Proxima CE に関するよくある質問です。
結果の品質
指定した件数よりも取得結果が少ないのはなぜですか?
Proxima CE では、デフォルトで HNSW(Hierarchical Navigable Small World)アルゴリズムを使用してインデックスを構築します。HNSW は近似最近傍検索アルゴリズムであり、完全な再現率(recall)を犠牲にして高速な検索を実現します。グラフ内のオブジェクトが完全に接続されていない場合、要求された上位 K 件の結果をすべて取得できないことがあります。
以下の対応策があります(侵襲度の低い順):
取得率の調整。 取得率のしきい値を低下させても、この問題を完全に解決できません。グラフに接続性のギャップがある場合、どのような取得率設定でも厳密な上位 K 件の取得を保証できません。また、しきい値の変更は他のクエリにも影響を与える可能性があるため、適用前に影響範囲を評価してください。
インデックスアルゴリズムの変更。
-algo_modelパラメーターを指定し、インデックス作成アルゴリズムとして HC(Hierarchical Clustering)を使用するように設定します。結果のパディング機能の有効化(Proxima 2.4 以降)。 構成に
{"proxima.hnsw.searcher.force_padding_result_enable" : True}を追加します。この設定により、利用可能な検索結果に基づいて結果を上位 K 件にパディングします。ただし、エッジケースではパディングされた結果の類似度スコアが低くなる可能性があるため、本番環境への適用前には業務要件との整合性を確認してください。
Proxima CE で余弦距離(cosine distance)を設定できますか?
はい。Proxima CE は余弦距離をサポートしており、内積(inner-product)検索を最適化します。詳細については、「内積と余弦距離」をご参照ください。
パフォーマンス
Proxima CE はどのようなリソースを使用しますか?
Proxima CE は、ご利用のアカウントが所属する MaxCompute プロジェクトのリソースを使用します。
-column_num および -row_num パラメーターをどのように設定しますか?
Proxima CE は分散型エンジンであり、MaxCompute MapReduce と連携して、大規模なベクトルデータをオフラインモードで処理します。
ビルドプロセス: ドキュメントテーブル(doc table)は列単位で分割され、各列に対して個別のインデックスが作成されます。列数を増やすと、各列のインデックスサイズが小さくなり、単一列での検索速度が向上しますが、クラスターリソースの消費量も増加します。
シークプロセス: クエリーテーブル(query table)は行単位で分割され、各行がより少ないクエリを処理します。行数を増やすと、シークプロセスが高速化しますが、クラスターリソースの消費量も増加します。
留意すべき制約事項:
クラスターリソースの上限。 MaxCompute プロジェクトの所有者に連絡し、クラスターリソース使用量のデフォルト上限を確認してください。
MapReduce インスタンス数の上限。 MaxCompute MapReduce では、reduce タスクの最大インスタンス数は 99,999 です。ビルドプロセスでは、インスタンス数は
column_numと等しくなります。シークプロセスでは、インスタンス数はcolumn_num × row_numと等しくなります。この積は 99,999 を下回るように設定してください。
まず、Proxima CE が入力パラメーターから自動計算する行数および列数の値をベースとして開始してください。これにより、正常な動作が保証されます。「マルチカテゴリ検索」で自動計算の詳細をご確認ください。
このベースラインから必要に応じて調整してください:
クエリ速度が遅すぎる場合は、行数または列数を増加させます。
クラスターリソースが不足している場合は、行数または列数を減少させます。
一般的なチューニング原則については、「タスクの高速化方法」をご参照ください。
タスクの高速化方法
複数カテゴリシナリオには 2 つのカテゴリサイズがあります:
小規模カテゴリ(デフォルトで 100 万件未満、設定可能):線形検索(linear search)を使用します。
-category_row_numおよび-category_col_numでチューニングします。大規模カテゴリ(100 万件以上):
-row_numおよび-column_numでチューニングします。
いずれの場合も、基本的な原則は同じです。列数を増やすと各列のインデックスサイズが小さくなり、単一列での検索が高速化します。行数を増やすと各行が処理するクエリ数が減り、各バッチの処理が高速化します。ただし、どちらもクラスターリソースの消費量を増加させるため、利用可能なリソース容量とのバランスを考慮してチューニングしてください。パラメーターの詳細については、「マルチカテゴリ検索」をご参照ください。
マルチカテゴリ以外のシナリオ: タスク全体の同時実行数を高めるために、-row_num および -column_num を増加させます。
Proxima CE のタスクが遅く実行されるのはなぜですか?
Proxima CE のタスクは MaxCompute MapReduce ジョブとして実行されます。タスクがコンパイルおよび実行エラーなく完了した場合、遅延の原因は MaxCompute のスケジューリングまたはリソース不足である可能性が高いです。技術サポートチームへお問い合わせいただくには、MaxCompute 開発者コミュニティの DingTalk グループ(グループ ID:11782920)へご参加ください。
ログに ERROR: KILLED エラーが表示されるのはなぜですか?
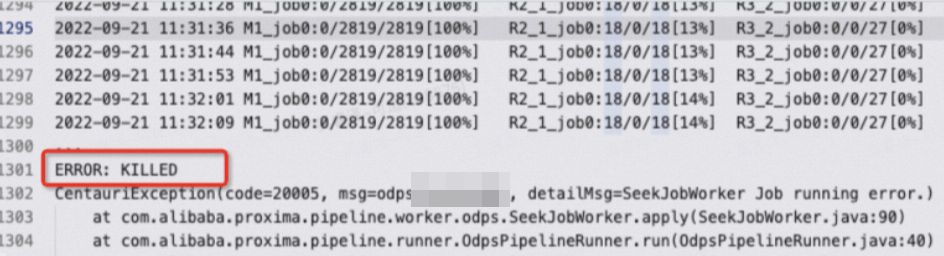
タスクが終了される主な理由は以下の 3 つです:
実行時間が 24 時間を超えた。 MaxCompute では、24 時間を超えて実行中の SQL タスクを自動的に終了します。上限時間を最大 72 時間に延長するには、以下を実行します:
set odps.sql.job.max.time.hours=72;クラスターが過負荷状態。 リソースが長期間プリエンプト(強制割り当て)されたため、タスクが終了しました。クラスターの負荷が低下したタイミングでタスクを再実行するか、
-odps_task_priorityを使用してタスクの優先度を引き上げてください。詳細については、「オプションパラメーター」をご参照ください。重要タスクの優先度を引き上げると、他の高優先度ジョブからリソースがプリエンプトされる可能性があります。この設定を適用する前に、プロジェクトの所有者と連携し、クラスター内で重要なオンラインまたはオフラインタスクが実行中でないことを確認してください。
手動で終了された。 プロジェクトの所有者または管理者に確認し、誰かが意図的にタスクを終了したかどうかを特定してください。
ほとんどの場合、タスクが終了された場合でも再実行可能です。クラスターが過負荷状態の場合は、高優先度タスクによるリソース使用量が低下した後に Proxima CE タスクを再実行してください。
-odps_task_priority パラメーターが有効にならないのはなぜですか?
プロジェクトにベースライン優先度が設定されている場合、指定した優先度がそのベースラインを超えると、-odps_task_priority は無効になります。ベースライン管理については、「ベースラインの管理」をご参照ください。
オフラインタスクがオンラインタスクに影響するのはなぜですか?
最も一般的な原因は、オフラインタスクとオンラインタスクが同一のクラスターを共有していることです。オフラインタスクが大量のクラスターリソースを消費すると、オンラインタスクに必要なリソースが不足し、実行が遅くなったり失敗したりする可能性があります。
この問題を解決するには、以下の対応策をご検討ください:
オフラインタスクの同時実行数を制限。 Proxima CE のオフラインタスクにおける行数および列数を削減するか、MaxCompute コンソールで MaxCompute プロジェクトのリソース制限を設定してください。
実行ウィンドウを分離。 オフラインタスクとオンラインタスクを異なる時間帯にスケジュールするか、新たなリソースの申請をご検討ください。
データ型とベクトル
入力テーブルのベクトルは BINARY 型で指定できますか?
いいえ。ドキュメントテーブル(doc table)のベクトル列は、デフォルトで STRING 型のみをサポートしており、BINARY 型は直接サポートされていません。
Proxima CE では、-binary_to_int パラメーターを使用して、インデックス作成前に BINARY データを INT 型に変換できます。カンマ区切りの入力データを使用する場合:
-binary_to_int=false:入力データはそのまま保持されます(例:1,1,1,1,1,1,...)。-binary_to_int=true:入力データが変換されます(例:12345,13423,13325,...)。
この変換では、N 個のバイナリ値(各値は 0 または 1)を N 個の 32 ビット整数にパックすることで、生成されるインデックスのサイズを削減します。
エラーと命名規則
invalid table name: xxx.yyy エラーで一時テーブルの作成に失敗するのはなぜですか?
テーブル名にピリオド(.)が含まれているためです。MaxCompute では、ピリオドは project.table 形式における名前空間の区切り文字として予約されています。そのため、ピリオドを含むテーブル名は無効となり、後続の処理が失敗します。これは、出力テーブル名を xxx.output_table_name のような形式で指定した場合に発生しやすいです。
入力テーブルおよび出力テーブルの名前から、すべてのピリオドを削除してください。
同一のドキュメントテーブルに対して複数のタスクを同時に実行できますか?
いいえ。同一のドキュメントテーブルに対して並列でタスクを実行すると、インデックスの上書きが発生します。たとえば、タスク B のインデックスが、タスク A の実行中に上書きされる可能性があります。これにより、以下のエラーが発生します:
OSS ボリュームファイルシステムのエラー
ビルドプロセス中の JNI(Java Native Interface)ベースのインデックス書き込み失敗
シークプロセス中の JNI ベースのインデックス読み込み失敗
これらの競合を回避するため、同一のドキュメントテーブルに対するタスクは逐次的に実行してください。
ログ
実行ログと Logview の違いは何ですか?
実行ログ は、DataWorks ノードが実行された後に生成される出力です。トラブルシューティングのために、実行ログの内容をコピーしてテクニカルサポートへお送りください。MaxCompute クライアント(odpscmd)をご利用の場合、クライアント内でも実行ログを確認できます。共有前に、クライアントの全出力をコピーするか、ログファイルへリダイレクトしてください。
Logview は、MaxCompute ジョブの可視化デバッグツールです。Proxima CE タスクを送信した後、Logview を使用して、MaxCompute 上で実行中の SQL ジョブ、MapReduce ジョブ、Graph ジョブのリアルタイムステータスを確認できます。詳細については、「Logview を使用したジョブ情報の表示」をご参照ください。