ユーザー定義結合 (UDJ) は、MaxCompute のユーザー定義関数 (UDF) フレームワークを拡張し、2 つのテーブル間でカスタムの結合ロジックを適用できるようにします。UDJ は MaxCompute V2.0 コンピュートエンジン上で動作し、標準の JOIN 型や UDF/UDTF/UDAF フレームワークでは処理できないクロステーブル操作を実現できます。また、カスタム MapReduce 実装に頼ることなく、これらの操作を実行可能です。
UDJ を使用するタイミング
MaxCompute には、INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN、SEMI JOIN、ANTI-SEMI JOIN の 6 種類の組み込み 結合 型が用意されています。既存の UDF、ユーザー定義テーブル関数 (UDTF)、ユーザー定義集計関数 (UDAF) フレームワークは、いずれも単一テーブルに対してのみ動作します。
カスタムロジックによる複数テーブルの結合を行う場合、現在は以下の 2 つの選択肢がありますが、どちらにも重大な課題があります:
複雑な SQL を用いた組み込み JOIN:単一の SQL ステートメント内で複数の JOIN 型と UDF を組み合わせると、論理ブラックボックスが形成され、最適な実行計画を生成することが困難になります。
カスタム MapReduce:実行計画の最適化が困難です。ほとんどの MapReduce コードは Java で記述され、Low Level Virtual Machine (LLVM) コードジェネレータによって生成される MaxCompute ネイティブコードと比較して、実行効率が劣ります。
UDJ は、上記の両方の制限に対応しています。結合ロジックは MaxCompute のネイティブランタイム内で実行され、UDJ ランタイムエンジンと Java コード間のデータ交換も最適化されています。このため、UDJ の結合ロジックは同等の MapReduce リデューサーと比較してより効率的です。
UDJ を使用すると、以下のような操作が可能です:
2 つのテーブルからグループ化されたレコードに対してカスタムのマージロジックを適用する
空の左グループや空の右グループといった非対称ケースを明示的に処理する
SORT BYを用いた事前ソートにより、すべてのレコードをメモリに読み込まずに大規模なグループを効率的に処理するSQL から呼び出せる Java コードで、複雑な MapReduce リデューサーロジックを置き換える
制限事項
以下のタイプのテーブルからデータを読み取る場合、UDF、UDAF、UDTF を使用できません:
スキーマ進化が適用されたテーブル
複雑なデータの型を含むテーブル
JSON データの型を含むテーブル
トランザクショナルテーブル
パフォーマンス
UDJ のパフォーマンス検証のため、実際の MapReduce ジョブで実行されていた複雑なアルゴリズムを UDJ で再実装しました。両手法は同一のデータセットおよび同一の同時実行数で実行されました。下図に結果を示します。
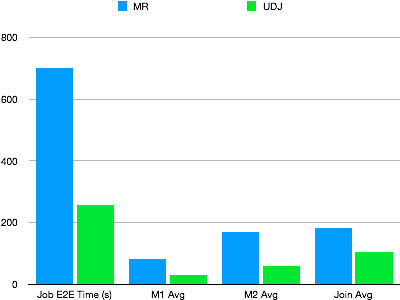
UDJ は MapReduce 版を大幅に上回るパフォーマンスを発揮します。全マッパー処理は MaxCompute のネイティブランタイムで実行されます。また、MaxCompute UDJ ランタイムエンジンと Java インターフェイス間のデータ交換ロジックは Java コード内で最適化されています。その結果、結合ロジックは同等のリデューサーと比較してより効率的です。
UDJ の実装:クロステーブル結合の例
本セクションでは、クライアント活動ログ内の各レコードについて、最も近いタイムスタンプを持つ支払いレコードを検索し、両者をマージするという完全な例を説明します。
サンプルテーブル
payment — ユーザーの支払いレコードを格納
| user_id | time | pay_info |
|---|---|---|
| 2656199 | 2018-02-13 22:30:00 | gZhvdySOQb |
| 8881237 | 2018-02-13 08:30:00 | pYvotuLDIT |
| 8881237 | 2018-02-13 10:32:00 | KBuMzRpsko |
user_client_log — クライアントの活動ログを格納
| user_id | time | content |
|---|---|---|
| 8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn |
| 8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL |
| 8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL |
目的:各 user_client_log レコードについて、同一の user_id を持つ payment レコードのうち、time 値が最も近いものを検索し、両レコードをマージします。
標準の JOIN ではこれを実現できません。条件式 ABS(p.time - u.time) = MIN(ABS(p.time - u.time)) は、JOIN 述語内に集計関数を含む必要があり、これは SQL では許可されていません。
ステップ 1:SDK の設定
Maven プロジェクトに UDF SDK を追加します:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-udf</artifactId>
<version>0.29.10-public</version>
<scope>provided</scope>
</dependency>ステップ 2:UDJ クラスの作成
UDJ クラスは、以下の 3 つのライフサイクルメソッドを実装します:
setup()— 処理開始前に 1 回呼び出されます。出力スキーマおよび共有状態の初期化を行います。join()— 結合キーごとに 1 回呼び出されます。左側および右側のレコードグループに対するイテレーターを受信します。close()— 全グループの処理完了後に呼び出されます。ここでリソースを解放します。
以下の例では、最も近い時刻のマッチングを実装しています。user_id ごとのすべての支払いレコードを ArrayList に読み込むことで、右側のイテレーターが各ログレコードをすべての支払いレコードと比較できるようになります。
package com.aliyun.odps.udf.example.udj;
import com.aliyun.odps.Column;
import com.aliyun.odps.OdpsType;
import com.aliyun.odps.Yieldable;
import com.aliyun.odps.data.ArrayRecord;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.udf.DataAttributes;
import com.aliyun.odps.udf.ExecutionContext;
import com.aliyun.odps.udf.UDJ;
import com.aliyun.odps.udf.annotation.Resolve;
import java.util.ArrayList;
import java.util.Iterator;
// 出力スキーマ: (user_id STRING, time BIGINT, content STRING)
@Resolve("->string,bigint,string")
public class PayUserLogMergeJoin extends UDJ {
private Record outputRecord;
// 処理開始前に出力レコードスキーマを初期化します。
@Override
public void setup(ExecutionContext executionContext, DataAttributes dataAttributes) {
outputRecord = new ArrayRecord(new Column[]{
new Column("user_id", OdpsType.STRING),
new Column("time", OdpsType.BIGINT),
new Column("content", OdpsType.STRING)
});
}
// 結合キー (user_id) ごとに 1 回呼び出されます。
// left = この user_id の支払いレコード
// right = この user_id のログレコード
@Override
public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) {
outputRecord.setString(0, key.getString(0));
if (!right.hasNext()) {
// このユーザーに対するログレコードが存在しない場合は、出力しません。
return;
} else if (!left.hasNext()) {
// 支払いレコードが存在しない場合は、マージせずにログレコードを出力します。
while (right.hasNext()) {
Record logRecord = right.next();
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
outputRecord.setString(2, logRecord.getString(1));
output.yield(outputRecord);
}
return;
}
// 各ログレコードを全支払いレコードと比較できるよう、
// すべての支払いレコードをメモリに読み込みます。
ArrayList<Record> pays = new ArrayList<>();
left.forEachRemaining(pay -> pays.add(pay.clone()));
while (right.hasNext()) {
Record log = right.next();
long logTime = log.getDatetime(0).getTime();
long minDelta = Long.MAX_VALUE;
Record nearestPay = null;
// 時間差が最小となる支払いレコードを検索します。
for (Record pay : pays) {
long delta = Math.abs(logTime - pay.getDatetime(0).getTime());
if (delta < minDelta) {
minDelta = delta;
nearestPay = pay;
}
}
// ログレコードと最も近い支払いレコードをマージします。
outputRecord.setBigint(1, log.getDatetime(0).getTime());
outputRecord.setString(2, mergeLog(nearestPay.getString(1), log.getString(1)));
output.yield(outputRecord);
}
}
String mergeLog(String payInfo, String logContent) {
return logContent + ", pay " + payInfo;
}
@Override
public void close() {}
}このクラスを odps-udj-example.jar としてパッケージ化します。
ステップ 3:UDJ 関数の登録
JAR ファイルをアップロードし、関数を登録します:
ADD jar odps-udj-example.jar;
CREATE FUNCTION pay_user_log_merge_join
AS 'com.aliyun.odps.udf.example.udj.PayUserLogMergeJoin'
USING 'odps-udj-example.jar';ステップ 4:サンプルデータの準備
CREATE TABLE payment(user_id STRING, time DATETIME, pay_info STRING);
CREATE TABLE user_client_log(user_id STRING, time DATETIME, content STRING);
-- 支払いレコードの挿入
INSERT OVERWRITE TABLE payment VALUES
('1335656', datetime '2018-02-13 19:54:00', 'PEqMSHyktn'),
('2656199', datetime '2018-02-13 12:21:00', 'pYvotuLDIT'),
('2656199', datetime '2018-02-13 20:50:00', 'PEqMSHyktn'),
('2656199', datetime '2018-02-13 22:30:00', 'gZhvdySOQb'),
('8881237', datetime '2018-02-13 08:30:00', 'pYvotuLDIT'),
('8881237', datetime '2018-02-13 10:32:00', 'KBuMzRpsko'),
('9890100', datetime '2018-02-13 16:01:00', 'gZhvdySOQb'),
('9890100', datetime '2018-02-13 16:26:00', 'MxONdLckwa');
-- ログレコードの挿入
INSERT OVERWRITE TABLE user_client_log VALUES
('1000235', datetime '2018-02-13 00:25:36', 'click FNOXAibRjkIaQPB'),
('1000235', datetime '2018-02-13 22:30:00', 'click GczrYaxvkiPultZ'),
('1335656', datetime '2018-02-13 18:30:00', 'click MxONdLckpAFUHRS'),
('1335656', datetime '2018-02-13 19:54:00', 'click mKRPGOciFDyzTgM'),
('2656199', datetime '2018-02-13 08:30:00', 'click CZwafHsbJOPNitL'),
('2656199', datetime '2018-02-13 09:14:00', 'click nYHJqIpjevkKToy'),
('2656199', datetime '2018-02-13 21:05:00', 'click gbAfPCwrGXvEjpI'),
('2656199', datetime '2018-02-13 21:08:00', 'click dhpZyWMuGjBOTJP'),
('2656199', datetime '2018-02-13 22:29:00', 'click bAsxnUdDhvfqaBr'),
('2656199', datetime '2018-02-13 22:30:00', 'click XIhZdLaOocQRmrY'),
('4356142', datetime '2018-02-13 18:30:00', 'click DYqShmGbIoWKier'),
('4356142', datetime '2018-02-13 19:54:00', 'click DYqShmGbIoWKier'),
('8881237', datetime '2018-02-13 00:30:00', 'click MpkvilgWSmhUuPn'),
('8881237', datetime '2018-02-13 06:14:00', 'click OkTYNUHMqZzlDyL'),
('8881237', datetime '2018-02-13 10:30:00', 'click OkTYNUHMqZzlDyL'),
('9890100', datetime '2018-02-13 16:01:00', 'click vOTQfBFjcgXisYU'),
('9890100', datetime '2018-02-13 16:20:00', 'click WxaLgOCcVEvhiFJ');ステップ 5:SQL での UDJ の実行
USING 句は、UDJ 関数を識別し、各テーブルから列をマップします:
SELECT r.user_id, FROM_UNIXTIME(time/1000) AS time, content
FROM (
SELECT user_id, time AS time, pay_info FROM payment
) p
JOIN (
SELECT user_id, time AS time, content FROM user_client_log
) u
ON p.user_id = u.user_id
USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content)
r
AS (user_id, time, content);USING 句のパラメーター:
| パラメーター | 説明 |
|---|---|
pay_user_log_merge_join | 登録済みの UDJ 関数の名前 |
(p.time, p.pay_info, u.time, u.content) | UDJ に渡される左テーブルおよび右テーブルの列 |
r | UDJ 結果セットのエイリアス。外部クエリで参照可能 |
(user_id, time, content) | UDJ 出力の列名 |
期待される出力:
+---------+---------------------+-----------------------------------------------+
| user_id | time | content |
+---------+---------------------+-----------------------------------------------+
| 1000235 | 2018-02-13 00:25:36 | click FNOXAibRjkIaQPB |
| 1000235 | 2018-02-13 22:30:00 | click GczrYaxvkiPultZ |
| 1335656 | 2018-02-13 18:30:00 | click MxONdLckpAFUHRS, pay PEqMSHyktn |
| 1335656 | 2018-02-13 19:54:00 | click mKRPGOciFDyzTgM, pay PEqMSHyktn |
| 2656199 | 2018-02-13 08:30:00 | click CZwafHsbJOPNitL, pay pYvotuLDIT |
| 2656199 | 2018-02-13 09:14:00 | click nYHJqIpjevkKToy, pay pYvotuLDIT |
| 2656199 | 2018-02-13 21:05:00 | click gbAfPCwrGXvEjpI, pay PEqMSHyktn |
| 2656199 | 2018-02-13 21:08:00 | click dhpZyWMuGjBOTJP, pay PEqMSHyktn |
| 2656199 | 2018-02-13 22:29:00 | click bAsxnUdDhvfqaBr, pay gZhvdySOQb |
| 2656199 | 2018-02-13 22:30:00 | click XIhZdLaOocQRmrY, pay gZhvdySOQb |
| 4356142 | 2018-02-13 18:30:00 | click DYqShmGbIoWKier |
| 4356142 | 2018-02-13 19:54:00 | click DYqShmGbIoWKier |
| 8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT |
| 8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT |
| 8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko |
| 9890100 | 2018-02-13 16:01:00 | click vOTQfBFjcgXisYU, pay gZhvdySOQb |
| 9890100 | 2018-02-13 16:20:00 | click WxaLgOCcVEvhiFJ, pay MxONdLckwa |
+---------+---------------------+-----------------------------------------------+SORT BY による事前ソートでメモリ使用量を最適化
前述の実装では、各 user_id のすべての支払いレコードを ArrayList に読み込みます。これはユーザーの支払いレコード数が少ない場合には有効ですが、グループが大きすぎてメモリに収まらない場合には機能しません。
データが時間順にソートされている場合、全グループではなく、少数のレコードだけを同時に管理すれば十分です。
SQL の変更
両テーブルを各結合グループ内で時間順にソートするために、SORT BY 句を追加します:
SELECT r.user_id, from_unixtime(time/1000) AS time, content
FROM (
SELECT user_id, time AS time, pay_info FROM payment
) p
JOIN (
SELECT user_id, time AS time, content FROM user_client_log
) u
ON p.user_id = u.user_id
USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content)
r
AS (user_id, time, content)
SORT BY p.time, u.time;更新された join() メソッド
両側が時間順にソートされている場合、単一の線形スキャンで最も近い支払いレコードを検索できます。各右側レコードに対して左側グループ全体を反復処理する代わりに、最大 3 つのレコードのスライドウィンドウを比較します。このロジックを実装するために、join() メソッドを更新します:
@Override
public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) {
outputRecord.setString(0, key.getString(0));
if (!right.hasNext()) {
return;
} else if (!left.hasNext()) {
while (right.hasNext()) {
Record logRecord = right.next();
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
outputRecord.setString(2, logRecord.getString(1));
output.yield(outputRecord);
}
return;
}
long prevDelta = Long.MAX_VALUE;
Record logRecord = right.next();
Record payRecord = left.next();
Record lastPayRecord = payRecord.clone();
while (true) {
long delta = logRecord.getDatetime(0).getTime() - payRecord.getDatetime(0).getTime();
if (left.hasNext() && delta > 0) {
// 時間差がまだ縮小中であるため、左側イテレーターを進めます。
lastPayRecord = payRecord.clone();
prevDelta = delta;
payRecord = left.next();
} else {
// 最小の時間差に到達しました。マージされたレコードを出力し、右側イテレーターを進めます。
Record nearestPay = Math.abs(delta) < prevDelta ? payRecord : lastPayRecord;
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
outputRecord.setString(2, mergeLog(nearestPay.getString(1), logRecord.getString(1)));
output.yield(outputRecord);
if (right.hasNext()) {
logRecord = right.next();
prevDelta = Math.abs(
logRecord.getDatetime(0).getTime() - lastPayRecord.getDatetime(0).getTime()
);
} else {
break;
}
}
}
}このバージョンでは、同時にキャッシュされるレコードは最大 3 つであり、ArrayList 方式と同じ出力を生成します。
Java UDJ クラスを変更した後は、JAR ファイルを再構築し、変更を反映させるために MaxCompute に再登録してください。