越境データ転送に関するコンプライアンス声明
XCOPY を使用して越境データ転送を行う場合、関連するリージョンのすべての適用法規を遵守する必要があります。
この機能は、お客様のビジネスデータを、お客様が選択したリージョンまたはプロダクトがデプロイされているリージョンに転送します。これには越境データ転送が含まれる場合があります。お客様は、このビジネスデータに対する完全な権限を有し、その転送について単独で責任を負うことに同意し、確認するものとします。
お客様は、データ転送がすべての適用法規に準拠していることを保証する必要があります。これには、適切なデータセキュリティ技術とポリシーの実装、個人からの十分な明示的同意の取得、データ輸出セキュリティ評価と届出の完了などの法的義務の履行が含まれます。また、お客様は、ビジネスデータに適用法規で転送または開示が制限または禁止されているコンテンツが含まれていないことを保証するものとします。
前述の声明および保証を遵守しない場合、お客様は相応の法的結果を負うことになります。お客様の不遵守により Alibaba Cloud またはその関連会社が被ったいかなる損失についても、お客様が責任を負うものとします。
特長
クロスリージョンレプリケーション (XCOPY) 機能は、テーブルスナップショットの増分レプリケーションをサポートします。クロスリージョンでのデータバックアップ、移行、共有などのシナリオに最適です。
ファイルレベルの増分レプリケーションを使用して、列圧縮されたバイナリデータファイルをコピーします。これにより、転送効率、コスト削減、データ整合性のバランスが取れます。
レプリケーションはテーブルスナップショットに基づいています。レプリケートされたデータはソーステーブルから分離されているため、バックアップのライフサイクルを独立して管理できます。
テーブルスナップショットのレプリカは、ポイントインタイムリカバリ (PITR) のための明確なポイントを提供し、アップストリームのデータソースから最近失われたデータを復元できます。
増分レプリケーションはパーティションレベルで実行されます。同じテーブルの 2 つのスナップショット間でレプリケーションを行う場合、差分パーティションのみがコピーされます。重複するパーティションは自動的にスキップされ、冗長なレプリケーションを回避します。
課金:詳細については、「クロスリージョンデータレプリケーション料金」をご参照ください。
範囲と制限
サポート対象リージョン:中国 (香港)、シンガポール、日本 (東京)。
クロスリージョン帯域幅:初期帯域幅は 10 Gbps で、必要に応じて調整できます。
ターゲットオブジェクト:テーブルスナップショット。
テーブルスナップショットは、標準テーブル (パーティション化テーブル、非パーティション化テーブル、クラスター化テーブルを含む) および PK/Append Delta テーブルでサポートされています。トランザクションテーブルではサポートされていません。
XCOPY タスクの制限:
1 つのプロジェクト内で同時に実行できる XCOPY スナップショットタスクは最大 128 個です。この制限を超えると、後続のタスクのサブミットは失敗します。
権限要件:
ソースプロジェクトと送信先プロジェクトは、同じプライマリアカウントに属している必要があります。
ソースプロジェクトのソーステーブルスナップショットに対する
SELECT権限が必要です。送信先プロジェクトでの
CREATE TABLE権限が必要です。
バックアップリージョンのバックアッププロジェクトは、バックアップデータの保存と一時的なクエリの実行にのみ使用することを推奨します。バックアップリージョンで本番ワークロードを実行する必要がある場合は、別のプロジェクトを作成してください。
XCOPY の有効化
手順
バックアップしたいプロジェクトの名前を記載して、チケットをサブミットします。
コンソールで XCOPY チャンネルスイッチを有効にします。
ソースリージョンで、XCOPYチャンネルスイッチ を有効にして、許可されたユーザーが XCOPY を使用して他のリージョンにデータをコピーできるようにします。
MaxCompute コンソールにログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
テナント管理 ページで、テナントプロパティ タブをクリックします。
XCOPY コマンドリファレンス
構文
XCOPY SNAPSHOT <src_remote_project_name>.<src_remote_snapshot_name>
TO SNAPSHOT [<dest_local_project_name>.]<dest_local_snapshot_name>
OPTIONS(src_region=<region_name>); パラメーター
src_remote_project_name:ソースプロジェクトの名前を指定します。
src_remote_snapshot_name:ソースプロジェクトのテーブルスナップショットの名前を指定します。
dest_local_project_name:送信先プロジェクトの名前を指定します。このパラメーターはオプションです。
dest_local_snapshot_name:送信先プロジェクトで作成または上書きするテーブルスナップショットの名前を指定します。
region_name:ソースリージョンの名前を指定します。例:中国 (香港) の場合は `cn-hongkong`、日本 (東京) の場合は `ap-northeast-1` です。詳細については、「リージョン名」をご参照ください。
例
この例では、次の図に示すように、プライマリリージョンであるシンガポール (SGP) からバックアップリージョンである中国 (香港) (HK) へのディザスタリカバリバックアップを示します。
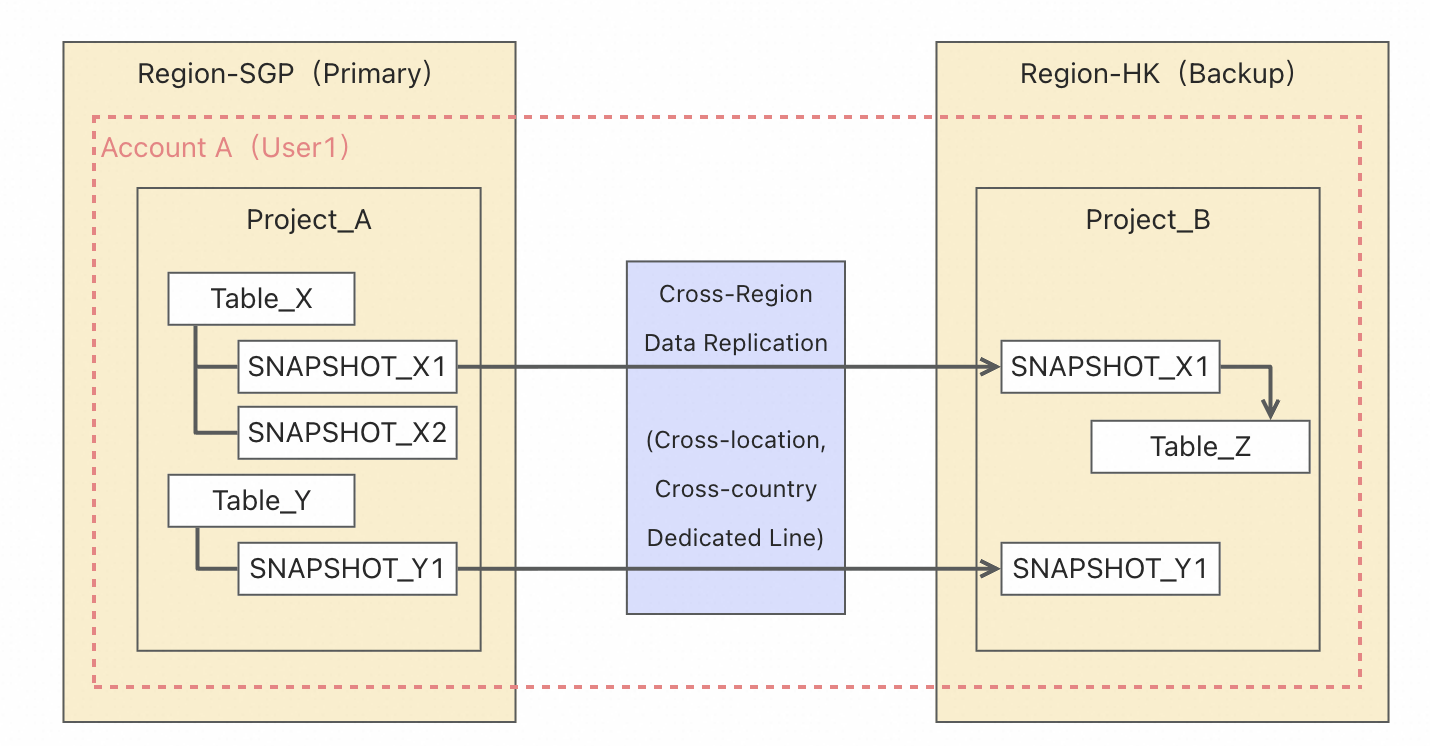
バックアップフェーズ
プライマリリージョン (シンガポール):`Account A (User1)` の `Project_A` で、ソーステーブル `Table_X` と `Table_Y` に対して、それぞれスナップショット `SNAPSHOT_X1`/`X2` と `SNAPSHOT_Y1` を作成します。
-- バックアップフェーズ -- ユーザーがシンガポールリージョン (Region-SGP) でスナップショットを作成します。 CREATE SNAPSHOT TABLE Project_A.table_x_snapshot_20260101 CLONE Project_A.table_x;クロスリージョンレプリケーションフェーズ
XCOPY は、専用のクロスリージョン、クロスボーダー接続を介して、プライマリリージョンからバックアップリージョンにスナップショットデータをレプリケートします。
-- ユーザーが Region-SGP で作成したスナップショットを中国 (香港) リージョン (Region-HK) にコピーします。 XCOPY SNAPSHOT Project_A.table_x_snapshot_20260101 TO SNAPSHOT Project_B.table_x_snapshot_20260101 OPTIONS( src_region =” ap-southeast-1”);リカバリフェーズ
バックアップリージョン (中国 (香港)):`Project_B` はレプリケートされたスナップショットを受信します。その後、スナップショットを `Table_Z` などのターゲットテーブルに復元できます。
-- リカバリフェーズ -- ユーザーが Region-HK のバックアップデータに対して一時的なクエリを実行します。 SELECT * FROM Project_B.table_x_snapshot_20260101; -- ユーザーが Region-HK でデータを復元します。 CREATE TABLE table_x CLONE table_x_snapshot_20260101;
日次クロスリージョンテーブルバックアップ
ステップ 1:プライマリリージョンでのスナップショットの作成
DataWorks 開発環境への移動
DataWorks コンソールにログインし、左上のコーナーでリージョンを選択します。
左側のナビゲーションウィンドウで、ワークスペース をクリックします。
「ワークスペースを選択する」セクションで、「[DataStudio へ移動]」をクリックします。。
MaxCompute SQL ノードの作成
ノード名:create_daily_snapshots
ノードの説明:テーブルの日次スナップショットを作成します。
SQL スクリプトの記述
-- このスクリプトは、テーブル 'a' と 'b' の日次スナップショットを作成します。変数 ${var1} と ${var2} は現在の日付のプレースホルダーであり、DataWorks のスケジューリングプロパティで設定されます。 CREATE SNAPSHOT TABLE a_snapshot_${var1} CLONE a; CREATE SNAPSHOT TABLE b_snapshot_${var2} CLONE b;スケジューリングプロパティの設定
ノードエディターの右上隅にある [スケジューリング設定] をクリックします。表示されるパネルで、[スケジューリング時間] をクリックし、プロパティを次のように設定します。
パラメーター
値の例
スケジューリング周期
日次
スケジューリング時間
01:00
有効日
無期限
指定時間:2026-01-01 から 9999-12-31 (長期間)
ステップ 2:バックアップリージョンへのスナップショットの XCOPY
DataWorks 開発環境への移動
DataWorks コンソールにログインし、左上のコーナーでリージョンを選択します。
左側のナビゲーションウィンドウで、ワークスペース をクリックします。
ワークスペースを選択する セクションで、[DataStudio へ移動] をクリックします。
MaxCompute SQL ノードの作成
ノード名:create_daily_snapshots
ノードの説明:テーブルの日次スナップショットを作成します。
SQL スクリプトの記述
-- このスクリプトは XCOPY を使用して、ソースリージョンで作成された日次スナップショットをレプリケートします。 XCOPY SNAPSHOT src_project.a_snapshot_$[yyyymmdd] TO SNAPSHOT a_snapshot_$[yyyymmdd] options(src_region="cn-hongkong"); XCOPY SNAPSHOT src_project.b_snapshot_$[yyyymmdd] TO SNAPSHOT b_snapshot_$[yyyymmdd] options(src_region="cn-hongkong");スケジューリングプロパティの設定
ノードエディターの右上隅にある [スケジューリング設定] をクリックします。表示されるパネルで、[スケジューリング時間] をクリックし、プロパティを次のように設定します。
パラメーター
値の例
スケジューリング周期
日次
スケジューリング時間
02:00
有効日
無期限
指定時間:2026-01-01 から 9999-12-31 (長期間)
ステップ 3:スナップショットの整合性の検証
テナントレベルの Information Schema を確認して、すべてのスナップショットがバックアップリージョンに正常にレプリケートされたことを検証します。
バックアップリージョンで次のコードを実行して、特定の日付にバックアップリージョンにレプリケートされたスナップショットをカウントします。
SET odps.namespace.schema=true; SELECT * FROM SYSTEM_CATALOG.INFORMATION_SCHEMA.tables WHERE table_catalog = <dest_project> AND table_type = 'SNAPSHOT_TABLE' AND table_name LIKE "%_snapshot_20260101";サンプルデータ検証の実行 (オプション)
プライマリリージョンとバックアップリージョンの両方でスナップショットの統計情報と MD5 チェックサムを計算して、データ整合性を検証します。
-- count、sum、distinct、min、max を使用して統計情報を比較します。 -- 詳細な比較を行うには、テーブルを 1,000 個のバケットに分割します。各バケット内のすべての行の MD5 ハッシュの合計が同一であることを確認します。 -- 各行の MD5 ハッシュは、そのすべての列の値を単一の文字列に連結することによって計算されます。 WITH table_hashs AS ( SELECT COUNT(1) row_count, MD5( SUM( MD5( CONCAT_WS('|', <column_name_1>, <column_name_n>) ) ) ) AS bucket_hash FROM <snapshot_name> GROUP BY HASH(<column_name_1>) % 1000 ) SELECT SUM(row_count) AS row_count, MD5(WM_CONCAT(',', bucket_hash ) WITHIN GROUP (ORDER BY bucket_hash)) AS table_hash FROM table_hashs;