このトピックでは、MaxCompute Spark ジョブのリソース割り当てパラメーターについて説明し、適切な設定方法およびリソース待機に関する問題のトラブルシューティング手順を提供します。
リソースパラメーターの説明
Spark ジョブを送信する際は、以下のリソースパラメーターを考慮してください。
エグゼキュータ数
エグゼキュータメモリ
エグゼキュータ CPU コア数
ドライバーメモリ
ドライバー コア
ローカルディスク
エグゼキュータ関連パラメーター
spark.executor.instances:リクエストするエグゼキュータの総数です。一般的なジョブでは、10 ~ 100 個のエグゼキュータで十分です。大規模データ処理の場合は、100 ~ 2,000 個以上をリクエストできます。
spark.executor.cores:各エグゼキュータに割り当てる CPU コア数です。このパラメーターは、1 つのエグゼキュータ内で同時に実行可能なタスクの最大数も決定します。
Spark の最大並列度 = エグゼキュータ数 × エグゼキュータ CPU コア数
spark.executor.memory:各エグゼキュータのヒープメモリです。この値は、JVM プロセス起動時に JVM の
-Xmxパラメーターとして設定されます。spark.executor.memoryOverhead:各エグゼキュータのヒープ外メモリです。デフォルトの単位は MB です。このメモリは、JVM オーバーヘッド、文字列、NIO バッファー、その他のネイティブメモリ用途に使用されます。
デフォルト値は
executor.memory × 0.1で、最小値は 384 MB です。Cannot allocate memoryエラーが発生した場合は、spark.executor.memoryOverheadの値を増やしてください。各エグゼキュータの合計メモリは、spark.executor.memory+spark.executor.memoryOverheadで計算されます。
ドライバー関連パラメーター
spark.driver.cores:ドライバーの CPU コア数です。spark.driver.memory:ドライバーのヒープメモリです。spark.driver.memoryOverhead:ドライバーのヒープ外メモリです。spark.driver.maxResultSize:デフォルト値は 1 GB です。このパラメーターは、ワーカーからドライバーに送信できるデータの最大サイズを制御します。この制限を超えると、ドライバーは実行を停止します。
ローカルディスクパラメーター
spark.hadoop.odps.cupid.disk.driver.device_size:ローカルディスクのサイズです。デフォルト値は 20 GB です。
spark-defaults.confファイルまたは DataWorks の設定項目でこのパラメーターを設定できます。コード内での設定は避けてください。Spark は一時ストレージとしてローカルディスクを使用します。各ドライバーおよびエグゼキュータには専用のローカルディスクが割り当てられます。Shuffle データおよび BlockManager のオーバーフロー データはこれらのディスク上に保存されます。
No space left on deviceエラーが発生した場合は、この値を増やしてください。サポートされる最大サイズは 100 GB です。100 GB に設定してもエラーが解消しない場合は、以下の原因を調査してください。データスキュー:Shuffle またはキャッシュ処理中にデータが少数のブロックに集中している。
spark.executor.coresの値を下げて、各エグゼキュータの同時タスク数を減らす。spark.executor.instancesを使用してエグゼキュータの総数を増やす。
リソースパラメーターの適切な設定方法
メモリ対 CPU の比率を 4 GB : 1 コアでリソースをリクエストしてください。各ワーカーに割り当てる CPU コア数は最大 8 コアまでにすることを推奨します。
LogView の Master または Worker の Sensor メトリックを使用して、ランタイム時のメモリおよび CPU 使用量を確認できます。
mem_rssメトリックを監視してください。このメトリックは、エグゼキュータまたはドライバーの実際のメモリ使用量の曲線を示します。このメトリックを基に、割り当てメモリを増減すべきか判断できます。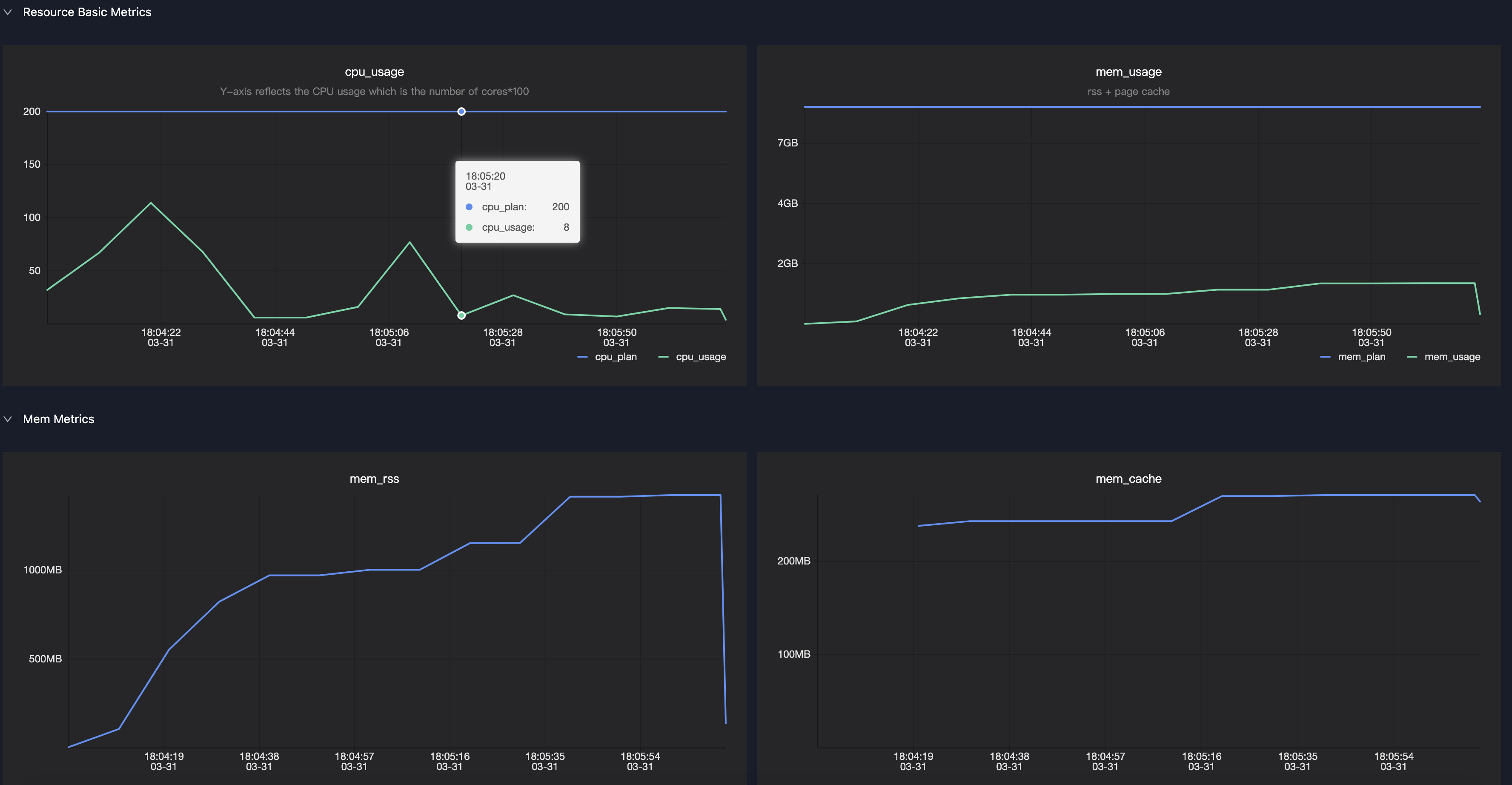
リソース待機の問題
コード内で spark.master を設定しないでください。ローカルモードでのデバッグ後は、コードから spark.master=local の設定を削除してください。
リソース割り当て後のジョブ送信
リソース割り当ては動的プロセスであり、リクエストしたよりも少ないリソースしか割り当てられない場合があります。デフォルトでは、Spark はすべてのエグゼキュータが準備完了になるのを待たずにタスクの実行を開始します。以下のパラメーターを使用して、Spark がタスクを送信するタイミングを制御できます。
spark.scheduler.maxRegisteredResourcesWaitingTime:実行開始前にリソースを待機する最大時間です。デフォルト値は 30 秒です。spark.scheduler.minRegisteredResourcesRatio:リクエストされたリソースに対する登録済みリソースの最小比率です。デフォルト値は 0.8 です。
リソース割り当て失敗の主な原因
サブスクリプションユーザーの場合、通常、サブスクリプションに含まれるリソース数を超えてリソースをリクエストしています。
従量課金ユーザーの場合、リソースが過剰に利用されており、他のユーザーと競合している可能性があります。
リソース割り当て失敗への対処法
ジョブリソースを調整します。エグゼキュータの総数、または各エグゼキュータに割り当てるリソース(通常はメモリ)を変更できます。
混雑していない時間帯にジョブをスケジュールします。
リソース未割り当ての典型的な兆候
ドライバーが以下のログを出力します。
WARN YarnClusterScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resourcesLogView にドライバーのみ表示され、ワーカー数が 0 です。
Spark UI にドライバーのみ表示され、ワーカー数が 0 です。