2つのテーブルを Join する際にホットスポットが存在し、長尾問題が発生した場合、ホットキーを抽出し、データをホットデータと非ホットデータに分けて処理し、最後に結果をマージすることで Join の効率を向上させることができます。SKEWJOIN HINT は、自動または手動で 2つのテーブルのホットキーを取得し、ホットデータと非ホットデータの Join 結果をそれぞれ計算してマージすることで、Join の実行速度を向上させます。
使用方法
SKEWJOIN HINT を実行するには、select 文でヒント /*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/ を使用する必要があります。table_name は傾斜テーブル名、column_name は傾斜列名、value は傾斜キー値を表します。
--方法1:テーブル名をヒントとして指定します (ヒントの対象はテーブルのエイリアスであることに注意してください)。
select /*+ skewjoin(a) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1;
--方法2:テーブル名と、スキューが発生する可能性のある列をヒントとして指定します。例えば、テーブル a の c0 列と c1 列でデータスキューが発生している場合です。
select /*+ skewjoin(a(c0, c1)) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1 and a.c2 = b.c2;
--方法3:テーブル名と列をヒントとして指定し、スキューが発生しているキー値を指定します。STRING 型の場合は、引用符で囲む必要があります。例えば、(a.c0=1 and a.c1="2") と (a.c0=3 and a.c1="4") の両方の値でデータスキューが発生している場合です。
select /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1 and a.c2 = b.c2;方法3のように値を直接指定する方が、方法1と方法2 (値を指定しない) よりも処理効率が高くなります。
仕組み
ホットキーとは、出現頻度が非常に高いキー値のことです。例えば、下の図の赤色部分では、a.c0=1 and a.c1=2 の行が 10,000 行、a.c0=3 and a.c1 = 4 の行が 9,000 行あります。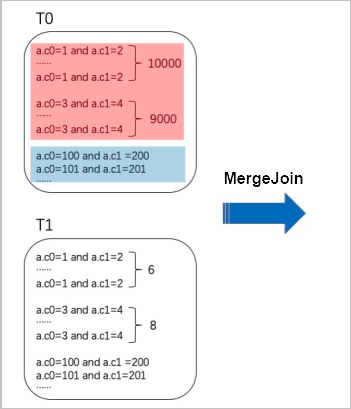
SKEWJOIN HINT を使用しない場合、テーブル T0 とテーブル T1 を Join すると、両方のテーブルのデータ量が非常に大きいため、MergeJoin しか実行できません。その結果、同じホットキーがすべて 1つのノードに Shuffle され、データスキューが発生します。SKEWJOIN HINT を使用すると、オプティマイザーは Aggregate を実行して、出現頻度が上位 20位のホットキーを動的に取得します。そして、テーブル T0 をホットキーに該当する値 (データ A) と、それ以外の値 (データ B) に分割します。同様に、テーブル T1 を T0 のホットキーと Join できる値 (データ C) と、T0 のホットキーと Join できない値 (データ D) に分割します。その後、データ A とデータ C で MapJoin を実行し (データ C は少量のため MapJoin が可能)、データ B とデータ D で MergeJoin を実行します。最後に、MapJoin と MergeJoin の結果を UNION で結合し、最終的な結果を生成します。下の図をご参照ください。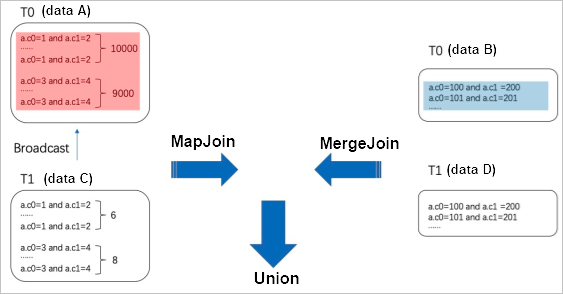
注意事項
-
SKEWJOIN HINT がサポートする Join タイプ:
-
Inner Join:Join の両側のテーブルのいずれかにヒントを指定できます。
-
Left Join、Semi Join、Anti Join:左側のテーブルにのみヒントを指定できます。
-
Right Join:右側のテーブルにのみヒントを指定できます。
-
Full Join:SKEWJOIN HINT はサポートされていません。
-
-
ヒントは Aggregate を実行するため、ある程度のコストがかかります。そのため、データスキューが確実に発生する Join にのみヒントを追加することを推奨します。また、A Join B のクエリで A に SKEWJOIN HINT を追加すると、
MapJoin union all MergeJoinのような物理実行計画が強制的に生成されます。この MapJoin サブプランは、Top 20(A) MapJoin (B Semi Join Top20(A))のように展開されます。B テーブル自体のデータ量が大きい場合、Top20(A)でフィルタリングされた後のデータ量も大きくなる可能性があり、MapJoin が HashJoin と HashTable を構築する際に OOM の問題が発生する可能性があります。 -
ヒントが指定された Join の Left Side Join Key の型は、Right Side Join Key の型と一致している必要があります。一致していない場合、SKEWJOIN HINT は有効になりません。例えば、上記の例では a.c0 と b.c0 の型、a.c1 と b.c1 の型がそれぞれ一致している必要があります。サブクエリ内で Join キーを Cast することで型を一致させることができます。以下に例を示します。
create table T0(c0 int, c1 int, c2 int, c3 int); create table T1(c0 string, c1 int, c2 int); --方法1: select /*+ skewjoin(a) */ * from T0 a join T1 b on cast(a.c0 as string) = cast(b.c0 as string) and a.c1 = b.c1; --方法2: select /*+ skewjoin(b) */ * from (select cast(a.c0 as string) as c00 from T0 a) b join T1 c on b.c00 = c.c0; -
SKEWJOIN HINT を追加すると、オプティマイザーは Aggregate を実行して上位 20件のホットキーを取得します。20 はデフォルト値であり、
set odps.optimizer.skew.join.topk.num = xx;を使用して設定できます。 -
SKEWJOIN HINT は、Join の片側にのみ指定できます。
-
ヒントが指定された Join には
left key = right keyの条件が必要です。デカルト積 Join はサポートされていません。 -
他のヒントと併用する方法は以下の通りです。ただし、MapJoin ヒントが指定された Join には、SKEWJOIN HINT を追加できない点にご注意ください。
select /*+ mapjoin(c), skewjoin(a) */ * from T0 a join T1 b on a.c0 = b.c3 join T2 c on a.c0 = c.c7; -
Logview の [Json Summary] で topk_agg フィールドが存在するかを検索することで、SKEWJOIN HINT が有効になったかどうかを判断できます。