このトピックでは、OSS 内の Parquet 形式の外部テーブルを作成、読み取り、書き込みする方法について説明します。
適用範囲
OSS 外部テーブルはクラスタープロパティをサポートしていません。
単一ファイルのサイズは 2 GB を超えることはできません。2 GB を超えるファイルは分割する必要があります。
MaxCompute と OSS は同じリージョンにある必要があります。
サポートされるデータ型
MaxCompute のデータ型に関する詳細については、「データ型バージョン 1.0」および「データ型バージョン 2.0」をご参照ください。
JNI モード:
set odps.ext.parquet.native=false。これは、元の Java ベースのオープンソース実装を使用して Parquet データファイルを解析します。読み取りと書き込みの両方をサポートします。ネイティブモード:
set odps.ext.parquet.native=true。これは、新しい C++ ベースのネイティブ実装を使用して Parquet データファイルを解析します。読み取りのみをサポートします。モード
Java モード (読み取り/書き込み)
ネイティブモード (読み取り専用)
TINYINT
SMALLINT
INT
BIGINT
BINARY
FLOAT
DOUBLE
DECIMAL(precision,scale)
VARCHAR(n)
CHAR(n)
STRING
DATE
DATETIME
TIMESTAMP
TIMESTAMP_NTZ
BOOLEAN
ARRAY
MAP
STRUCT
JSON
サポートされる圧縮形式
圧縮プロパティを持つ OSS ファイルを読み書きする場合、テーブル作成ステートメントに
with serdepropertiesプロパティ構成を追加する必要があります。詳細については、「with serdeproperties パラメーター」をご参照ください。サポートされる Parquet ファイル形式: ZSTD、SNAPPY、GZIP 圧縮。
スキーマエボリューションのサポート
Parquet 外部テーブルは、テーブルスキーマとファイル列を照合し、名前によって列値をマッピングします。
次の表のデータ互換性に関する注意では、スキーマが変更された外部テーブルで、新しいスキーマに一致するデータを読み取れるかどうか、また、新しいスキーマに一致しない既存の履歴データを読み取れるかどうかについて説明します。
操作タイプ | サポート | 説明 | データ互換性に関する注意 |
列の追加 |
|
| |
列の削除 | Parquet 外部テーブルは、名前によって列値をマッピングします。 | 互換性あり | |
列の並べ替え | Parquet 外部テーブルは、名前によって列値をマッピングします。 | 互換性あり | |
列のデータ型の変更 | この操作はサポートされていません。Parquet は厳密なスキーマ検証を強制します。互換性のある型を変更すると、互換性が損なわれる可能性があります。 | 該当なし | |
列の名前の変更 | この操作はサポートされていません。Parquet は厳密なスキーマ検証を強制します。互換性のある型を変更すると、互換性が損なわれる可能性があります。 | 該当なし | |
列のコメントの更新 | コメントは 1024 バイト以下の有効な文字列である必要があります。そうでない場合、エラーが発生します。 | 互換性あり | |
列の NULL 値許容属性の変更 | この操作はサポートされていません。列はデフォルトで NULL 値を許容します。 | 該当なし |
外部テーブルの作成
構文
Parquet ファイルのスキーマが外部テーブルのスキーマと異なる場合:
列数の不一致: Parquet ファイルの列数が外部テーブルの DDL より少ない場合、不足している列は NULL を返します。Parquet ファイルの列数が多い場合、余分な列は無視されます。
列の型の不一致: Parquet ファイルの列の型が外部テーブルの DDL の対応する列の型と異なる場合、読み取りは失敗します。たとえば、STRING (または INT) を使用して INT (または STRING) データを読み取ろうとすると、エラー
ODPS-0123131:User defined function exception - Traceback:xxxが返されます。
簡易構文
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name>
(
<col_name> <data_type>,
...
)
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type>, ...)]
STORED AS parquet
LOCATION '<oss_location>'
[tblproperties ('<tbproperty_name>'='<tbproperty_value>',...)];詳細構文
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name>
(
<col_name> <data_type>,
...
)
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type>, ...)]
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH serdeproperties(
'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole',
'mcfed.parquet.compression'='ZSTD/SNAPPY/GZIP'
)
STORED AS parquet
LOCATION '<oss_location>'
;共通パラメーター
共通パラメーターの詳細については、「基本構文パラメーター」をご参照ください。
固有パラメーター
with serdeproperties パラメーター
プロパティ名 | ユースケース | 説明 | プロパティ値 | デフォルト値 |
mcfed.parquet.compression | 圧縮形式で Parquet データを OSS に書き込む際にこのプロパティを追加します。 | Parquet 圧縮設定。Parquet データはデフォルトで非圧縮です。 |
| なし |
mcfed.parquet.compression.codec.zstd.level |
| レベルが高いほど圧縮率は向上しますが、パフォーマンスは低下します。大規模な Parquet I/O の場合は、低いレベル (3~5) を使用してください。例: | 有効な値: 1~22。 | 3 |
parquet.file.cache.size | OSS の読み取りパフォーマンスを向上させるためにこのプロパティを追加します。 | OSS データファイルのキャッシュサイズ (KB)。 | 1024 | なし |
parquet.io.buffer.size | OSS の読み取りパフォーマンスを向上させるためにこのプロパティを追加します。 | 1024 KB を超える OSS データファイルのバッファーサイズ (KB)。 | 4096 | なし |
tblproperties パラメーター
プロパティ名 | ユースケース | 説明 | プロパティ値 | デフォルト値 |
io.compression.codecs | OSS データファイルが Raw-Snappy 形式を使用する場合にこのプロパティを追加します。 | 組み込みのオープンソースデータリゾルバーは SNAPPY 形式をサポートしています。 このパラメーターを True に設定すると、MaxCompute は圧縮データを読み取ることができます。そうでない場合、MaxCompute はデータを読み取ることができません。 | com.aliyun.odps.io.compress.SnappyRawCodec. | なし |
odps.external.data.output.prefix (odps.external.data.prefix との下位互換性あり) | 出力ファイルのカスタムプレフィックスを設定するためにこのプロパティを追加します。 |
| mc_ などの有効な組み合わせ。 | なし |
odps.external.data.enable.extension | 出力ファイル名にファイル拡張子を表示するためにこのプロパティを追加します。 | True は拡張子を表示し、False は非表示にします。 |
| False |
odps.external.data.output.suffix | 出力ファイルのカスタムサフィックスを設定するためにこのプロパティを追加します。 | 英字、数字、アンダースコア (a–z、A–Z、0–9、_) のみを含む必要があります。 | _hangzhou などの有効な組み合わせ。 | なし |
odps.external.data.output.explicit.extension | カスタムファイル拡張子を設定するためにこのプロパティを追加します。 |
| jsonl などの有効な組み合わせ。 | なし |
mcfed.parquet.compression | 圧縮形式で Parquet データを OSS に書き込む際にこのプロパティを追加します。 | Parquet 圧縮設定。Parquet データはデフォルトで非圧縮です。 |
| なし |
mcfed.parquet.block.size | Parquet のブロックサイズを制御し、ストレージ効率と読み取りパフォーマンスに影響を与えます。 | Parquet チューニング設定。ブロックサイズ (バイト)。 | 非負整数 | 134217728 (128 MB) |
mcfed.parquet.block.row.count.limit | Parquet 外部テーブルへの書き込み時に行グループあたりのレコード数を制限し、メモリ不足 (OOM) エラーを回避します。 | Parquet チューニング設定。行グループあたりの最大レコード数。OOM が発生した場合は、この値を減らしてください。 使用上のヒント:
| 非負整数 | 2147483647 (Integer.MAX_VALUE) |
mcfed.parquet.page.size.row.check.min | Parquet 外部テーブルへの書き込み中のメモリチェックの頻度を制御し、OOM を防ぎます。 | Parquet チューニング設定。メモリチェック間の最小レコード数。OOM が発生した場合は、この値を減らしてください。 | 非負整数 | 100 |
mcfed.parquet.page.size.row.check.max | Parquet 外部テーブルへの書き込み中のメモリチェックの頻度を制御し、OOM を防ぎます。 | Parquet チューニングプロパティ。メモリチェック間の最小レコード数を指定します。メモリ不足エラーが発生した場合は、このパラメーターを減らしてください。 メモリ使用量の頻繁な計算が必要なため、このパラメーターを調整すると追加のオーバーヘッドが発生する可能性があります。 使用上のヒント:
| 非負整数 | 1000 |
mcfed.parquet.compression.codec.zstd.level | ZSTD 形式で Parquet データを OSS に書き込む際に、ZSTD 圧縮レベルを設定するためにこのプロパティを追加します。 | Parquet 圧縮設定。ZSTD 圧縮レベル。有効な値: 1~22。 | 非負整数 | 3 |
データの書き込み
MaxCompute の書き込み構文の詳細については、「書き込み構文」をご参照ください。
クエリと分析
SELECT 構文の詳細については、「クエリ構文」をご参照ください。
クエリ計画の最適化の詳細については、「クエリの最適化」をご参照ください。
LOCATION ファイルを直接クエリするには、「機能:スキーマレスクエリ」をご参照ください。
クエリの最適化: Parquet 外部テーブルは、クエリを最適化するために述語プッシュダウン (PPD) をサポートしています。パフォーマンス結果については、「述語プッシュダウン (Parquet PPD)」をご参照ください。
SQL の前にこれらのパラメーターを追加して PPD を有効にします:
-- PPD はネイティブモード (odps.ext.parquet.native = true) でのみ使用します。 -- Parquet ネイティブリーダーを有効にします。 SET odps.ext.parquet.native = true; -- Parquet PPD を有効にします。 SET odps.sql.parquet.use.predicate.pushdown = true;
述語プッシュダウン (Parquet PPD)
Parquet 外部テーブルは、ネイティブでは述語プッシュダウン (Parquet PPD) をサポートしていません。WHERE フィルター条件でクエリを実行すると、MaxCompute はデフォルトですべてのデータをスキャンするため、不要な I/O、リソース消費、クエリレイテンシーが発生します。そのため、MaxCompute は Parquet PPD パラメーターを導入しました。Parquet PPD を有効にすることで、データスキャンフェーズで Parquet ファイル自体のメタデータ機能を活用して Parquet RowGroup レベルのフィルタリングを実装し、クエリパフォーマンスを向上させ、リソース消費とコストを削減できます。
使用方法
述語プッシュダウン (Parquet PPD) の有効化
SQL クエリを実行する前に、
SETコマンドを使用して次の 2 つのセッションレベルのパラメーターを設定し、Parquet PDD を有効にします。-- Parquet ネイティブリーダーを有効にします。 set odps.ext.parquet.native = true; -- Parquet PPD を有効にします。 set odps.sql.parquet.use.predicate.pushdown = true;例
1 TB の TPCDS テストデータセットに基づき、この例では
tpcds_1t_store_salesParquet 外部テーブルを使用して、PPD を有効にしたフィルタリングクエリを実行します。総データ量は2879987999です。-- 外部テーブル tpcds_1t_store_sales を作成します。 CREATE EXTERNAL TABLE IF NOT EXISTS tpcds_1t_store_sales ( ss_sold_date_sk BIGINT, ss_sold_time_sk BIGINT, ss_item_sk BIGINT, ss_customer_sk BIGINT, ss_cdemo_sk BIGINT, ss_hdemo_sk BIGINT, ss_addr_sk BIGINT, ss_store_sk BIGINT, ss_promo_sk BIGINT, ss_ticket_number BIGINT, ss_quantity BIGINT, ss_wholesale_cost DECIMAL(7,2), ss_list_price DECIMAL(7,2), ss_sales_price DECIMAL(7,2), ss_ext_discount_amt DECIMAL(7,2), ss_ext_sales_price DECIMAL(7,2), ss_ext_wholesale_cost DECIMAL(7,2), ss_ext_list_price DECIMAL(7,2), ss_ext_tax DECIMAL(7,2), ss_coupon_amt DECIMAL(7,2), ss_net_paid DECIMAL(7,2), ss_net_paid_inc_tax DECIMAL(7,2), ss_net_profit DECIMAL(7,2) ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH serdeproperties( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole', 'mcfed.parquet.compression'='zstd' ) STORED AS parquet LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss_bucket_path/'; -- 1 TB の TPCDS テストデータをロードします。 INSERT OVERWRITE TABLE tpcds_1t_store_sales SELECT ss_sold_date_sk, ss_sold_time_sk, ss_item_sk, ss_customer_sk, ss_cdemo_sk, ss_hdemo_sk, ss_addr_sk, ss_store_sk, ss_promo_sk, ss_ticket_number, ss_quantity, ss_wholesale_cost, ss_list_price, ss_sales_price, ss_ext_discount_amt, ss_ext_sales_price, ss_ext_wholesale_cost, ss_ext_list_price, ss_ext_tax, ss_coupon_amt, ss_net_paid, ss_net_paid_inc_tax, ss_net_profit FROM bigdata_public_dataset.tpcds_1t.store_sales; -- クエリを実行します。 SELECT SUM(ss_sold_date_sk) FROM tpcds_1t_store_sales WHERE ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;
パフォーマンス比較
PPD を有効にすると、スキャンされるデータが減り、クエリのレイテンシーとリソース使用量が削減されます。
モード | 総行数 | スキャンされた行数 | スキャンされたバイト数 | Mapper 時間 | 総リソース使用量 | 注意 |
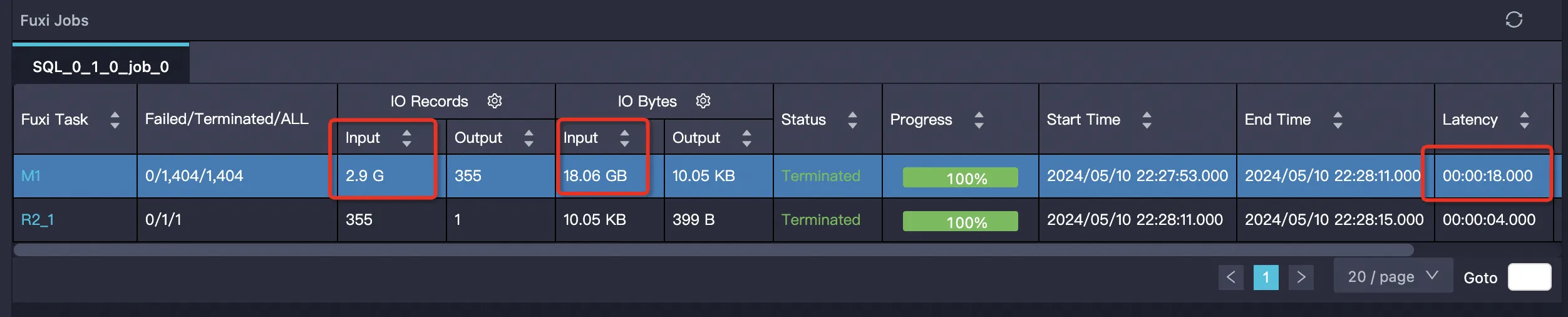
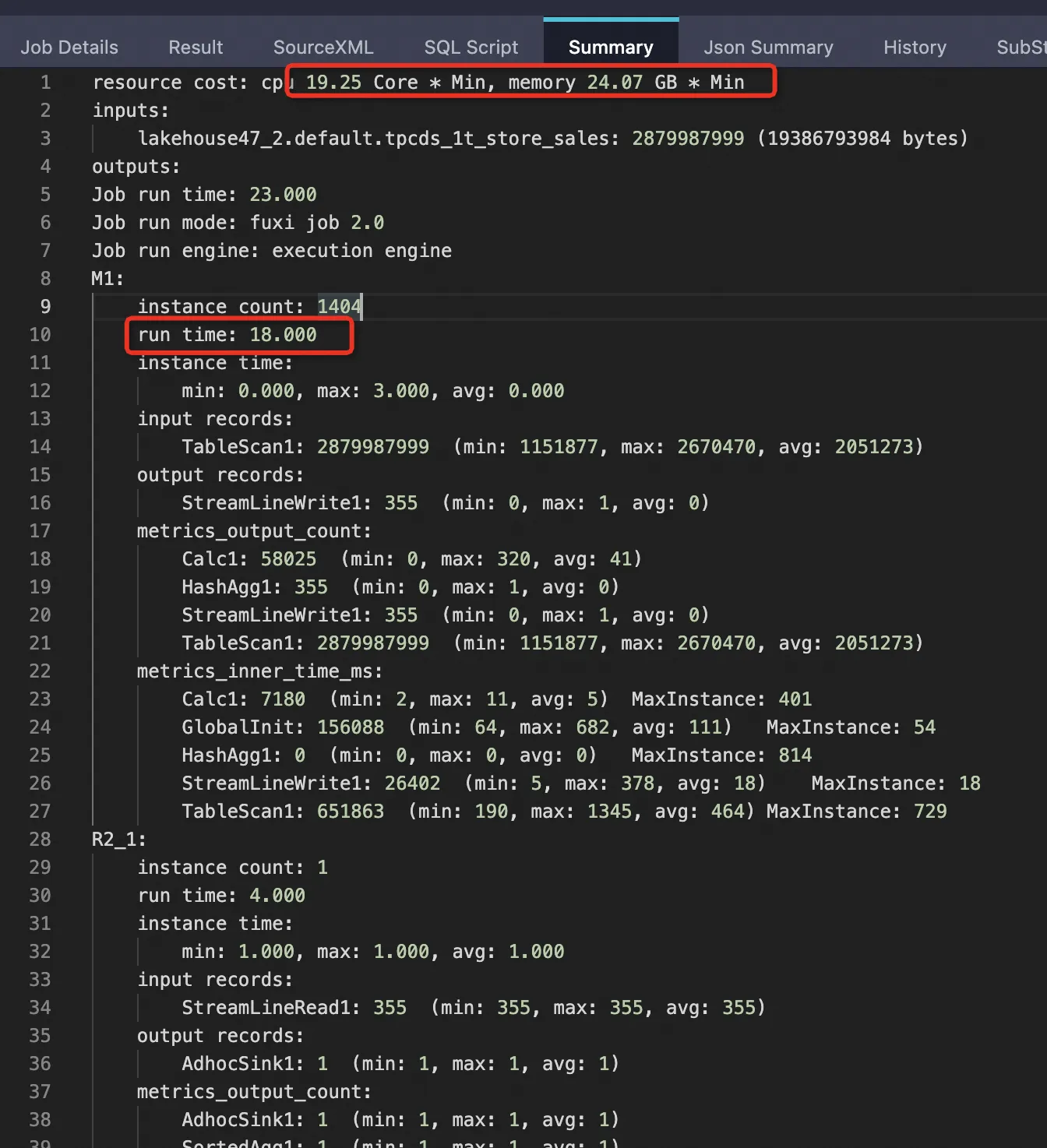
Parquet 外部テーブル (PPD 無効) | 2879987999 | 2879987999 (100%) | 19386793984 (100%) | 18 秒 | cpu 19.25 Core * Min, memory 24.07 GB * Min 100% | |
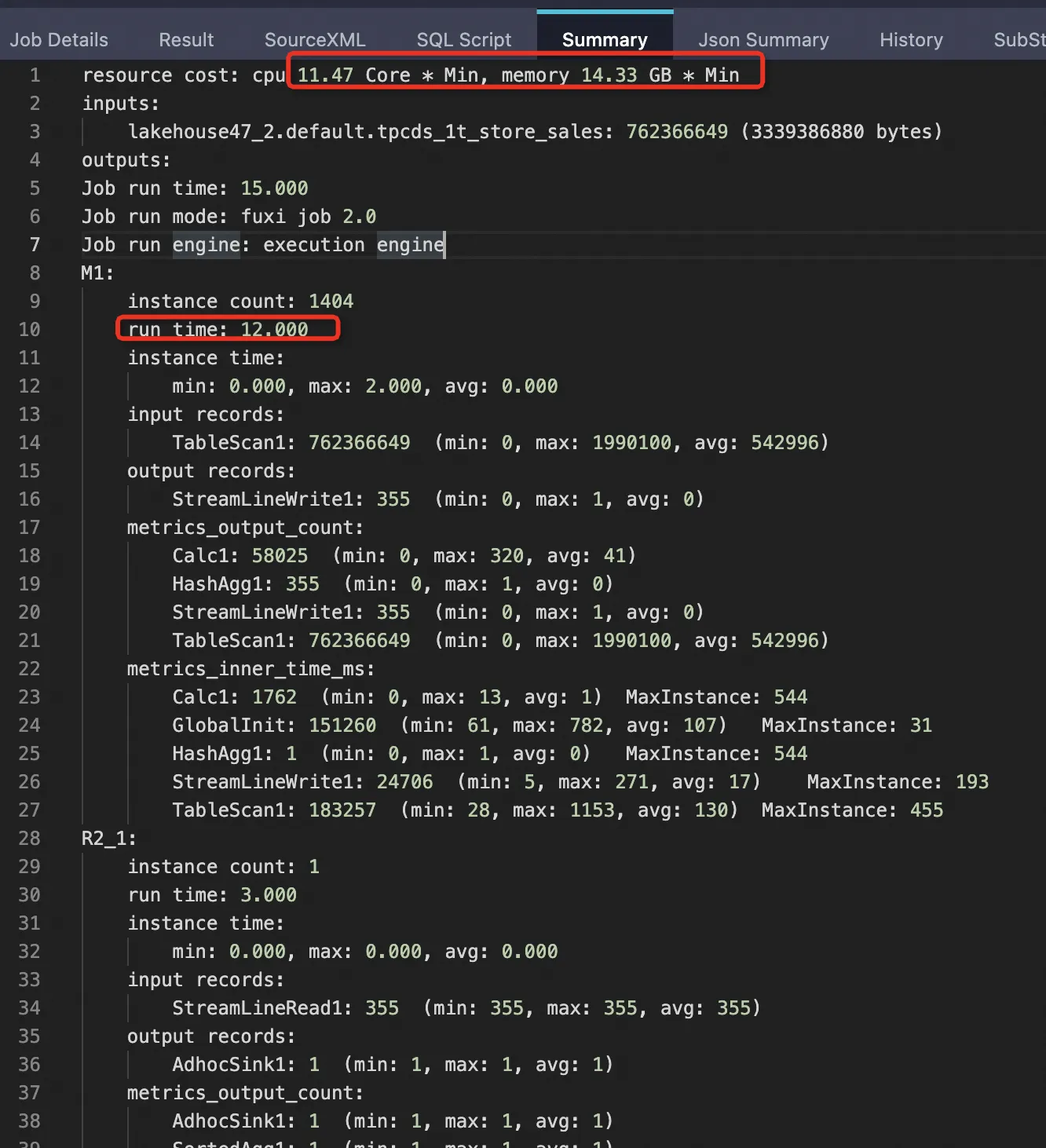
Parquet 外部テーブル (PPD 有効) | 2879987999 | 762366649 (26.47%) | 3339386880 (17.22%) | 12 秒 | cpu 11.47 Core * Min, memory 14.33 GB * Min ~59.58% | スキャンするデータを大幅に削減することで、レイテンシーとリソース使用量が削減されます |
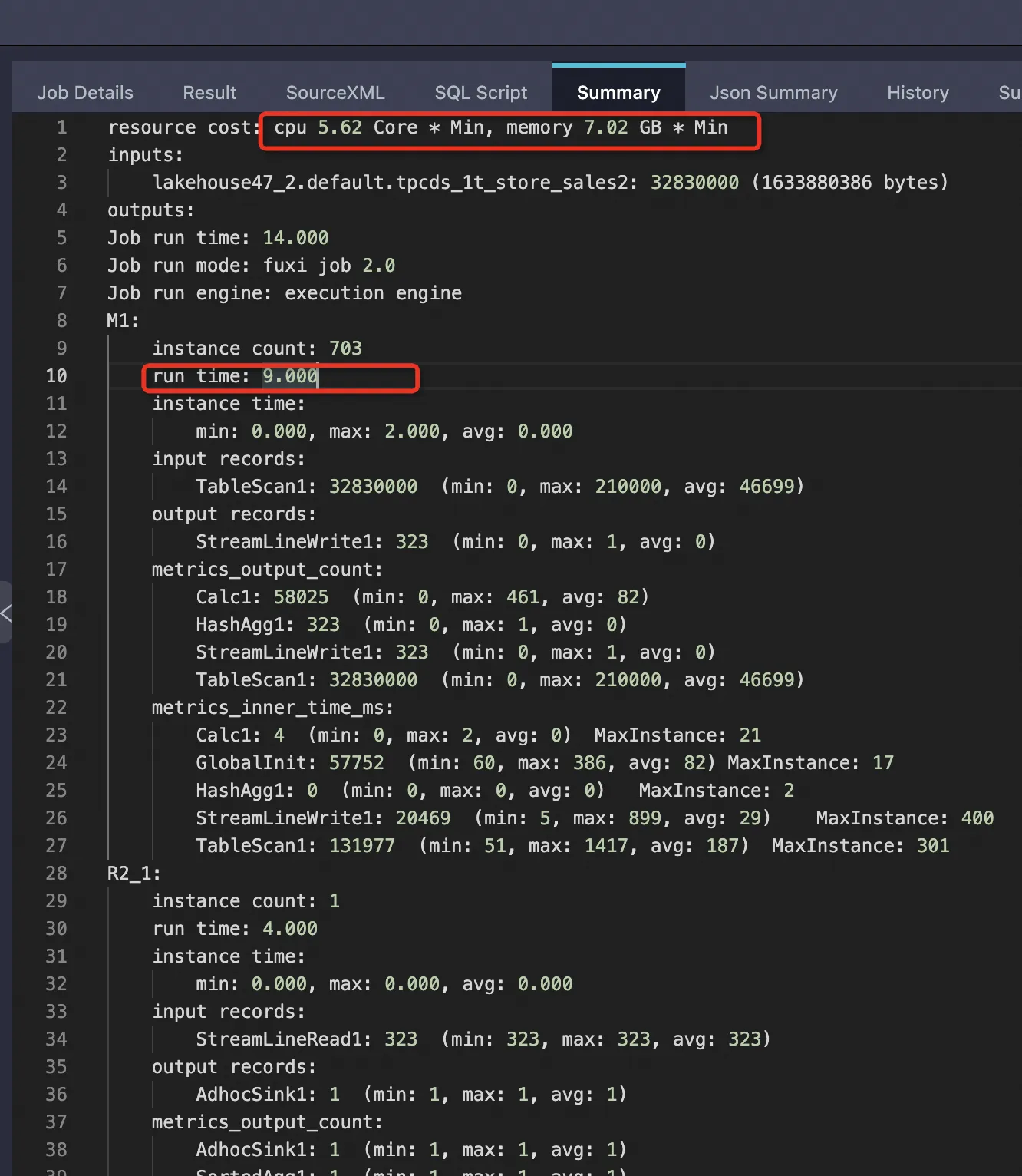
内部テーブル (PPD 有効) | 2879987999 | 32830000 (1.14%) | 1633880386 (8.43%) | 9 秒 | cpu 5.62 Core * Min, memory 7.02 GB * Min ~29.19% | 内部テーブルはソートされているため、PPD はさらに効果的に機能します |
テスト詳細
Parquet 外部テーブル (PPD 無効)
SET odps.ext.parquet.native = true; SET odps.sql.parquet.use.predicate.pushdown = false; SELECT SUM(ss_sold_date_sk) FROM tpcds_1t_store_sales WHERE ss_store_sk = 2 AND ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;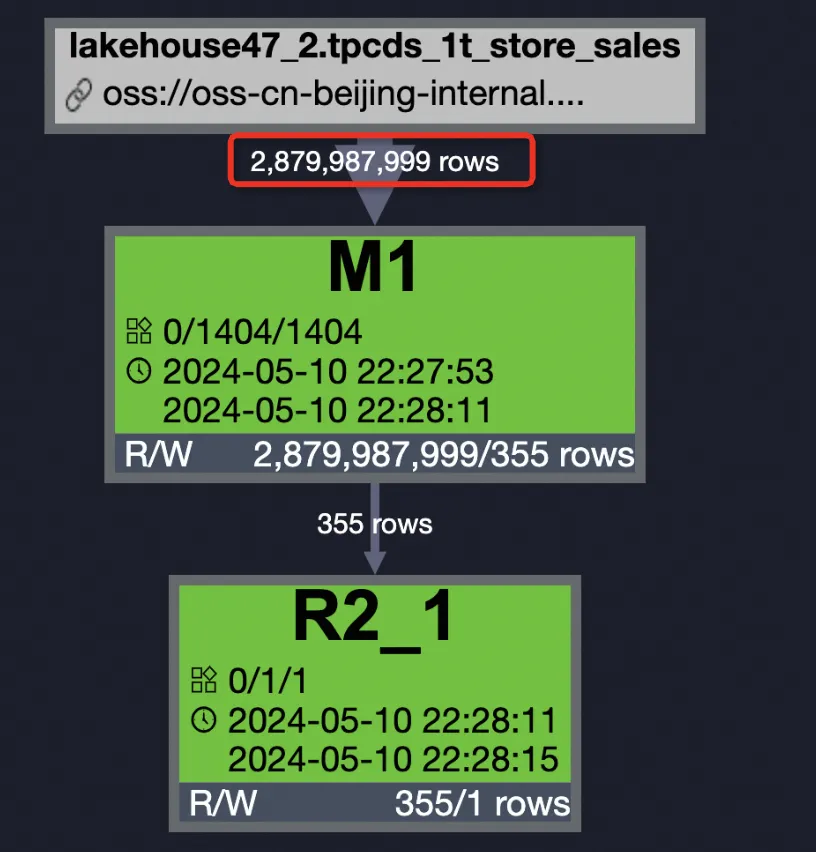
Parquet 外部テーブル (PPD 有効)
SET odps.ext.parquet.native = true; SET odps.sql.parquet.use.predicate.pushdown = true; SELECT SUM(ss_sold_date_sk) FROM tpcds_1t_store_sales WHERE ss_store_sk = 2 AND ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;
多くのマッパーは空であり、データの読み取りをスキップします:
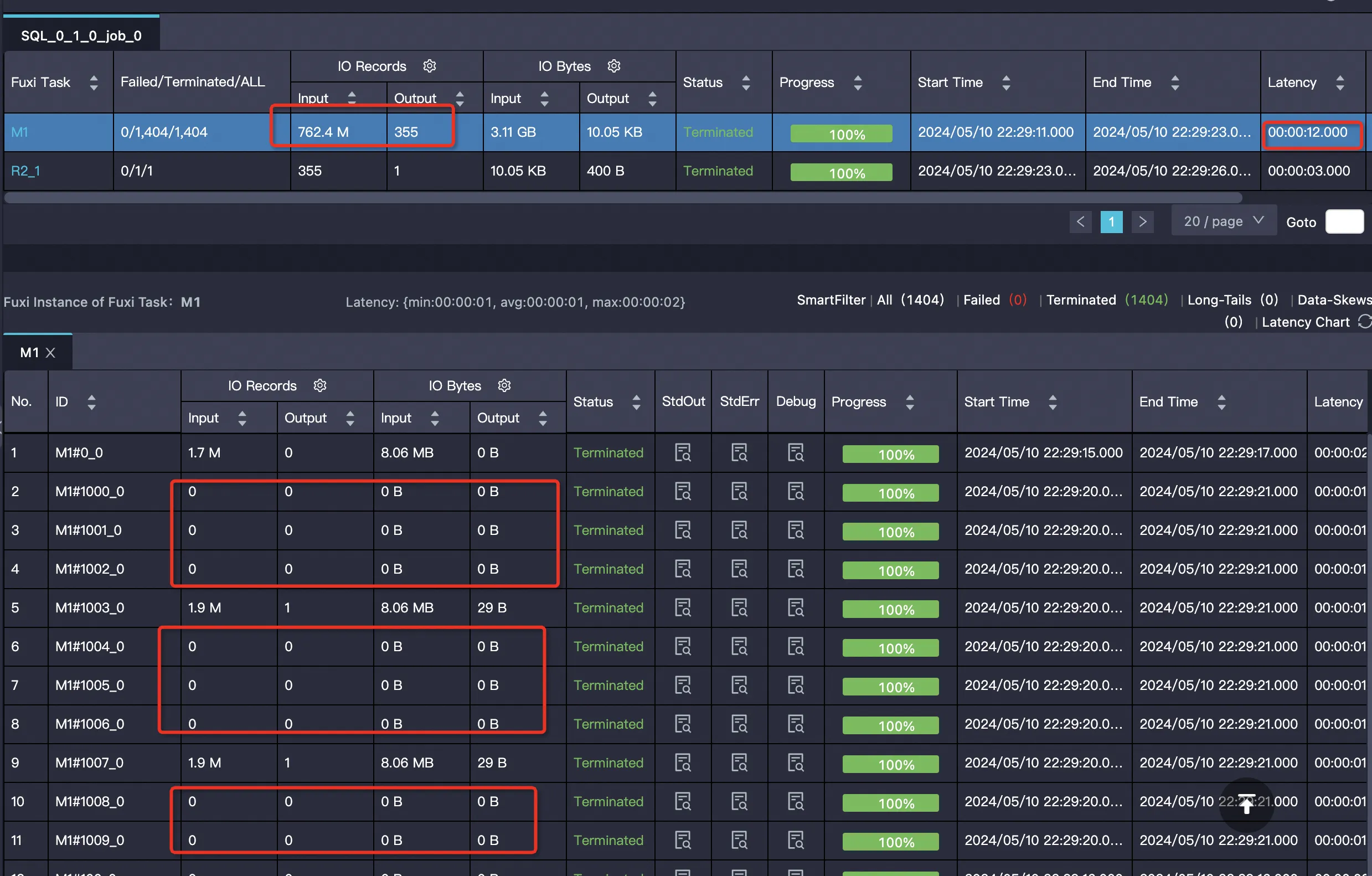
実際の RowGroup プルーニングログ:

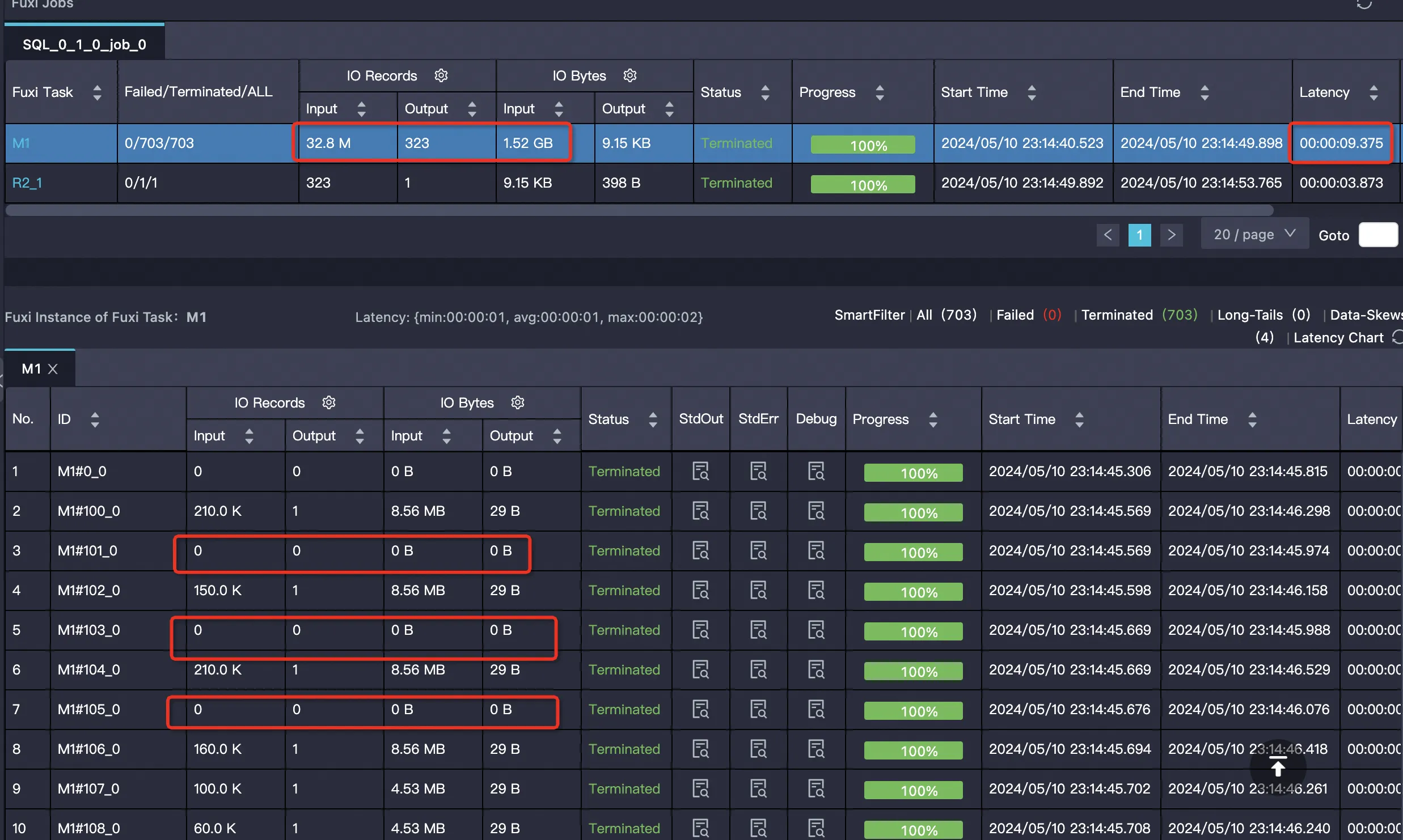
内部テーブル (PPD 有効)
内部テーブルのデータはソートされているため、プルーニングがより効果的です。
SELECT SUM(ss_sold_date_sk) FROM bigdata_public_dataset.tpcds_1t.store_sales WHERE ss_store_sk = 2 AND ss_sold_date_sk >= 2451871 AND ss_sold_date_sk <= 2451880;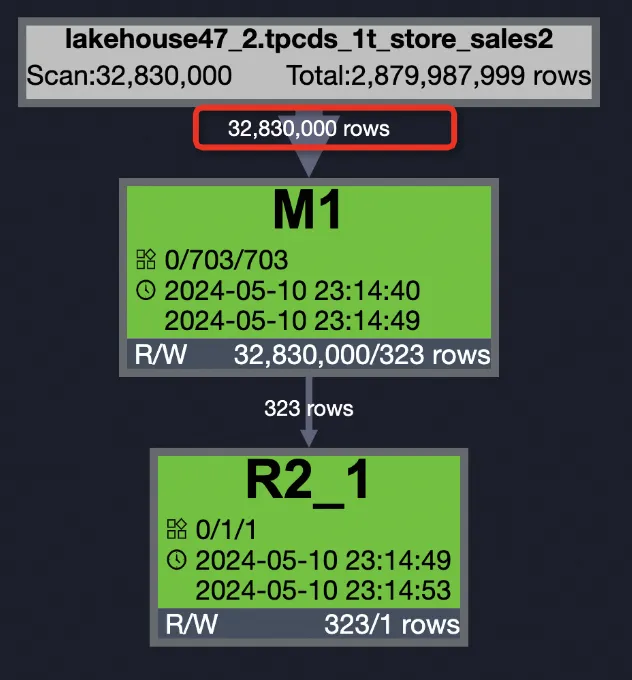
シナリオ例
この例では、ZSTD 圧縮された Parquet 外部テーブルを作成し、読み取りおよび書き込み操作を実行します。
前提条件
MaxCompute プロジェクトを作成済みであること。
OSS バケットと OSS ディレクトリを準備済みであること。詳細については、「バケットの作成」および「フォルダの管理」をご参照ください。
MaxCompute は特定のリージョンでのみ利用可能なため、リージョン間の接続性の問題が発生する可能性があります。MaxCompute プロジェクトと同じリージョンにある OSS バケットを使用することを推奨します。
権限付与
OSS にアクセスする権限が必要です。Alibaba Cloud アカウント (プライマリアカウント)、Resource Access Management (RAM) ユーザー、または RAM ロールは、OSS 外部テーブルにアクセスできます。権限付与の詳細については、「OSS の STS モード権限付与」をご参照ください。
MaxCompute プロジェクトでテーブル作成権限を持っています。テーブル操作の権限について詳しくは、「MaxCompute の権限」をご参照ください。
ZSTD 形式のデータファイルを準備します。
「サンプルデータ」の
oss-mc-testバケットに、ディレクトリparquet_zstd_jni/dt=20230418を作成します。パーティションデータをdt=20230418ディレクトリに配置します。ZSTD 圧縮された Parquet 外部テーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS mc_oss_parquet_data_type_zstd ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongtitue DOUBLE, recordTime STRING, direction STRING ) PARTITIONED BY (dt STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH serdeproperties( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole', 'mcfed.parquet.compression'='zstd' ) STORED AS parquet LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/parquet_zstd_jni/';OSS 外部テーブルがパーティション分割されている場合は、このコマンドを実行してパーティションを追加します。その他のオプションについては、「OSS 外部テーブルへのパーティションの追加」をご参照ください。
-- パーティションデータを追加します。 MSCK REPAIR TABLE mc_oss_parquet_data_type_zstd ADD PARTITIONS;Parquet 外部テーブルからデータを読み取ります。
SELECT * FROM mc_oss_parquet_data_type_zstd WHERE dt='20230418' LIMIT 10;結果の例:
+------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | dt | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | 1 | 12 | 76 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:10 | SW | 20230418 | | 1 | 1 | 51 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | 20230418 | | 1 | 2 | 13 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:01 | NE | 20230418 | | 1 | 3 | 48 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:02 | NE | 20230418 | | 1 | 4 | 30 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:03 | W | 20230418 | | 1 | 5 | 47 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:04 | S | 20230418 | | 1 | 6 | 9 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:05 | S | 20230418 | | 1 | 7 | 53 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:06 | N | 20230418 | | 1 | 8 | 63 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:07 | SW | 20230418 | | 1 | 9 | 4 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:08 | NE | 20230418 | | 1 | 10 | 31 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:09 | N | 20230418 | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+Parquet 外部テーブルにデータを書き込みます。
INSERT INTO mc_oss_parquet_data_type_zstd PARTITION ( dt = '20230418') VALUES (1,16,76,1,46.81006,-92.08174,'9/14/2014 0:10','SW'); -- 新しく挿入されたデータをクエリします。 SELECT * FROM mc_oss_parquet_data_type_zstd WHERE dt = '20230418' AND recordid=16;結果:
+------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | dt | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+ | 1 | 16 | 76 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:10 | SW | 20230418 | +------------+------------+------------+------------+------------------+-------------------+----------------+------------+------------+
よくある質問
Parquet ファイルの列の型が外部テーブルの DDL の型と一致しない
エラーメッセージ
ODPS-0123131:User defined function exception - Traceback: java.lang.ClassCastException: org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.io.IntWritable at org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableIntObjectInspector.getPrimitiveJavaObject(WritableIntObjectInspector.java:46)エラーの説明
Parquet ファイルは LongWritable を使用していますが、外部テーブルの DDL は列を INT として定義しています。
解決策
外部テーブルの DDL で列の型を INT から BIGINT に変更します。
外部テーブルへの書き込み時のメモリ不足エラーjava.lang.OutOfMemoryError
エラーメッセージ
ODPS-0123131:User defined function exception - Traceback: java.lang.OutOfMemoryError: Java heap space at java.io.ByteArrayOutputStream.<init>(ByteArrayOutputStream.java:77) at org.apache.parquet.bytes.BytesInput$BAOS.<init>(BytesInput.java:175) at org.apache.parquet.bytes.BytesInput$BAOS.<init>(BytesInput.java:173) at org.apache.parquet.bytes.BytesInput.toByteArray(BytesInput.java:161)エラーの説明
大量のデータを Parquet 外部テーブルに書き込む際に OutOfMemoryError が発生します。
解決策
外部テーブルを作成する際に、まず
mcfed.parquet.block.row.count.limitを減らします。OOM が解消されない場合や出力ファイルが大きすぎる場合は、mcfed.parquet.page.size.row.check.maxを減らしてメモリをより頻繁にチェックします。詳細については、「固有パラメーター」をご参照ください。Parquet 外部テーブルに書き込む前に、これらの設定を追加します:
-- UDF の最大 JVM ヒープメモリを設定します。 SET odps.sql.udf.jvm.memory=12288; -- ランタイム側でバッチサイズを制御します。 SET odps.sql.executionengine.batch.rowcount =64; -- Map Worker ごとのメモリサイズを設定します。 SET odps.stage.mapper.mem=12288; -- Map Worker ごとの入力データサイズ (ファイル分割サイズ) を調整して、Map ステージごとの Worker 数を制御します。 SET odps.stage.mapper.split.size=64;