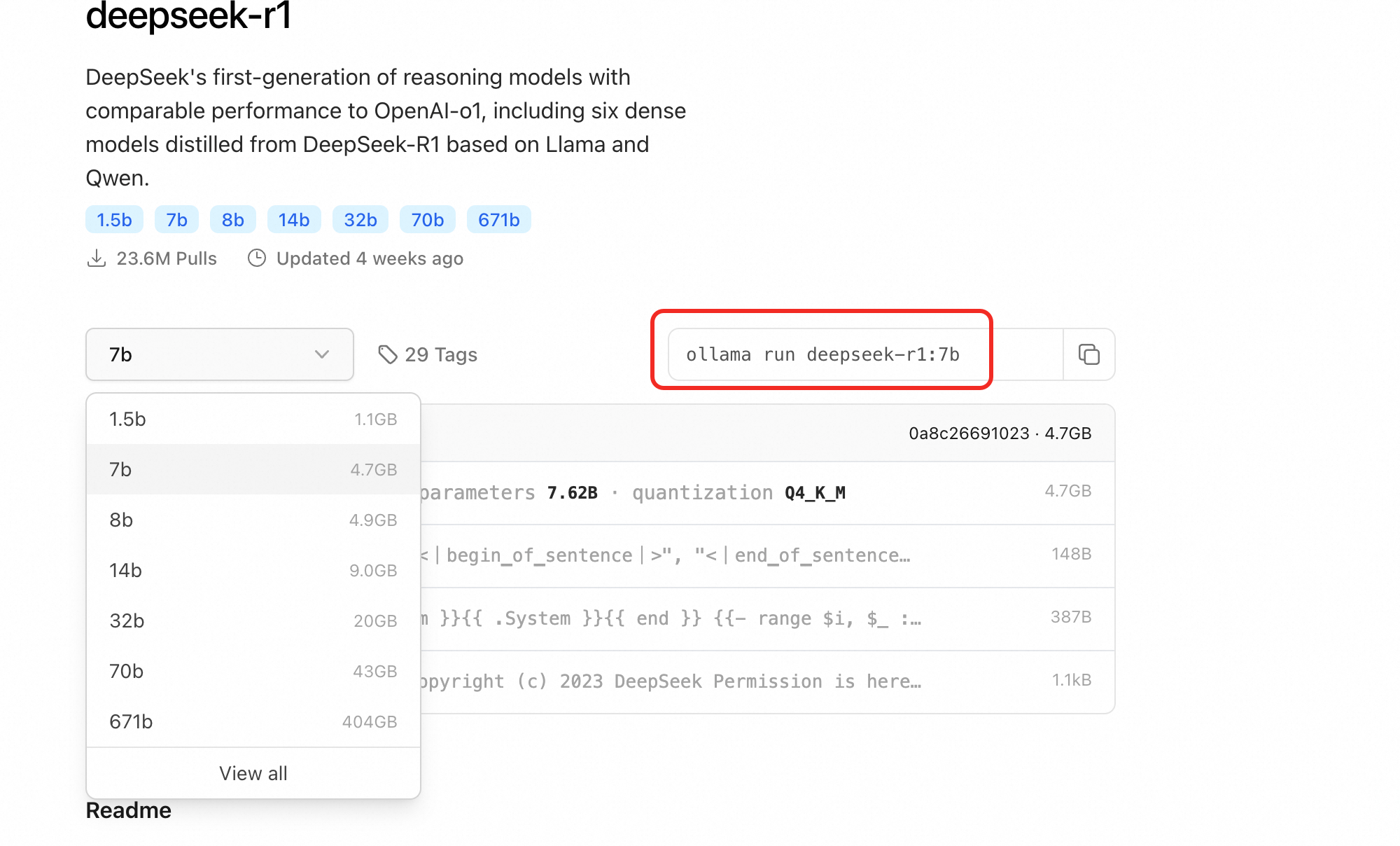
お使いのマシンの仕様に基づいてモデルを選択します。たとえば、お使いのコンピューターのメモリが 16 GB の場合は、7b モデルを選択します。次に、以下のコマンドを実行してインストールします。

次の表に、さまざまなモデルのハードウェア要件を示します。
モデル名
モデルサイズ
GPU メモリ
メモリ
deepseek-r1:1.5b
1.1 GB
4 GB+
8 GB+
deepseek-r1:7b
4.7 GB
8 GB+
16 GB+
deepseek-r1:8b
4.9 GB
10 GB+
18 GB+
deepseek-r1:14b
9.0 GB
16 GB+
32 GB+
deepseek-r1:32b
20 GB
24 GB+
64 GB+
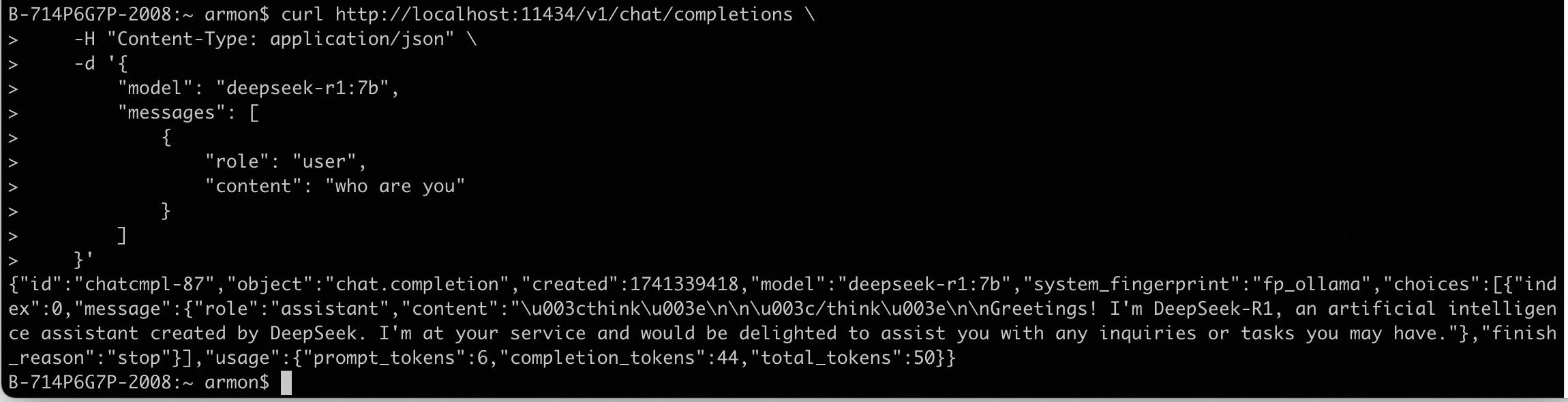
デプロイが完了したら、OpenAI 互換 API を使用してテストします。デフォルトポートは 11434 です。この API を使用すると、後のコード作成が容易になります。
オプション 2: クラウドプロダクトの使用
Alibaba Cloud Model Studio などのクラウドプロダクトを直接使用することもできます。有効化後すぐに使用を開始でき、大規模な無料クォータが付属しています。クラウドプロダクトを使用するもう 1 つの利点は、いつでもモデルを切り替えて、それぞれの長所と短所を体験できることです。
XXL-JOB のセットアップ
XXL-JOB を使用すると、以下の利点があります。
定期的に AI タスクリクエストを送信できます。
タスクパラメーターで
promptと応答フォーマットを指定して、動的な変更を許可できます。ブロードキャストシャーディングタスクを使用して、大規模なタスクをより小さなサブタスクに分割できます。これにより、AI タスクの実行が高速化されます。
タスク依存関係のオーケストレーションを使用して、AI データ分析フローを構築できます。
オプション 1: ローカルでのデプロイ
XXL-JOB のデプロイは簡単です。詳細な手順については、公式ウェブサイトをご参照ください。一般的な手順は次のとおりです。
データベースを準備し、データベーステーブルスキーマを初期化します。
コードを IDE にインポートし、
xxl-job-adminの設定ファイルを構成します。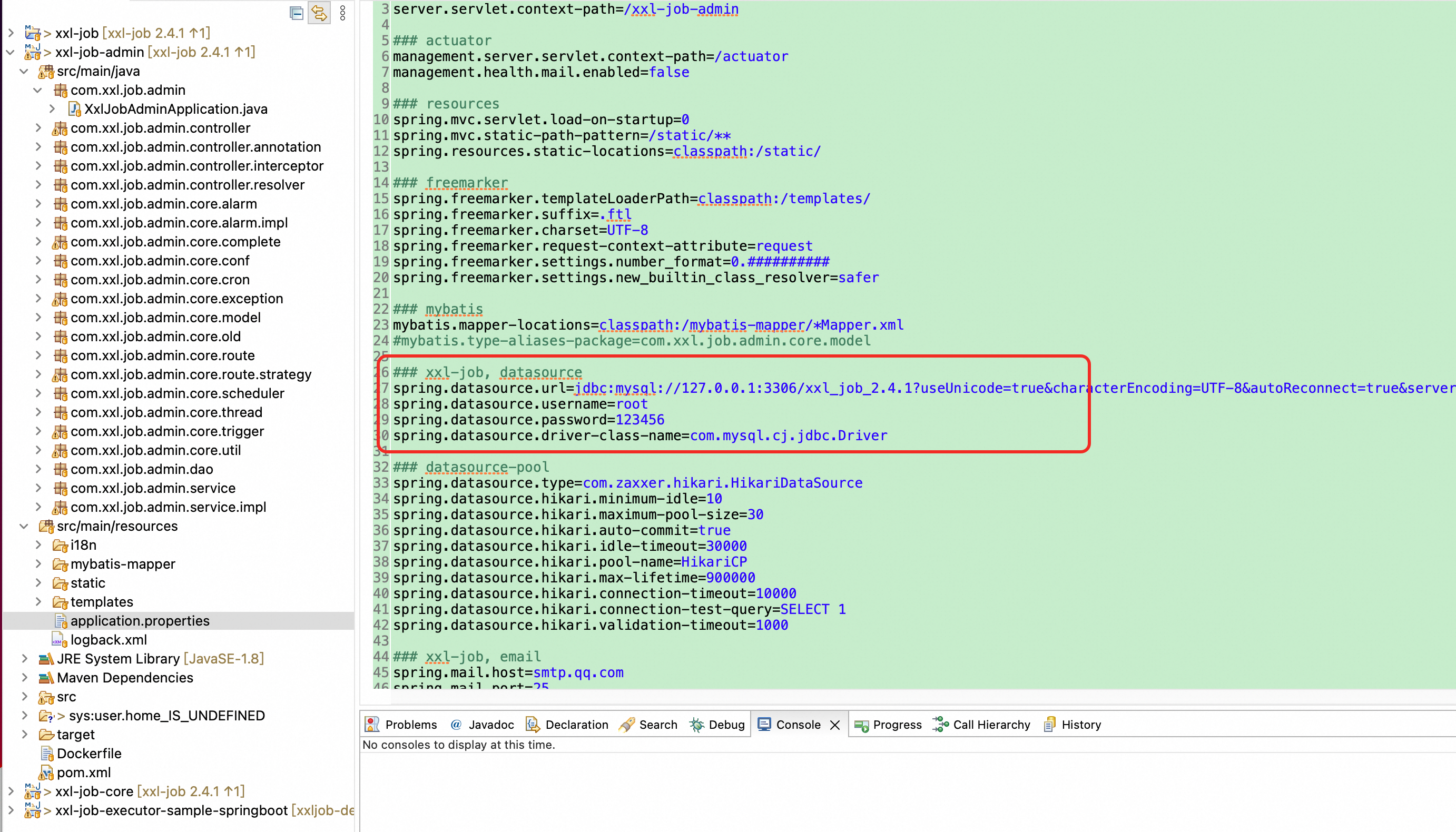
XxlJobAdminApplicationクラスを実行します。次に、ブラウザでhttp://127.0.0.1:8080/xxl-job-adminと入力してログインします。デフォルトのユーザー名とパスワードは admin と 123456 です。
オプション 2: クラウドプロダクトの使用
マネージド型の Alibaba Cloud MSE XXL-JOB バージョンを使用できます。詳細については、「XXL-JOB インスタンスの作成」をご参照ください。無料トライアルも利用できます。
ホットニュースのプッシュ
この例では、MSE XXL-JOB バージョンまたはセルフホスト型の XXL-JOB と、Alibaba Cloud Model Studio でホストされている DeepSeek-R1 を使用してソリューションを実装する方法を示します。デモの詳細については、xxljob-demo (SpringBoot) をご参照ください。
ステップ 1: アプリケーションを XXL-JOB スケジューリングプラットフォームに接続する
Alibaba Cloud Container Service for Kubernetes (ACK) コンソールにログインし、ACK サーバーレスクラスターを作成します。デモイメージをプルするには、現在の VPC に対して SNAT (サーバー名アドレス変換) を有効にして設定する必要があります。VPC に SNAT がすでに設定されている場合は、このステップをスキップできます。
ACK コンソールの [クラスター] ページで、ターゲットクラスターの名前をクリックします。左側のナビゲーションウィンドウで、[ワークロード] > [ステートレス] を選択します。[YAML から作成] をクリックします。次の YAML 設定を使用して、アプリケーションを MSE XXL-JOB スケジューリングプラットフォームに接続します。パラメーター
-Dxxl.job.admin.addresses、-Dxxl.job.executor.appname、-Dxxl.job.accessToken、-Ddashscope.api.key、および-Dwebhook.urlの詳細については、「起動パラメーターの設定」をご参照ください。
ステップ 2: 起動パラメーターの設定
起動パラメーターを取得します。
MSE XXL-JOB コンソールにログインし、上部のメニューバーでリージョンを選択します。
ターゲットインスタンスをクリックします。[アプリケーション管理] ページで、ターゲットアプリケーションの [エグゼキュータ数] 列にある [アクセス] をクリックします。
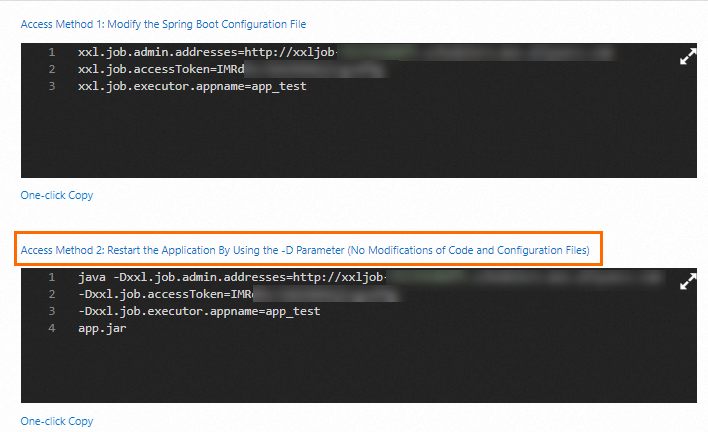
プレースホルダーをターゲットインスタンスのアクセス構成に置き換えます。次に、[コピー] をクリックしてパラメーターを YAML 設定にコピーします。
-Dxxl.job.admin.addresses=http://xxljob-xxxxx.schedulerx.mse.aliyuncs.com -Dxxl.job.executor.appname=xxxxx -Dxxl.job.accessToken=xxxxxxxAlibaba Cloud Model Studio プラットフォームにログインします。右上のプロファイルアイコンをクリックし、[API-KEY] を選択して管理ページに移動します。このページで、API-KEY を作成またはコピーできます。
プレースホルダーを API-KEY に置き換えて、パラメーターを YAML 設定にコピーします。
-Ddashscope.api.key=sk-xxxDingTalk グループの Webhook URL を取得するには、DingTalk グループ設定でカスタムロボットを追加します。
access_tokenの値を置き換えて、パラメーターを YAML 設定にコピーします。-Dwebhook.url=https://oapi.dingtalk.com/robot/send?access_token=xx
ステップ 3: AI タスクの作成と実行
MSE XXL-JOB コンソール
MSE XXL-JOB コンソールにログインし、上部のメニューバーでリージョンを選択します。ターゲットインスタンスをクリックします。左側のナビゲーションウィンドウで [タスク管理] をクリックし、次に [タスクの作成] をクリックします。
[タスクの作成] パネルで、[JobHandler 名] を
sinaNewsに設定します。次のprompt情報で [タスクパラメーター] を設定します。他のパラメーターはデフォルト設定のままにして、設定を保存します。[タスク管理] ページで、作成した
sinaNewsタスクを見つけます。[アクション] 列で、[1 回実行] をクリックします。タスクが正常に実行されるのを待ちます。その後、DingTalk グループは AI が分析したニュースサマリーを定期的に受信します。
セルフホスト型 XXL-JOB Admin
セルフホスト型 XXL-JOB Admin コンソールで、タスクを作成します。[JobHandler] を
sinaNewsに設定します。タスクパラメーターについては、「タスクパラメーターの設定例」をご参照ください。タスク管理ページで、タスクを手動で 1 回実行します。次の図に示すように、DingTalk 通知を受信します。
金融データ分析の実行
「ホットニュースのプッシュ」の例では、新浪財経 (Sina Finance) からのみニュースをプルします。しかし、国内外の金融ニュースとデータをほぼリアルタイムでプルして迅速な意思決定を行うには、単一マシンタスクでは速度が不十分です。この問題に対処するために、MSE XXL-JOB のシャーディングブロードキャストタスクを使用して、大規模なタスクを異なるデータをプルする小さなタスクに分割できます。次に、MSE XXL-JOB のタスクオーケストレーション機能を使用して、タスクを段階的に完了するためのフローを作成できます。
MSE XXL-JOB で 3 つのタスクを作成し、それらの依存関係を確立します:金融データのプル → データ分析 → レポートの生成。[金融データのプル] タスクのルーティングポリシーをブロードキャストシャーディングに設定します。
[金融データのプル] タスクが開始されると、ブロードキャストシャーディングは複数のサブタスクを異なるエグゼキュータにディスパッチして、国内外の金融ニュースとデータをプルします。結果は、データベース、Redis、または Object Storage Service (OSS) などの場所に保存されます。
[データ分析] タスクが開始されると、収集された金融データを取得します。タスクは次に DeepSeek を呼び出してデータを分析し、結果を保存します。
データ分析が完了すると、[レポートの生成] タスクは分析結果からレポートを生成します。タスクは次に、投資アドバイスを含むレポートを DingTalk または電子メールを介してユーザーに送信します。