Simple Log ServiceでO&M操作を監視および実行する場合は、サービスログを照会および分析できます。 たとえば、サービスログを使用してLogtailのステータスと例外を監視し、コンシューマグループのレイテンシログとリソースの操作ログを表示できます。
背景情報
サービスログ機能を有効にすると、詳細ログ、重要ログ、ジョブ操作ログなどのログタイプを選択できます。 詳細は、「ログタイプ」をご参照ください。
詳細ログ: 詳細ログのサービスログ機能を有効にすると、選択したプロジェクトにinternal-operation_logという名前のLogstoreが作成され、現在のプロジェクトにダッシュボードが作成されます。
重要なログ: 重要なログのサービスログ機能を有効にすると、選択したプロジェクトにinternal-diagnostic_logという名前のLogstoreが作成されます。 Logstoreは、コンシューマーグループの消費遅延ログとLogtailハートビートログを保存するために使用されます。
ジョブ操作ログ: ジョブ操作ログのサービスログ機能を有効にすると、選択したプロジェクトにinternal-diagnostic_logという名前のLogstoreが作成されます。 Logstoreは、データインポート、スケジュールされたSQL、およびデータシッピングジョブのログを保存するために使用されます。
前提条件
サービスログ機能が有効になりました。 詳細については、「サービスログ機能の使用」をご参照ください。
Logtailのハートビートステータスを監視する
Logtailのステータスログの照会
internal-diagnostic_log Logstoreのクエリと分析ページで、次のステートメントを実行してLogtailのステータスログを照会します。 詳細については、「ログの照会と分析」をご参照ください。
__topic__: logtail_statusLogtailのステータスログを表示します。 ログのフィールドの詳細については、「Logtailステータスログ」をご参照ください。 サンプルログ:
{ "os_detail": "Windows Server 2012 R2", "__time__": 1645164875, "__topic__": "logtail_status", "memory": "25", "os": "Windows", "__source__": "log_service", "ip": "203.**.**.110", "cpu": "0.010405", "project": "aliyun-test-project", "version": "1.0.0.22", "uuid": "bf00****688b0", "hostname": "iZ1****Z", "instance_id": "5897****4735", "__pack_meta__": "0|MTYzNjM1Mzk5NDExMTcxOTQzNw==|1|0", "user_defined_id": "", "user": "SYSTEM", "detail_metric": "{\n\t\"config_count\" : \"1\",\n\t\"config_get_last_time\" : \"2022-02-18 14:14:23\",\n\t\"config_prefer_real_ip\" : \"false\"... "status": "ok" }
Logtailのハートビートステータスの監視
通常のLogtailハートビート接続の数を数える: internal-diagnostic_log Logstoreのクエリと分析ページで、次の図に示す手順に基づいて通常のLogtailハートビート接続の数を数えます。 次に、アラートルールを設定します。 詳細については、「ログの照会と分析」をご参照ください。
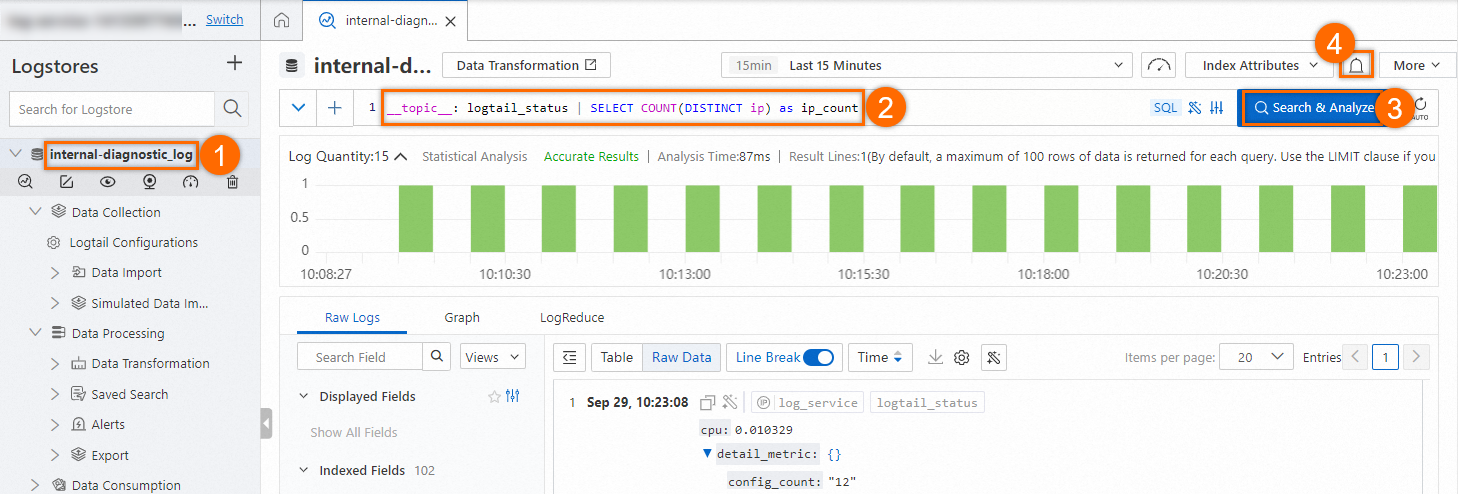
検索ステートメント:
__topic__: logtail_status | SELECT COUNT(DISTINCT ip) as ip_countアラートルールの設定: クエリと分析の結果で返された通常のハートビート接続の数が、Logtailにバインドされているすべてのマシングループのサーバーの数より少ない場合、アラートがトリガーされます。 次のアラートルールでは、[トリガー条件] パラメーターに100が指定されています。これは、サーバーの総数が100であることを示します。 アラートルールを設定する方法の詳細については、「Simple Log Serviceでアラートルールを設定する」をご参照ください。
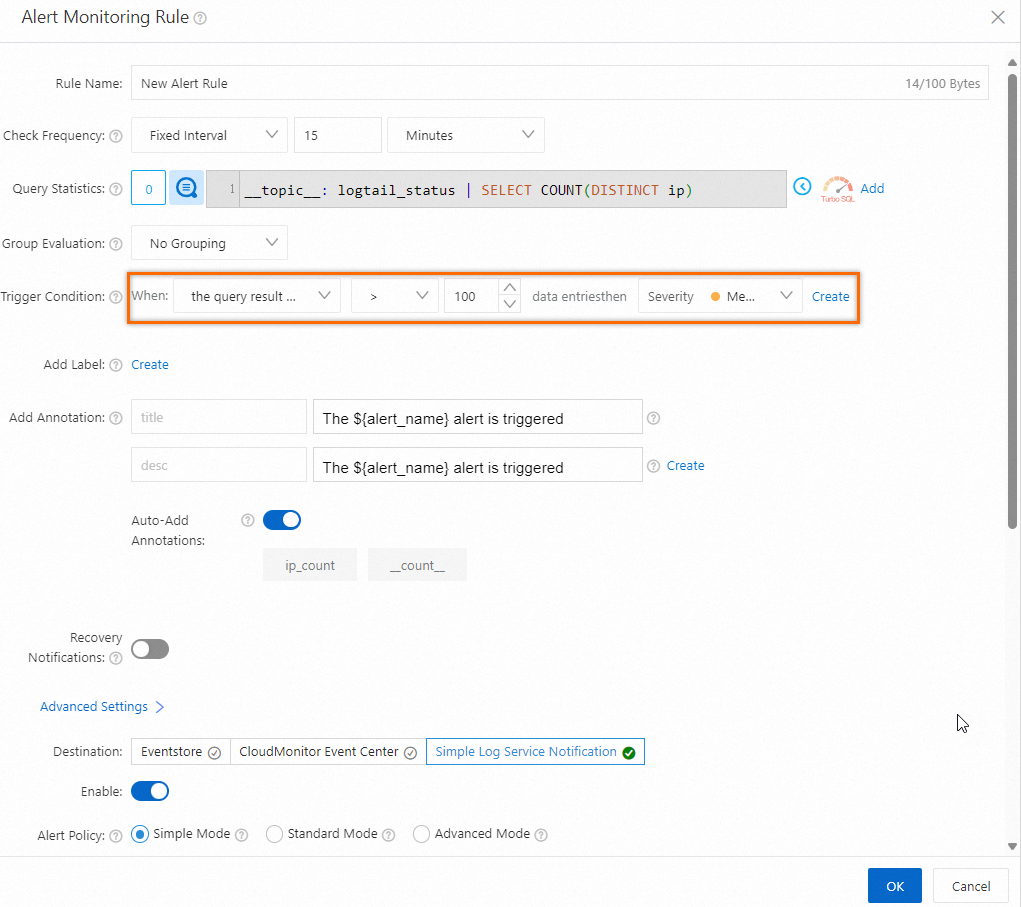
異常なハートビートステータスを持つサーバーの確認: アラートがトリガーされた場合、マシングループ内の特定のサーバーにはハートビート接続がありません。 Simple Log Serviceコンソールでマシングループのステータスを表示できます。 異常なハートビートステータスを引き起こすエラーのトラブルシューティング方法の詳細については、ホスト環境のLogtailマシングループに関連するエラーのトラブルシューティングを行うにはどうすればよいですか?
Logtail の例外のモニタリング
internal-diagnostic_log Logstoreのクエリと分析ページで、__topic __: logtail_alarmクエリステートメントを実行して、Logtailのアラートログをクエリします。 詳細については、「ログの照会と分析」および「Logtailアラートログ」をご参照ください。 アラートログは、できるだけ早い機会にLogtail例外を識別するのに役立ちます。 これにより、Logtail設定を変更してログの整合性を確保できます。 たとえば、次のステートメントを実行して、例外の種類ごとに15分間隔で例外が発生した回数を照会できます。
__topic__: logtail_alarm | select sum(alarm_count)as errorCount, alarm_type GROUP BY alarm_typeコンシューマーグループのレイテンシログの照会
サンプルログ
コンシューマーグループを使用してデータを消費する場合、コンシューマーグループのレイテンシーログに基づいて消費の進行状況を監視できます。 高いレイテンシが存在する場合は、できるだけ早い機会に消費者の数を変更して、消費速度を向上させることができます。 詳細については、「コンシューマーグループを使用したデータの消費」をご参照ください。 次のコードでは、コンシューマーグループの遅延ログのサンプルを示します。 ログ内のフィールドの詳細については、「コンシューマーグループの遅延ログ」をご参照ください。
{
"__time__": 1645166007,
"consumer_group": "consumerGroupX",
"__topic__": "consumergroup_log",
"__pack_meta__": "1|MTYzNjM1Mzk5NDExMTg5NjU2Mg==|3|0",
"__source__": "log_service",
"project": "aliyun-test-project",
"fallbehind": "9518678",
"shard": "1",
"logstore": "nginx-moni"
}コンシューマーグループのレイテンシログの照会
internal-diagnostic_log Logstoreのクエリと分析ページで、__topic __: consumergroup_logステートメントを実行して、コンシューマーグループのレイテンシログをクエリします。 詳細については、「ログの照会と分析」をご参照ください。 たとえば、次のステートメントを実行して、consumerGroupXという名前のコンシューマグループの消費レイテンシを照会できます。
__topic__: consumergroup_log and consumer_group: consumerGroupX | SELECT max_by(fallbehind, __time__) as fallbehindプロジェクト内のすべてのリソースの操作ログを照会する
サンプルログ
プロジェクトでリソースを作成、変更、更新、削除する操作とデータの読み取りおよび書き込み操作のログは、internal-operation_logという名前のLogstoreに保存されます。 ログには、コンソール、コンシューマグループ、SDKなど、すべてのクライアントから送信されたリクエストログが含まれます。 次のコードは、サンプル操作ログを提供します。 ログ内のフィールドの詳細については、「詳細ログ」をご参照ください。
{
"NetOutFlow": "1",
"InvokerUid": "1418****2562",
"CallerType": "Sts",
"InFlow": "0",
"SourceIP": "203.**.**.220",
"__pack_meta__": "0|MTYzNjM1Mzk5MzY1NDYwODQzMg==|2|1",
"RoleSessionName": "STS-ETL-WORKER",
"APIVersion": "0.6.0",
"UserAgent": "log-python-sdk-v-0.6.46, sys.version_info(major=3, minor=7, micro=3, releaselevel='final', serial=0), linux-consumergroup-etl-2bd3fdfdd63595d56b1ac24393bf5991",
"InputLines": "0",
"Status": "200",
"__time__": 1645167812,
"__topic__": "operation_log",
"NetInflow": "0",
"RequestId": "620F44C456458F67F72160A0",
"LogStore": "nginx-moni",
"__source__": "log_service",
"Method": "PullData",
"ClientIP": "203.**.**.330",
"Latency": "2191",
"Role": "aliyunlogetlrole",
"NetworkOut": "0",
"Project": "aliyun-test-project",
"AccessKeyId": "STS.NUE****1hm",
"Shard": "0"
}ユーザー情報の種類を次の表に示します。
タイプ | 項目 |
Alibaba Cloud アカウント |
|
RAM ユーザー |
|
Sts |
|
失敗したリクエストの数の照会
internal-operation_log Logstoreのクエリと分析ページで、次のステートメントを実行して、失敗したリクエストの数を照会します。 この例では、HTTPステータスコードが200を超えるリクエストは、失敗したリクエストと見なされます。 詳細については、「ログの照会と分析」をご参照ください。
Status > 200 | select count(*) as pv