MaxCompute Spark は、Jindo software development kit (SDK) を介して Alibaba Cloud Object Storage Service (OSS) にアクセスします。Jindo SDK は、Hadoop および Spark エコシステム向けに設計された、パフォーマンス専有型の OSS クライアントです。Alibaba Cloud OSS に高度に最適化された Hadoop FileSystem の実装を提供します。
ステップ 1:OSS 実装クラスとエンドポイントの設定
ローカルモードでは、対応するリージョンのパブリックエンドポイントを使用します。クラスターモードでは、内部エンドポイントを使用します。詳細については、「リージョンとエンドポイント」をご参照ください。
Spark 3.5+ (デフォルトで JindoSDK 6.5 を統合)。次の設定を追加します。
spark.hadoop.fs.AbstractFileSystem.oss.impl=com.aliyun.jindodata.oss.JindoOSS spark.hadoop.fs.oss.impl=com.aliyun.jindodata.oss.JindoOssFileSystem spark.hadoop.fs.oss.endpoint=oss-${RegionId}-internal.aliyuncs.comその他のバージョン (JindoSDK 3.7 を使用する場合)。次の設定を追加します。
spark.hadoop.fs.AbstractFileSystem.oss.impl=com.aliyun.emr.fs.oss.OSS spark.hadoop.fs.oss.impl=com.aliyun.emr.fs.oss.JindoOssFileSystem spark.hadoop.fs.oss.endpoint=oss-${RegionId}-internal.aliyuncs.com
ステップ 2:認証情報の設定
以下の 2 つの認証方式のいずれかを選択します。
方法 1:AccessKey ID と AccessKey Secret の使用
次の設定項目を spark-defaults.conf ファイルまたは DataWorks の設定に追加します。
spark.hadoop.fs.oss.accessKeyId=${AccessId}
spark.hadoop.fs.oss.accessKeySecret=${AccessKey}方法 2:Security Token Service トークンの使用
詳細については、「STS モードでのアクセス承認」をご参照ください。その後、次の設定項目を追加します。
Spark 3.5+ の設定
## 次の設定項目を spark-defaults.conf ファイルまたは DataWorks の設定に追加します。
spark.hadoop.fs.oss.credentials.provider=com.aliyun.jindodata.oss.auth.CustomCredentialsProvider
spark.hadoop.aliyun.oss.provider.url=http://localhost:10011/sts-token-info?user_id=${AliyunUid}&role=${RoleName}その他のバージョンの設定
## 次の設定項目を spark-defaults.conf ファイルまたは DataWorks の設定に追加します。
spark.hadoop.odps.cupid.http.server.enable=true
spark.hadoop.fs.jfs.cache.oss.credentials.provider=com.aliyun.emr.fs.auth.CustomCredentialsProvider
spark.hadoop.aliyun.oss.provider.url=http://localhost:10011/sts-token-info?user_id=${AliyunUid}&role=${RoleName}ステップ 3:Jindo SDK 依存関係の参照 (Spark 3.5+ の場合はこのステップをスキップ)
ローカルモード
ローカルモードでは、Jindo SDK をダウンロードしてクラスパスに追加します。
[ファイル] > [プロジェクト構造] に移動します。
左側のナビゲーションウィンドウで
[モジュール]を選択します。プラス記号 (+) をクリックし、[JAR またはディレクトリ]を選択します。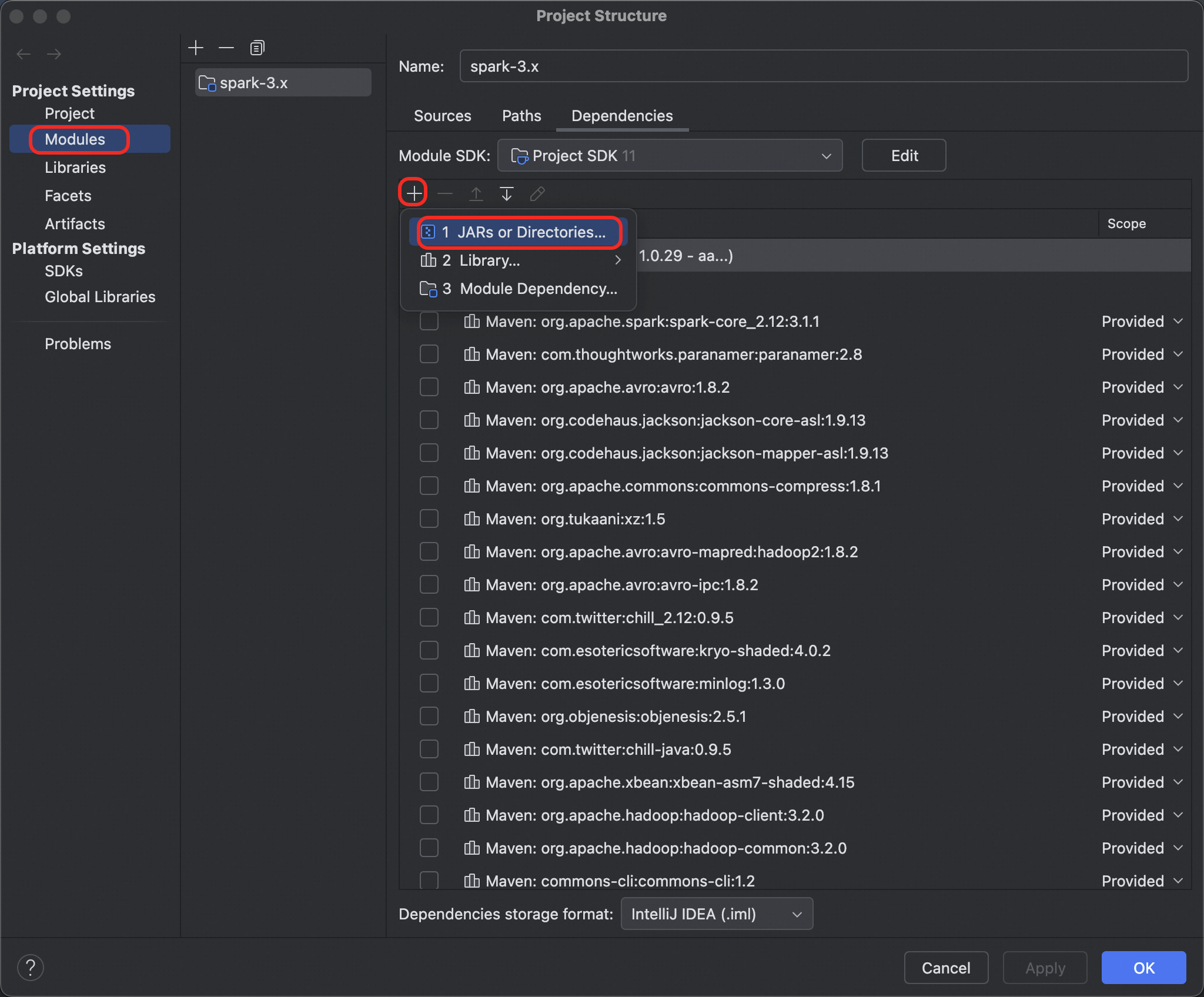
Jindo SDK の
libフォルダからすべての JAR ファイルを追加します。IDEA で [OK] をクリックします。
クラスターモード
Spark 3.5 の場合、Jindo SDK はサーバー側に含まれているため、操作は不要です。
その他のバージョンの場合は、
spark-defaults.confファイルを変更します。次の設定項目を追加して、パブリックリソースを使用します。spark.hadoop.odps.cupid.resources = public.jindofs-sdk-3.7.2.jar ## 注:異なるバージョンの Jindo SDK を使用するには、対応する SDK バージョンをダウンロードし、プロジェクトにアップロードしてから、spark.hadoop.odps.cupid.resources を使用して参照します。
ステップ 4:ネットワークホワイトリストの設定
デフォルトでは、設定なしで直接アクセスできます。
クラスターモードで OSS にアクセスできない場合は、次の設定項目を
spark-defaults.confファイルまたは DataWorks の設定に追加して、ターゲットバケットのドメイン名をジョブのホワイトリストに追加します。spark.hadoop.odps.cupid.trusted.services.access.list=${BucketName}.oss-${RegionId}-internal.aliyuncs.com
ステップ 5:ジョブの送信
./bin/spark-submit --class xxx spark-app.jar