ハッシュクラスタリングでは、テーブルデータを書き込み時にハッシュディストリビューションおよびソートに基づいて格納するため、MaxCompute はクエリ実行時にシャッフルおよびソート操作をスキップできます。これにより、反復的な結合または集約パターンが頻繁に発生する大規模テーブルにおいて、CPU 時間、ジョブの持続時間、およびストレージ使用量を削減できます。
ハッシュクラスタリングを使用する場合
以下のすべての条件を満たす場合に、ハッシュクラスタリングの効果が最も高くなります。
テーブルに大量のデータが含まれている
クエリで同一のカラムに対して頻繁にフィルター処理、結合、または集約が実行される
同一の結合または集約パターンがテーブルに対して繰り返し実行される
テーブルのライフサイクルが長く、ストレージ削減のメリットが大きい
テーブルに対するクエリで多様かつ予測不可能なアクセスパターンが用いられる場合、ハッシュクラスタリングによる効果は限定的です。
仕組み
多くのシナリオにおいて、テーブルの結合が必要になります。MaxCompute では、以下の結合方法が提供されています。
ブロードキャストハッシュ結合:結合対象のテーブルのうち一方が小規模テーブルである場合、MaxCompute はその小規模テーブルをすべての結合タスクインスタンスにブロードキャストし、小規模テーブルと大規模テーブルとの間でハッシュ結合を実行します。
シャッフルハッシュ結合:両方のテーブルが大規模である場合、結合キーに基づいて両テーブルに対してハッシュシャッフルが実行されます。同一のキー値を持つレコードは、同じ結合タスクインスタンスに配信され、そこで結合が実行されます。
ソートマージ結合:両方のテーブルが非常に大規模であり(ハッシュテーブルをメモリ上に保持する容量が不足)、ソートマージ結合が選択された場合、MaxCompute は結合キーに基づいて両テーブルに対してハッシュシャッフルを実行した後、結果をソートしてマージします。M 個のマッパーと R 個のリデューサーから構成されるジョブでは、この処理により M × R 回の I/O 操作が発生します。これは MaxCompute における最も一般的な結合方法です。
ソートマージ結合を実行する Fuxi ジョブの物理実行計画では、2 つのマップステージと 1 つの結合ステージが必要です。下記にシャッフルおよびソート操作をハイライト表示しています。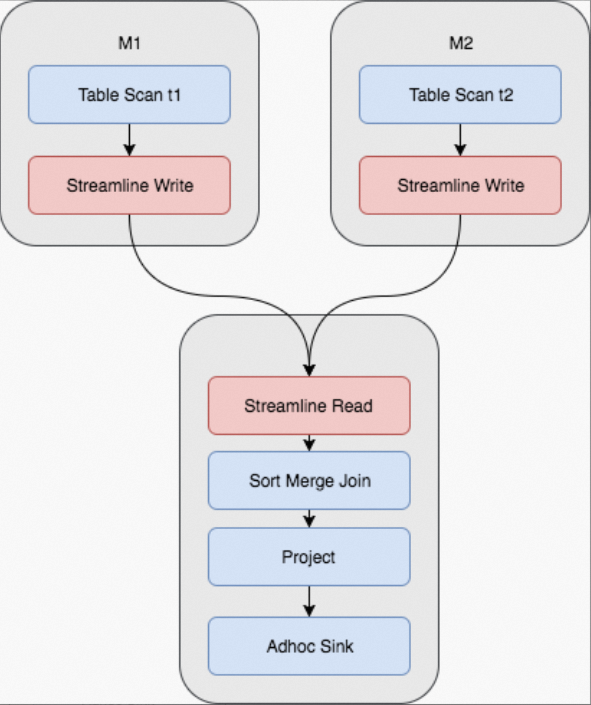
ハッシュクラスタリングを適用すると、データは書き込み時にハッシュ値に基づいてバケットに分散され、各バケット内で事前にソートされます。その後、クラスターキーを用いた結合またはフィルター処理を行うクエリでは、シャッフルおよびソート操作を完全にスキップでき、マルチステージの Fuxi ジョブを単一ステージに簡略化できます。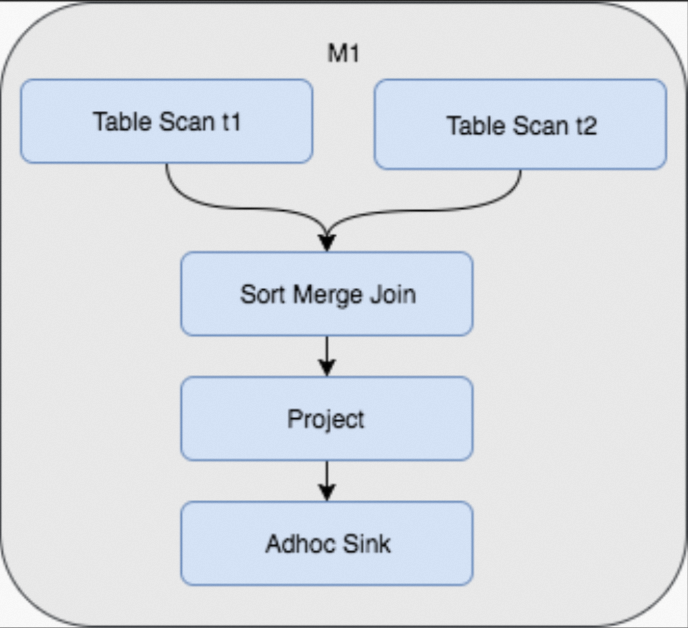
具体的には、以下の 3 つの最適化が適用されます。
バケットプルーニングおよびインデックス検索:クラスターキーを WHERE 句で指定したクエリでは、全バケットではなく該当するバケットのみを読み込みます。また、SORTED BY が設定されている場合、MaxCompute は自動的にインデックスを構築し、ページ単位でのインデックス検索により該当レコードを高速に特定できます。例えば、427 億件のデータから 26 件を抽出するクエリでは、全データをスキャンする 1,111 個のマッパーから、10,000 件のデータをスキャンする 4 個のマッパーへと削減でき、ランタイムを 1 分 48 秒から 6 秒へと短縮できます。
集約最適化:クラスターキーを用いた GROUP BY クエリでは、シャッフルおよびソートをスキップし、MaxCompute はあらかじめソート済みのデータに対してストリーム集約を直接実行します。
ストレージ最適化:MaxCompute のストレージレイヤーでは列のストアが採用されています。類似したキー値を持つレコードが隣接して格納されるため、ソート済みデータは非ソートデータと比較して圧縮率が大幅に向上します。実際の運用では、ハッシュクラスタリングを適用した同一データセットは、ストレージ使用量を約 10 % 削減できます。極端なケースでは、最大で 50 % の削減が可能です。
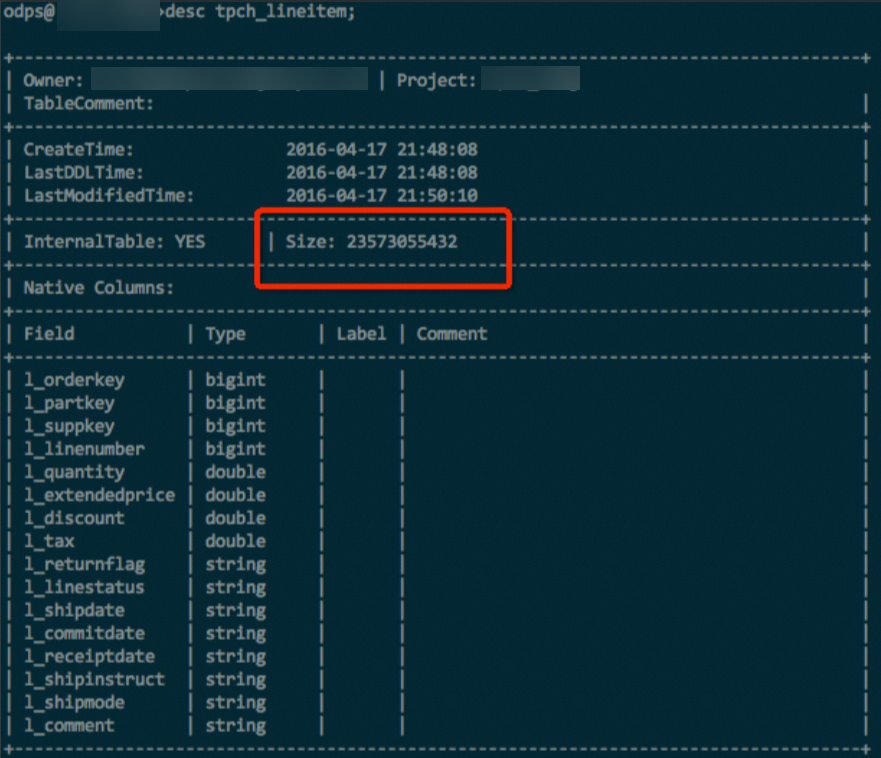
ハッシュクラスタリング未使用時。
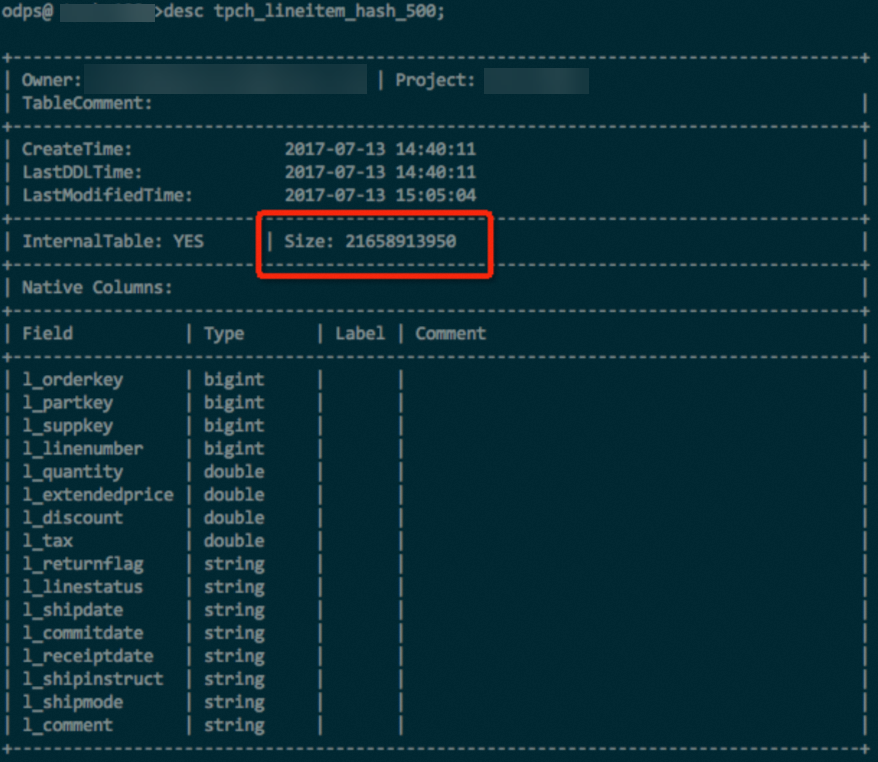
ハッシュクラスタリング使用時。
TPC-H ベンチマーク結果:500 個のバケットに分割された 1 TB のデータを対象とした評価では、ハッシュクラスタリングにより総 CPU 時間が約 17.3 %、総ジョブ持続時間が約 12.8 % 各々削減されました。特にクラスタリングを有効活用したクエリ(TPC-H Q4、Q12、Q10)では、それぞれ 68 %、62 %、47 % の性能向上が確認されています。
以下は、一般テーブルを対象とした TPC-H Q4 クエリの Fuxi ジョブ実行計画を示す図です。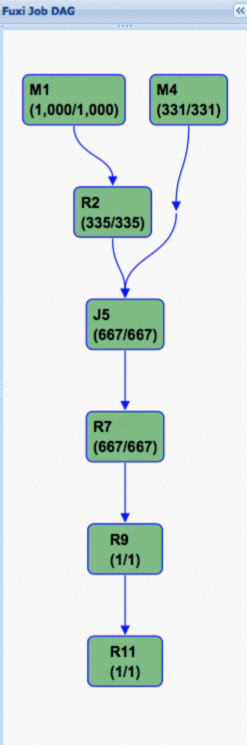 以下は、ハッシュクラスタリングを有効化後の実行計画です。有向非循環グラフ(DAG)が大幅に簡略化されており、これがパフォーマンス向上の鍵となります。
以下は、ハッシュクラスタリングを有効化後の実行計画です。有向非循環グラフ(DAG)が大幅に簡略化されており、これがパフォーマンス向上の鍵となります。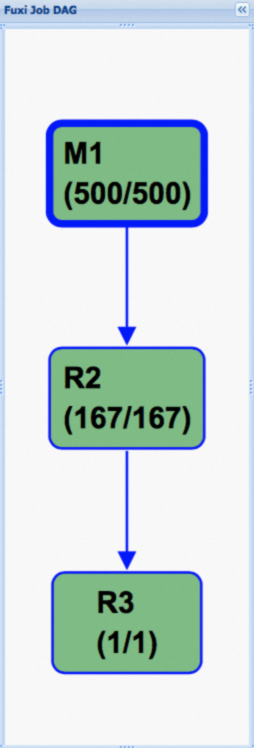
ハッシュクラスター化テーブルの作成
構文
CREATE TABLE [IF NOT EXISTS] <table_name>
[(<col_name> <data_type> [COMMENT <col_comment>], ...)]
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type> [COMMENT <col_comment>], ...)]
[CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS] [AS <select_statement>]パラメーター
`CLUSTERED BY`(必須)
クラスターキー(MaxCompute がデータをバケットにハッシュ分散するために使用するカラム)を指定します。データスキューおよびホットスポットを防止し、同時実行効率を向上させるため、値の範囲が広く重複が少ないカラムを選択してください。結合操作の最適化を目的とする場合は、よく使用される結合キーまたは集約キーを指定します。
`SORTED BY`(任意)
各バケット内のソート順序を指定します。CLUSTERED BY と同じカラムを指定することで、インデックス検索を有効化し、範囲検索および等価検索のクエリパフォーマンスを向上させることができます。また、SORTED BY を指定すると、MaxCompute は自動的にインデックスを生成します。
`INTO <number_of_buckets> BUCKETS`(必須)
バケット数を指定します。データ量に応じて適切な値を決定してください。
各バケットのサイズを 500 MB ~ 1 GB を目安としてください。
非常に大規模なテーブルの場合、バケットサイズの目標値を増加させることも可能です。
MaxCompute がバケットの分割およびマージを自動的に実行できるよう、バケット数は 2 の累乗(例:512、1,024、2,048、4,096)に設定することを推奨します。
2 つのテーブル間の結合最適化を目的とする場合、片方のテーブルのバケット数は、もう片方のテーブルのバケット数の整数倍となるように設定してください(例:256 と 512)。
例
非パーティション化テーブル:
CREATE TABLE T1 (a string, b string, c bigint)
CLUSTERED BY (c)
SORTED BY (c) INTO 1024 BUCKETS;パーティションテーブル:
CREATE TABLE T1 (a string, b string, c bigint)
PARTITIONED BY (dt string)
CLUSTERED BY (c)
SORTED BY (c) INTO 1024 BUCKETS;テーブルのクラスタリングプロパティの変更
パーティションテーブルの場合、ALTER TABLE を使用してハッシュクラスタリングプロパティを追加または削除できます。
-- 既存のパーティションテーブルにハッシュクラスタリングを追加
ALTER TABLE <table_name> [CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS];
-- パーティションテーブルからハッシュクラスタリングを削除
ALTER TABLE <table_name> NOT CLUSTERED;注意事項
ALTER TABLEはパーティションテーブルのみに適用可能です。非パーティション化テーブルのクラスタリングプロパティは、一度設定後に変更できません。ALTER TABLEは新規パーティション(INSERT OVERWRITEで書き込まれるパーティションを含む)にのみ影響します。既存のパーティションは、元のストレージフォーマットのまま保持されます。ALTER TABLE文では、特定のパーティションを対象とすることはできません。
ハッシュクラスタリングプロパティの確認
ハッシュクラスター化テーブルを作成した後は、DESC EXTENDED を実行してクラスタリングプロパティを確認してください。出力の Extended Info 内にハッシュクラスタリングの構成が表示されます。
DESC EXTENDED <table_name>;以下は、返された結果の例を示す図です。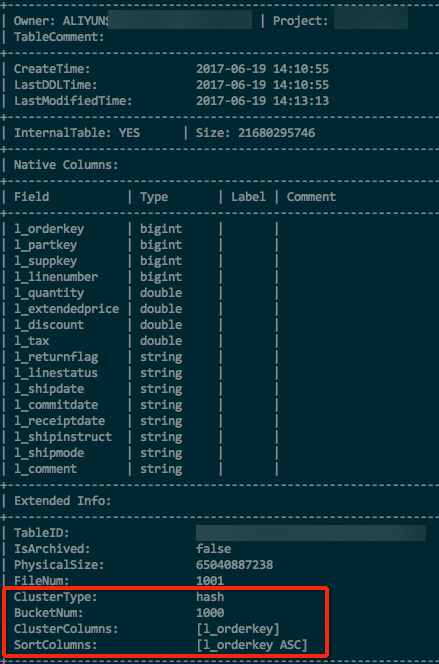
パーティションテーブルの場合、特定のパーティションについても確認できます。
DESC EXTENDED <table_name> PARTITION (<pt_spec>);以下は、返された結果の例を示す図です。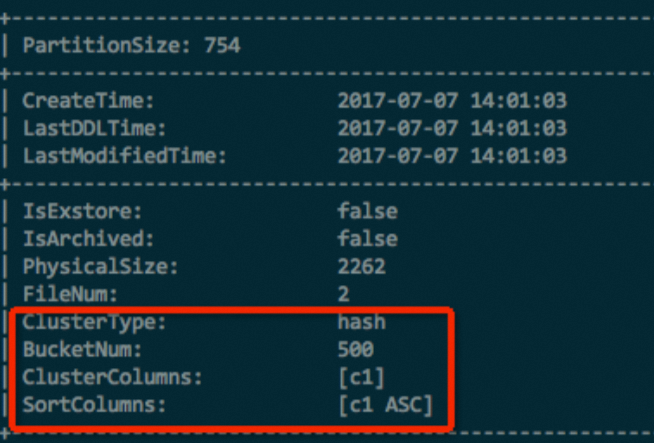
ストレージ最適化の詳細
TPC-H データセットから取得した 100 GB の lineitem テーブルを用いて、簡単な実験を行いました。このテーブルには、INT、DOUBLE、STRING など、さまざまなデータ型が含まれています。同一のデータおよび同一の圧縮方式を用いた場合、ハッシュクラスター化テーブルはストレージ使用量を約 10 % 削減しました。一部の極端なテストケースでは、ソート済みテーブルは非ソートテーブルと比較して最大で 50 % のストレージ使用量削減が達成できました。
次のステップ
パーティションテーブル — MaxCompute でテーブルパーティションを管理する
クエリのパフォーマンスを最適化する — クエリ効率を向上させるための追加手法