このトピックでは、Milvus 2.5 を使用して、高速な全文検索、キーワード一致、ハイブリッド検索を実行する方法について説明します。このバージョンでは、検索精度が向上し、ベクトル類似検索とデータ分析の柔軟性が高まります。また、検索拡張生成 (RAG) アプリケーションの取得段階でハイブリッド検索を使用して、より正確なコンテキストを生成し、回答を生成する方法も示します。
背景情報
Milvus 2.5 では、パフォーマンス専有型の検索エンジンライブラリである Tantivy を統合し、組み込みの sparse-bm25 アルゴリズムを含めることで、初めてネイティブの全文検索機能を提供します。この機能は、既存のセマンティック検索機能を完全に補完し、より強力な検索体験を提供します。
組み込みトークナイザー:Milvus はテキスト入力を直接受け付け、組み込みのトークナイザーを使用して疎ベクトルを抽出します。このプロセスでは、追加の前処理を必要とせずに、テキストのトークン化、ストップワードのフィルタリング、疎ベクトルの抽出が自動的に行われます。
リアルタイムの BM25 統計:データが挿入されると、単語出現頻度 (TF) と逆文書頻度 (IDF) が動的に更新されます。これにより、検索結果のリアルタイム性と精度が保証されます。
強化されたハイブリッド検索パフォーマンス:近似最近傍 (ANN) アルゴリズムに基づく疎ベクトル取得は、従来のキーワードシステムをはるかに上回るパフォーマンスを発揮します。数億件のデータエントリに対してミリ秒レベルの応答をサポートし、密ベクトルを含むハイブリッドクエリとの互換性もあります。
前提条件
Kernel Versionが 2.5 以降の Milvus インスタンスを作成します。詳細については、「Milvus インスタンスを作成する」をご参照ください。
サービスを有効化し、API キーを取得します。
制限事項
この機能は、Kernel Versionが 2.5 以降の Milvus インスタンスに適用されます。
このガイドは、
pymilvusバージョン 2.5 以降の Python SDK に適用されます。次のコマンドを実行して、現在インストールされているバージョンを確認できます。
pip3 show pymilvusバージョンが 2.5 より前の場合は、次のコマンドを使用して更新してください。
pip3 install --upgrade pymilvus
操作手順
ステップ 1:依存ライブラリのインストール
pip3 install pymilvus langchain dashscopeステップ 2:データ準備
このトピックでは、公式の Milvus ドキュメントを例として使用します。テキストは LangChain SDK を使用してチャンク化され、text-embedding-v2 埋め込みモデルの入力として使用されます。その後、埋め込み結果と元のテキストが Milvus に挿入されます。
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from pymilvus import MilvusClient, DataType, Function, FunctionType
dashscope_api_key = "<YOUR_DASHSCOPE_API_KEY>"
milvus_url = "<YOUR_MMILVUS_URL>"
user_name = "root"
password = "<YOUR_PASSWORD>"
collection_name = "milvus_overview"
dense_dim = 1536
loader = WebBaseLoader([
'https://raw.githubusercontent.com/milvus-io/milvus-docs/refs/heads/v2.5.x/site/en/about/overview.md'
])
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=256)
# Use LangChain to chunk the input document by chunk_size
all_splits = text_splitter.split_documents(docs)
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", dashscope_api_key=dashscope_api_key
)
text_contents = [doc.page_content for doc in all_splits]
vectors = embeddings.embed_documents(text_contents)
client = MilvusClient(
uri=f"http://{milvus_url}:19530",
token=f"{user_name}:{password}",
)
schema = MilvusClient.create_schema(
enable_dynamic_field=True,
)
analyzer_params = {
"type": "english"
}
# Add fields to schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535, enable_analyzer=True, analyzer_params=analyzer_params, enable_match=True)
schema.add_field(field_name="sparse_bm25", datatype=DataType.SPARSE_FLOAT_VECTOR)
schema.add_field(field_name="dense", datatype=DataType.FLOAT_VECTOR, dim=dense_dim)
bm25_function = Function(
name="bm25",
function_type=FunctionType.BM25,
input_field_names=["text"],
output_field_names="sparse_bm25",
)
schema.add_function(bm25_function)
index_params = client.prepare_index_params()
# Add indexes
index_params.add_index(
field_name="dense",
index_name="dense_index",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128},
)
index_params.add_index(
field_name="sparse_bm25",
index_name="sparse_bm25_index",
index_type="SPARSE_WAND",
metric_type="BM25"
)
# Create collection
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
data = [
{"dense": vectors[idx], "text": doc}
for idx, doc in enumerate(text_contents)
]
# Insert data
res = client.insert(
collection_name=collection_name,
data=data
)
print(f"Generated {len(vectors)} vectors, dimension: {len(vectors[0])}")
この例では、次のパラメーターを使用します。実際の値に置き換えてください。
パラメーター | 説明 |
| Alibaba Cloud Model Studio の API キー。 |
| Milvus インスタンスの Internal IP Address または Public IP Address。Milvus インスタンスの Details ページで確認できます。
|
| Milvus インスタンスの作成時に指定したユーザー名とパスワード。 |
| |
| コレクションの名前。この名前はカスタマイズできます。このトピックでは、例として milvus_overview を使用します。 |
| 密ベクトルのディメンション。text-embedding-v2 モデルは 1536 ディメンションのベクトルを生成するため、dense_dim を 1536 に設定します。 |
この例では、Milvus 2.5 の最新機能を使用します。`bm25_function` オブジェクトを作成することで、Milvus はテキスト列を自動的に疎ベクトルに変換します。
同様に、中国語のドキュメントを処理する場合、Milvus 2.5 では対応する中国語アナライザーを指定できます。
スキーマでアナライザーを設定すると、その設定はコレクションに対して永続的になります。新しいアナライザーを設定するには、新しいコレクションを作成する必要があります。
# Define tokenizer parameters
analyzer_params = {
"type": "chinese" # Specify the tokenizer type as chinese
}
# Add a text field to the schema and enable the tokenizer
schema.add_field(
field_name="text", # Field name
datatype=DataType.VARCHAR, # Data type: string (VARCHAR)
max_length=65535, # Maximum length: 65535 characters
enable_analyzer=True, # Enable the tokenizer
analyzer_params=analyzer_params # Tokenizer parameters
)
ステップ 3:全文検索の実行
Milvus 2.5 では、API を通じて最新の全文検索機能を簡単に使用できます。以下のコードはその例です。
from pymilvus import MilvusClient
# Create a Milvus client.
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530", # The public network address of the Milvus instance.
token="<yourUsername>:<yourPassword>", # The username and password to log on to the Milvus instance.
db_name="default" # The name of the database to connect to. This example uses the default database.
)
search_params = {
'params': {'drop_ratio_search': 0.2},
}
full_text_search_res = client.search(
collection_name='milvus_overview',
data=['what makes milvus so fast?'],
anns_field='sparse_bm25',
limit=3,
search_params=search_params,
output_fields=["text"],
)
for hits in full_text_search_res:
for hit in hits:
print(hit)
print("\n")
"""
{'id': 456165042536597485, 'distance': 6.128782272338867, 'entity': {'text': '## What Makes Milvus so Fast?\n\nMilvus was designed from day one to be a highly efficient vector database system. In most cases, Milvus outperforms other vector databases by 2-5x (see the VectorDBBench results). This high performance is the result of several key design decisions:\n\n**Hardware-aware Optimization**: To accommodate Milvus in various hardware environments, we have optimized its performance specifically for many hardware architectures and platforms, including AVX512, SIMD, GPUs, and NVMe SSD.\n\n**Advanced Search Algorithms**: Milvus supports a wide range of in-memory and on-disk indexing/search algorithms, including IVF, HNSW, DiskANN, and more, all of which have been deeply optimized. Compared to popular implementations like FAISS and HNSWLib, Milvus delivers 30%-70% better performance.'}}
{'id': 456165042536597487, 'distance': 4.760214805603027, 'entity': {'text': "## What Makes Milvus so Scalable\n\nIn 2022, Milvus supported billion-scale vectors, and in 2023, it scaled up to tens of billions with consistent stability, powering large-scale scenarios for over 300 major enterprises, including Salesforce, PayPal, Shopee, Airbnb, eBay, NVIDIA, IBM, AT&T, LINE, ROBLOX, Inflection, etc.\n\nMilvus's cloud-native and highly decoupled system architecture ensures that the system can continuously expand as data grows:\n\n"}}
"""ステップ 4:キーワード一致
キーワード一致は Milvus 2.5 の新機能です。ベクトル類似検索と組み合わせることで、検索範囲を絞り込み、検索パフォーマンスを向上させることができます。キーワード一致機能を使用するには、スキーマを定義する際に enable_analyzer と enable_match の両方を True に設定します。
enable_match を有効にすると、フィールドに対して転置インデックスが作成され、追加のストレージリソースが消費されます。
例 1:キーワード一致とベクトル検索の組み合わせ
このコードスニペットでは、フィルター式を使用して、検索結果を「query」と「node」という単語に一致するドキュメントに限定します。その後、フィルタリングされたドキュメントのサブセットに対してベクトル類似検索が実行されます。
filter = "TEXT_MATCH(text, 'query') and TEXT_MATCH(text, 'node')"
text_match_res = client.search(
collection_name="milvus_overview",
anns_field="dense",
data=query_embeddings,
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=2,
output_fields=["text"]
)例 2:スカラーフィルタリングクエリ
キーワード一致は、クエリ操作におけるスカラーフィルタリングにも使用できます。query() で TEXT_MATCH 式を指定して、指定された単語に一致するドキュメントを取得できます。このコードスニペットでは、フィルター式によって検索結果が「scalable」または「fast」に一致するドキュメントに限定されます。
filter = "TEXT_MATCH(text, 'scalable fast')"
text_match_res = client.query(
collection_name="milvus_overview",
filter=filter,
output_fields=["text"]
)ステップ 5:ハイブリッド検索と RAG
ベクトル検索と全文検索を組み合わせることができます。逆順位融合 (RRF) アルゴリズムを使用して、両方の検索結果をマージします。このプロセスでは、ソートと重み付けが再最適化され、取得率と精度が向上します。
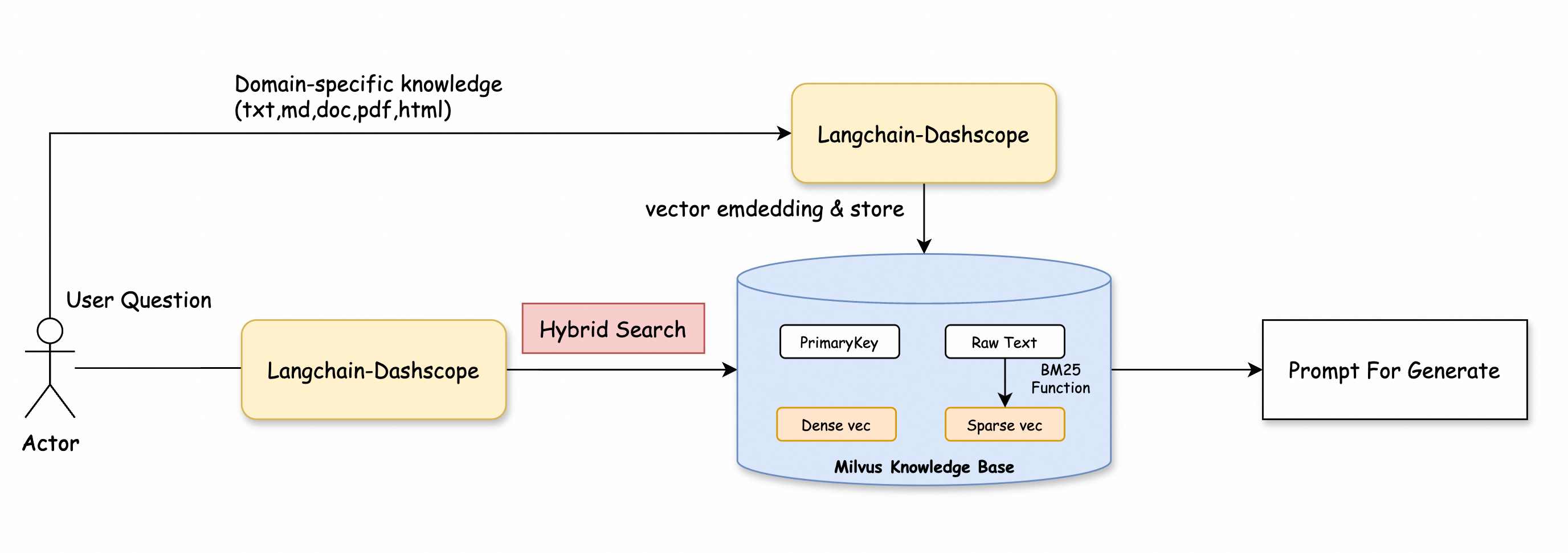
以下のコードはその例です。
from pymilvus import MilvusClient
from pymilvus import AnnSearchRequest, RRFRanker
from langchain_community.embeddings import DashScopeEmbeddings
from dashscope import Generation
# Create a Milvus client.
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530", # The public network address of the Milvus instance.
token="<yourUsername>:<yourPassword>", # The username and password to log on to the Milvus instance.
db_name="default" # The name of the database to connect to. This example uses the default database.
)
collection_name = "milvus_overview"
# Replace with your DashScope API key
dashscope_api_key = "<YOUR_DASHSCOPE_API_KEY>"
# Initialize the embedding model
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # Use the text-embedding-v2 model.
dashscope_api_key=dashscope_api_key
)
# Define the query
query = "Why does Milvus run so scalable?"
# Embed the query and generate the corresponding vector representation
query_embeddings = embeddings.embed_documents([query])
# Set the top K result count
top_k = 5 # Get the top 5 docs related to the query
# Define the parameters for the dense vector search
search_params_dense = {
"metric_type": "IP",
"params": {"nprobe": 2}
}
# Create a dense vector search request
request_dense = AnnSearchRequest([query_embeddings[0]], "dense", search_params_dense, limit=top_k)
# Define the parameters for the BM25 text search
search_params_bm25 = {
"metric_type": "BM25"
}
# Create a BM25 text search request
request_bm25 = AnnSearchRequest([query], "sparse_bm25", search_params_bm25, limit=top_k)
# Combine the two requests
reqs = [request_dense, request_bm25]
# Initialize the RRF ranking algorithm
ranker = RRFRanker(100)
# Perform the hybrid search
hybrid_search_res = client.hybrid_search(
collection_name=collection_name,
reqs=reqs,
ranker=ranker,
limit=top_k,
output_fields=["text"]
)
# Extract the context from hybrid search results
context = []
print("Top K Results:")
for hits in hybrid_search_res: # Use the correct variable here
for hit in hits:
context.append(hit['entity']['text']) # Extract text content to the context list
print(hit['entity']['text']) # Output each retrieved document
# Define a function to get an answer based on the query and context
def getAnswer(query, context):
prompt = f'''Please answer my question based on the content within:
```
{context}
```
My question is: {query}.
'''
# Call the generation module to get an answer
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text
# Get the answer
answer = getAnswer(query, context)
print(answer)
# Expected output excerpt
"""
Milvus is highly scalable due to its cloud-native and highly decoupled system architecture. This architecture allows the system to continuously expand as data grows. Additionally, Milvus supports three deployment modes that cover a wide...
"""