このトピックでは、Proxima カーネルのモジュールを使用する方法と、各モジュールの パラメーター を構成する方法について説明します。モジュールは IndexBuilder、IndexConverter、IndexMeasure、および IndexSearcher です。
IndexBuilder
IndexBuilder は、インデックスを構築するために使用されます。次の図は、このモジュールを呼び出す基本的なプロセスを示しています。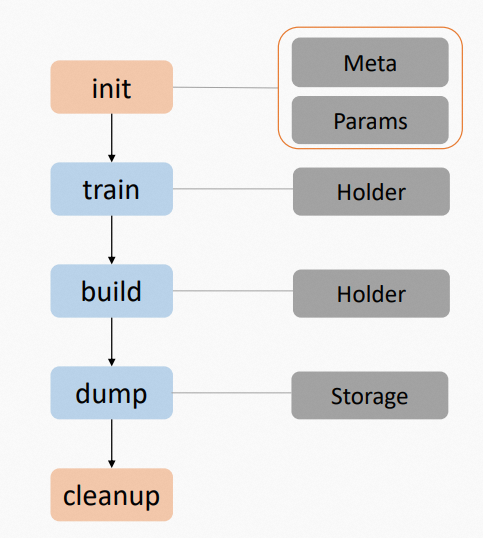
IndexBuilder を初期化する。
データ トレーニング を実行する。
インデックスを構築する。
インデックスをダンプする。
リソースをクリーンアップする。
Proxima カーネルは、ClusteringBuilder、LinearBuilder、HnswBuilder、SsgBuilder など、複数の組み込み Builder プラグインを提供します。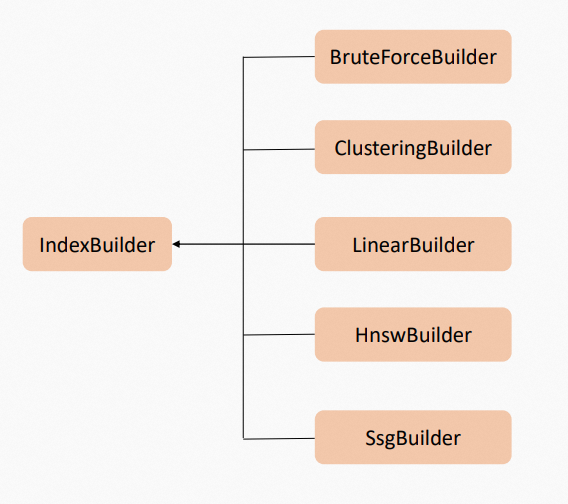
IndexConverter
IndexConverter は、固有ベクトルを変換するために使用されます。たとえば、このモジュールは、固有ベクトルに対して次元削減、半精度浮動小数点変換、および INT8 量子化を実行できます。このモジュールは、単独で使用することも、ベクトル検索プロセスの一部として使用することもできます。
ほとんどの場合、IndexConverter はベクトル検索プロセスで IndexReformer と一緒に使用されます。 IndexConverter と IndexReformer の関係は、IndexBuilder と IndexSearcher の関係に似ています。 IndexConverter は IndexBuilder の前提条件です。 IndexConverter が固有ベクトルを変換した後、IndexBuilder はインデックスを構築します。オンライン検索中に、すべてのクエリ ベクター は IndexReformer によって変換され、検索のために IndexSearcher に送信されます。
IndexMeasure
IndexMeasure は、ベクトル間の類似度を計算するために使用されます。距離が小さいほど、類似性が高いことを示します。 IndexMeasure のプラグインの名前と関連 パラメーター の詳細については、「IndexMeasure パラメーター」をご参照ください。
距離計算式
数値距離
距離パラメーター
式
ユークリッド距離の二乗
$$\sum_{i=0}^n (u_i - v_i)^2$$ユークリッド距離
$$\sqrt{\sum_{i=0}^n (u_i - v_i)^2}$$正規化ユークリッド距離
$$\sqrt{\frac{1}{2}\frac{\sum_{i=0}^n [(u_i-\bar{u}) - (v_i-\bar{v})]^2}{\sum_{i=0}^n [(u_i-\bar{u})^2 + (v_i-\bar{v})^2]}}$$正規化ユークリッド距離の二乗
$$\frac{1}{2}\frac{\sum_{i=0}^n [(u_i-\bar{u}) - (v_i-\bar{v})]^2}{\sum_{i=0}^n [(u_i-\bar{u})^2 + (v_i-\bar{v})^2]}$$マンハッタン距離
$$\sum_{i=0}^n |u_i - v_i|$$チェビシェフ距離 (チェス盤距離)
$$\max_{i=0} |u_i - v_i|$$コサイン類似度
$$1.0 - \frac{\sum_{i=0}^n u_iv_i}{\sqrt{\sum_{i=0}^n u_i^2}\sqrt{\sum_{i=0}^n v_i^2}}$$マイナス内積
$$-\sum_{i=0}^n u_iv_i$$キャンベラ距離
$$\sum_{i=0}^n\frac{|u_i-v_i|}{|u_i|+|v_i|}$$ブレイ・カーティス非類似度
$$\frac{\sum_{i=0}^n|u_i-v_i|}{\sum_{i=0}^n|u_i+v_i|}$$相関
$$1.0 - \frac{\sum_{i=0}^n(u_i-\bar{u})(v_i-\bar{v})}{\sqrt{\sum_{i=0}^n(u_i-\bar{u})^2} \sqrt{\sum_{i=0}^n(v_i-\bar{v})^2}}$$バイナリ
$$[!u == v]$$バイナリ イメージ 距離
距離パラメーター
式
ハミング距離
$$M_{10}+M_{01}$$ジャカード指数
$$\frac{M_{10}+M_{01}}{M_{11}+M_{10}+M_{01}}$$一致
$$\frac{M_{10}+M_{01}}{M_{11}+M_{10}+M_{01}+M_{00}}=\frac{M_{10}+M_{01}}{N}$$ダイス係数
$$\frac{M_{10}+M_{01}}{2M_{11}+M_{10}+M_{01}}$$ロジャース・タニモト係数
$$\frac{2(M_{10}+M_{01})}{M_{11}+2(M_{10}+M_{01})+M_{00}}$$ラッセル・ラオ係数
$$\frac{M_{10}+M_{01}+M_{00}}{N}$$ソカル・ミシュナー係数
$$\frac{M_{10}+M_{01}}{M_{11}+M_{10}+M_{01}+M_{00}}=\frac{M_{10}+M_{01}}{N}$$ソカル・スニース I
$$1.0 - \frac{M_{11}}{M_{11} + 2(M_{10}+M_{01})}=\frac{2(M_{10}+M_{01})}{M_{11}+2(M_{10}+M_{01})}$$ソカル・スニース II
$$1.0 - \frac{2(M_{11} + M_{00})}{2(M_{11} + M_{00}) + M_{10} + M_{01}} = \frac{M_{10} + M_{01}}{2N - (M_{10} + M_{01})}$$ソカル・スニース III
$$1.0 - \frac{M_{11} + M_{00}}{M_{10} + M_{01}} = \frac{2(M_{10} + M_{01}) - N}{M_{10} + M_{01}}$$ソカル・スニース IV
$$1.0 - \frac{1}{4}(\frac{M_{11}}{M_{11} + M_{10}} + \frac{M_{11}}{M_{11} + M_{01}} + \frac{M_{00}}{M_{10} + M_{00}} + \frac{M_{00}}{M_{01} + M_{00}})$$ソカル・スニース V
$$1.0 - \frac{M_{11}M_{00}}{\sqrt{(M_{11} + M_{10}) (M_{11} + M_{01}) (M_{10} + M_{00}) (M_{01} + M_{00})}}$$クルチンスキー I
$$1.0-\frac{S_{AB}}{S_A+S_B-2S_{AB}} = 1.0-\frac{M_{11}}{M_{10}+M_{01}} = \frac{M_{10}+M_{01}-M_{11}}{M_{10}+M_{01}}$$クルチンスキー II
$$1.0-\frac{1}{2}\left(\frac{S_{AB}}{S_{A}}+\frac{S_{AB}}{S_{B}}\right)$$ユール係数
$$\frac{2M_{10}M_{01}}{M_{11}M_{00}+M_{10}M_{01}}$$
IndexSearcher
IndexSearcher は、主に k 近傍法 (kNN) 検索に使用されます。このモジュールは、オフラインで構築されたインデックスを読み取り専用モードでロードし、オンライン検索を実行します。
次の図は、IndexSearcher を呼び出すプロセスを示しています。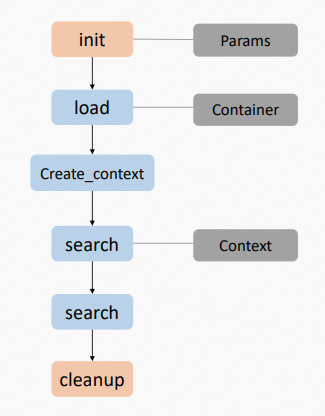
IndexSearcher を初期化する。
インデックス データ をロードする。
検索のデータ コンテキスト を作成する。
検索を実行する。
インデックス データ をアンロードする。
リソースをクリーンアップする。
IndexSearcher は並列検索をサポートしています。ただし、ユーザーの シナリオ と 環境 は大きく異なるため、エンジン ユーザーは並列検索を制御する必要があります。 Proxima CE は、検索結果と検索プロセスで生成された中間 データ を格納する Searcher Context をサポートしています。各 コンテキストオブジェクト は再利用できます。スレッドは コンテキストオブジェクト に順番にのみアクセスできます。複数のスレッドが同時に コンテキストオブジェクト にアクセスすることはできません。並列検索を実装するには、複数の コンテキストオブジェクト を作成する必要があります。 Proxima カーネルは、ClusteringSearcher、LinearSearcher、HnswSearcher、SsgSearcher など、さまざまな組み込み Searcher プラグインを提供します。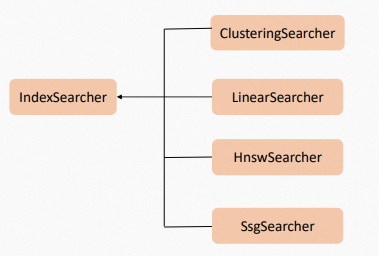
IndexBuilder パラメーター
ClusteringBuilder
重要proxima.hc.builder.max_document_count パラメーターと proxima.hc.builder.centroid_count パラメーターの少なくとも 1 つを設定する必要があります。
パラメーター
データ型
デフォルト値
説明
proxima.hc.builder.max_document_count
UNIT32
デフォルト値なし
proxima.hc.builder.centroid_count パラメーターを設定しない場合、proxima.hc.builder.max_document_count パラメーターを使用して、クラスタ重心の数が計算されます。
proxima.hc.builder.centroid_count
STRING
デフォルト値なし
クラスタに使用するクラスタ重心の数。階層型クラスタがサポートされています。階層型クラスタの異なる層の重心の数をアスタリスク
(*)で区切ります。このパラメーターを設定しない場合、クラスタに使用される重心の数は、proxima.hc.builder.max_document_count パラメーターの値に基づいて自動的に推定されます。1 層クラスタのサンプル値:1000。
2 層クラスタのサンプル値:100*100。
2 つの層でクラスタ重心を使用する場合は、高い再現率を確保するために、層 2 よりも層 1 でより多くのクラスタ重心を設定することをお勧めします。経験値に基づくと、層 1 の重心の数は、層 2 の重心の数の 10 倍に設定する必要があります。
proxima.hc.builder.thread_count
UNIT32
0
インデックス構築中に有効になるスレッドの数。このパラメーターを 0 に設定すると、デフォルトの CPU コア数が使用されます。
HnswBuilder
パラメーター
データ型
デフォルト値
説明
proxima.hnsw.builder.thread_count
UNIT32
0
インデックス構築中に有効になるスレッドの数。このパラメーターを 0 に設定すると、デフォルトの CPU コア数が使用されます。
proxima.hnsw.builder.efconstruction
UNIT32
500
グラフの精度を指定します。このパラメーターを大きな値に設定すると、グラフの精度は高くなりますが、構築に時間がかかります。
proxima.hnsw.builder.max_neighbor_count
UNIT32
100
グラフ内の近傍の数。このパラメーターを大きな値に設定すると、グラフの精度は高くなりますが、計算とストレージのオーバーヘッドが大きくなります。このパラメーターは、特徴量の次元数より大きい値に設定しないことをお勧めします。最大値は 65535 です。
SsgBuilder
パラメーター
データ型
デフォルト値
説明
proxima.ssg.builder.thread_count
UNIT32
0
インデックス構築に使用されるスレッドの数。
proxima.ssg.builder.efconstruction
UNIT32
500
グラフの精度を指定します。このパラメーターを大きな値に設定すると、グラフの精度は高くなりますが、構築に時間がかかります。
proxima.ssg.builder.max_neighbor_count
UNIT32
100
グラフ内の近傍の数。このパラメーターを大きな値に設定すると、グラフの精度は高くなりますが、計算とストレージのオーバーヘッドが大きくなります。このパラメーターは、特徴量の次元数より大きい値に設定しないことをお勧めします。最大値は 65535 です。
proxima.ssg.builder.centroid_count
UNIT32
0
トレーニングサンプルから生成されるクラスタ重心の数。クラスタ重心の数が多いほど、グラフ構築コストは高くなり、グラフ精度は高くなります。 doc テーブルのデータレコード数に基づいて、このパラメーターを設定することをお勧めします。
doc テーブルのデータ レコード数が 200 万未満の場合は、このパラメーターを 2000 に設定します。
doc テーブルのデータ レコード数が 200 万から 1,000 万の場合は、このパラメーターを 5000 に設定します。
doc テーブルのデータ レコード数が 1,000 万を超える場合は、このパラメーターを 8000 に設定します。
proxima.ssg.builder.scan_ratio
FLOAT
0.01
クラスタ スキャン率。デフォルト値:1%。この値は、グラフの精度を制御します。このパラメーターを大きな値に設定すると、グラフの精度は高くなりますが、グラフ構築コストは線形的に増加します。 doc テーブルのデータ レコード数に基づいて、このパラメーターを設定することをお勧めします。
doc テーブルのデータ レコード数が 200 万未満の場合は、次の式を使用してこのパラメーターの値を計算します。
10000/doc_count。2 million and 10 milliondoc テーブルのデータ レコード数が 200 万から 1,000 万の場合は、次の式を使用してこのパラメーターの値を計算します。20000/doc_count。doc テーブルのデータ レコード数が 1,000 万を超える場合は、次の式を使用してこのパラメーターの値を計算します。
50000/doc_count。
GcBuilder
重要proxima.gc.builder.centroid_count パラメーターを設定する必要があります。
パラメーター
データ型
デフォルト値
説明
proxima.gc.builder.thread_count
UNITt32
0
インデックス構築中に有効になるスレッドの数。このパラメーターを 0 に設定すると、デフォルトの CPU コア数が使用されます。
proxima.gc.builder.centroid_count
STRING
デフォルト値なし
クラスタに使用するクラスタ重心の数。階層型クラスタがサポートされています。階層型クラスタの異なる層の重心の数をアスタリスク
(*)で区切ります。1 層クラスタのサンプル値:1000。
2 層クラスタのサンプル値:100*100。
2 つの層でクラスタ重心を使用する場合は、高い再現率を確保するために、層 2 よりも層 1 でより多くのクラスタ重心を設定することをお勧めします。経験値に基づくと、層 1 の重心の数は、層 2 の重心の数の 10 倍に設定する必要があります。
LinearBuilder
パラメーター
データ型
デフォルト値
説明
proxima.linear.builder.column_major_order
STRING
false
インデックスの構築時に、インデックスの特徴量の順序を指定する方法を指定します。このパラメーターの有効な値は、false と true です。値 false は、インデックスの特徴量を行で順序付けすることを指定します。値 true は、インデックスの特徴量を列で順序付けすることを指定します。
QcBuilder
説明proxima.qc.builder.centroid_count パラメーターを設定する必要があります。
パラメーター
データ型
デフォルト値
説明
proxima.qc.builder.thread_count
UNIT32
0
インデックス構築中に有効になるスレッドの数。このパラメーターを 0 に設定すると、デフォルトの CPU コア数が使用されます。
proxima.qc.builder.centroid_count
STRING
デフォルト値なし
クラスタに使用するクラスタ重心の数。階層型クラスタがサポートされています。階層型クラスタの異なる層の重心の数をアスタリスク
(*)で区切ります。1 層クラスタのサンプル値:1000。
2 層クラスタのサンプル値:100*100。
2 つの層でクラスタ重心を使用する場合は、高い再現率を確保するために、層 2 よりも層 1 でより多くのクラスタ重心を設定することをお勧めします。経験値に基づくと、層 1 の重心の数は、層 2 の重心の数の 10 倍に設定する必要があります。
proxima.qc.builder.quantizer_class
STRING
デフォルト値なし
量子化器。デフォルトでは、システムは量子化器を使用しません。有効な値:Int8QuantizerConverter、HalfFloatConverter、および DoubleBitConverter。ほとんどの場合、量子化器はクエリ パフォーマンスを向上させ、インデックス サイズを削減できますが、再現率は低下します。
proxima.qc.builder.quantizer_params
IndexParams
デフォルト値なし
proxima.qc.builder.quantizer_class に指定した量子化器に関連するパラメーターを指定します。
IndexSearcher パラメーター
ClusteringSearcher
パラメーター
データ型
デフォルト値
説明
proxima.hc.searcher.max_scan_count
UNIT32
デフォルト値なし
ドキュメントテーブル内でオンライン検索できるデータレコードの最大数。このパラメーターは、検索範囲を指定します。値が大きいほど、取得率が高くなります。ただし、この値は、proxima.hc.searcher.scan_count_in level パラメーターで指定されたクラスタ重心下のドキュメントテーブル内のデータレコード数を超えることはできません。
proxima.hc.searcher.scan_ratio
FLOAT
0.01
このパラメーターは、max_scan_count パラメーターの値を計算するために使用されます。計算式:
ドキュメントテーブル内のデータレコードの総数 × scan_ratio。HnswSearcher
パラメーター
データ型
デフォルト値
説明
proxima.hnsw.searcher.ef
UNIT32
500
ドキュメントテーブル内でオンライン検索できるデータレコードの最大数。このパラメーターは、検索範囲を指定します。値が大きいほど、取得率が高くなります。ただし、この値は、 proxima.hc.searcher.scan_count_in level パラメーターで指定されたクラスタ重心下のドキュメントテーブル内のデータレコード数を超えることはできません。
proxima.hnsw.searcher.max_scan_ratio
FLOAT
0.1f
このパラメーターは、max_scan_count パラメーターの値を計算するために使用されます。計算式:
ドキュメントテーブル内のデータレコードの総数 × scan_ratio。proxima.hnsw.searcher.brute_force_threshold
INT
1000
しきい値。ドキュメントテーブル内のデータレコードの総数がこのしきい値未満の場合、線形検索が実行されます。
SsgSearcher
パラメーター
データ型
デフォルト値
説明
proxima.ssg.searcher.ef
UNIT32
500
検索精度。このパラメーターに大きな値を設定すると、ドキュメントテーブル内でスキャンされるデータレコードの数が増え、取得率が高くなります。
proxima.ssg.searcher.max_scan_ratio
UNIT32
0
ドキュメントテーブル内のデータレコードの最大スキャン率。このパラメーターは、切り捨てポリシーを指定するために使用されます。デフォルト値 0 は、このパラメーターが使用されていないことを示します。
GcSearcher
パラメーター
データ型
デフォルト値
説明
proxima.gc.searcher.scan_ratio
FLOAT
0.01
このパラメーターは、max_scan_count パラメーターの値を計算するために使用されます。計算式:
ドキュメントテーブル内のデータレコードの総数 × scan_ratio。LinearSearcher
パラメーター
データ型
デフォルト値
説明
proxima.linear.searcher.read_block_size
UNIT32
1024*1024
検索フェーズで一度に読み取ることができるメモリのサイズ。約 1 MB のメモリを読み取ることができます。このパラメーターに小さい値を設定すると、クエリ/秒 (QPS) に大きな影響があります。このパラメーターに大きい値を設定すると、より多くのメモリが使用されます。デフォルト値 1024*1024 を保持することをお勧めします。
QcSearcher
パラメーター
データ型
デフォルト値
説明
proxima.qc.searcher.scan_ratio
FLOAT
0.01
このパラメーターは、max_scan_count パラメーターの値を計算するために使用されます。計算式:
ドキュメントテーブル内のデータレコードの総数 × scan_ratio。proxima.qc.searcher.brute_force_threshold
INT
1000
しきい値。ドキュメントテーブル内のデータレコードの総数がこのしきい値未満の場合、線形検索が実行されます。
IndexConverter パラメーター
MipsConverter
パラメーター
データ型
デフォルト値
説明
proxima.mips.converter.m_value
UINT32
デフォルト値なし
M の値。追加できるディメンションの数を示します。ほとんどの場合、最大 4 つのディメンションを追加できます。
proxima.mips.converter.u_value
FLOAT
0.38196601
U の値。有効な値:0 ~ 1.0。
proxima.mips.converter.forced_half_float
BOOLEAN
false
データを FP32 から FP16 に強制的に変換するかどうかを指定します。
proxima.mips.converter.spherical_injection
BOOLEAN
false
データ変換に球面注入を使用するかどうかを指定します。球面注入を使用してデータ変換した後、データに 1 つのディメンションが追加されます。
HalfFloatConverter
パラメーター構成は必要ありません。
DoubleBitConverter
パラメーター
データ型
デフォルト値
説明
proxima.double_bit.converter.train_sample_count
INT
0
トレーニングに使用するデータ量。このパラメーターを 0 に設定すると、ホルダー内のすべてのデータが使用されます。
Int8QuantizerConverter
パラメーター構成は必要ありません。
Int4QuantizerConverter
パラメーター構成は必要ありません。
NormalizeConverter
パラメーター
データ型
デフォルト値
説明
proxima.normalize.reformer.forced_half_float
BOOLEAN
false
データを FP32 から FP16 に強制的に変換するかどうかを指定します。
proxima.normalize.reformer.p_value
UNIT32
2
P ノルムにおける P の値。
IndexReformer のパラメーター
MipsReformer
パラメーター
データ型
デフォルト値
説明
proxima.mips.reformer.m_value
UINT32
4
M の値。これは、追加できるディメンションの数を示します。ほとんどの場合、最大 4 つのディメンションを追加できます。
proxima.mips.reformer.u_value
FLOAT
0.38196601
U の値。有効な値:0 より大きく 1.0 より小さい値。
proxima.mips.reformer.l2_norm
FLOAT
0.0
トレーニングから取得された L2 ノルムの値。
proxima.mips.reformer.normalize
BOOLEAN
false
結果を正規化するかどうかを指定します。
proxima.mips.reformer.forced_half_float
BOOLEAN
false
データを FP32 から FP16 に強制的に変換するかどうかを指定します。
HalfFloatReformer
パラメーター構成は必要ありません。
IndexMeasure パラメーター
Canberra
パラメーター構成は必要ありません。
Chebyshev
パラメーター構成は必要ありません。
SquaredEuclidean
パラメーター構成は必要ありません。
Euclidean
パラメーター構成は必要ありません。
GeographicalDistance
パラメーター構成は必要ありません。
Hamming
パラメーター構成は必要ありません。
InnerProduct
パラメーター構成は必要ありません。
Manhattan
パラメーター構成は必要ありません。
Matching
パラメーター構成は必要ありません。
MipsSquaredEuclidean
パラメーター
データ型
デフォルト値
説明
proxima.mips_euclidean.measure.injection_type
INT
0
内積特徴変換の注入タイプ。有効な値:
0 LocalizedSpherical
1 Spherical
2 RepeatedQuadratic
3 Identity
RogersTanimoto
パラメーター構成は必要ありません。
RussellRao
パラメーター構成は必要ありません。