標準の音声認識モデルは、日常会話の言語でトレーニングされています。 音声データに医療、法律、技術などのドメイン固有の用語が含まれている場合、モデルはそれらの用語を正確に認識できないことがあります。 カスタム言語モデルは、対象ドメインのテキストでトレーニングすることで、そのドメインの語彙とコンテキストを学習し、専門的なコンテンツの書き起こしの精度を向上させます。
このトピックでは、Intelligent Speech Interaction (ISI) コンソールでカスタム言語モデルを作成し、プロジェクトに適用する方法について説明します。
前提条件
開始する前に、次のことを確認してください。
Intelligent Speech Interaction が有効化されていること。 詳細については、「Intelligent Speech Interaction の有効化」をご参照ください。
カスタム言語モデルの作成は、すべての ISI の無料トライアルユーザーおよび商用版ユーザーに無料で提供されます。 各アカウントでサポートされるカスタム言語モデルは最大 10 個です。
カスタム言語モデルの作成とトレーニング
カスタム言語モデルのトレーニングは、通常、反復的なプロセスです。 基本モデルを選択し、コーパスをアップロードしてモデルをトレーニングし、精度を評価します。 結果が要件を満たさない場合は、コーパスを修正して再度トレーニングを行います。
Intelligent Speech Interaction コンソールにログインします。
左側のナビゲーションウィンドウで、[セルフラーニングプラットフォーム] > [カスタム言語モデル] を選択します。 [カスタム言語モデル] ページの [モデル] タブで、[モデルの作成] をクリックします。
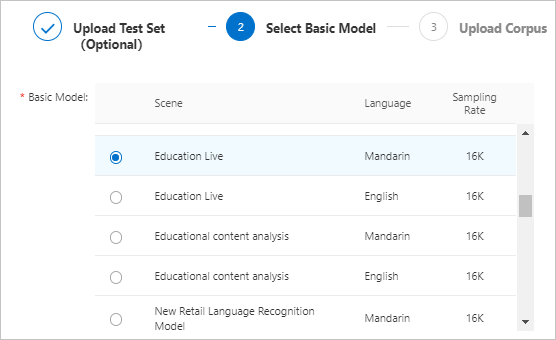
[基本モデルの選択] ステップで、基本モデルを選択し、[次へ] をクリックします。
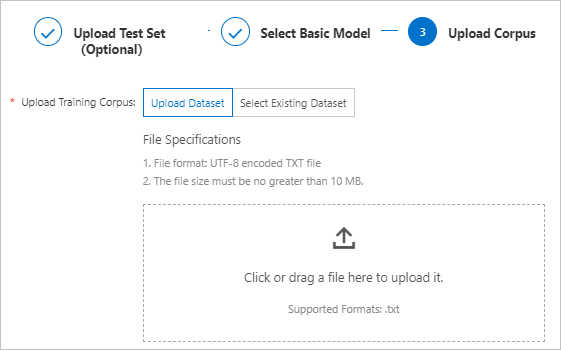
[コーパスのアップロード] ステップで、トレーニングコーパスをアップロードまたは選択し、[OK] をクリックします。 コーパスがアップロードまたは選択されると、トレーニングが自動的に開始されます。 モデルのトレーニング中は、[モデルステータス] 列に [トレーニング中] と表示されます。
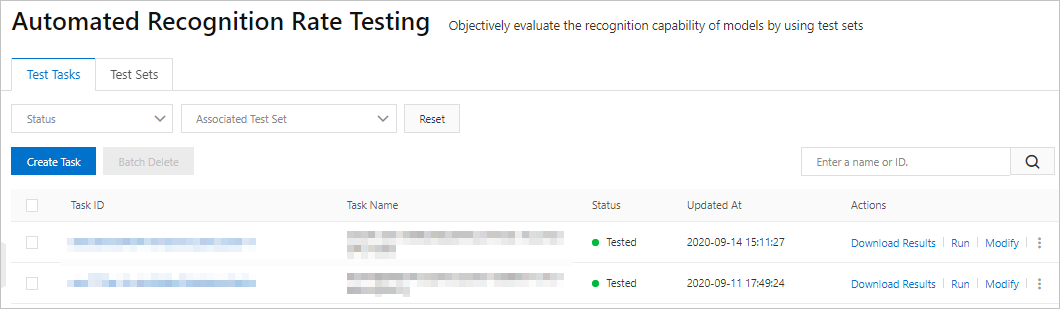
モデルのステータスが [デプロイ済み] になったら、自動テストタスクを作成します。
ステップ 4 でテストセットをアップロードした場合、モデルのステータスが [デプロイ済み] になると、システムによって自動的にテストタスクが作成されます。
ステップ 4 でテストセットをアップロードしなかった場合は、[操作] 列の [自動テスト] をクリックして、手動でテストタスクを作成します。
カスタム言語モデルをプロジェクトに適用します。 モデルのステータスが [デプロイ済み] になったら、次の手順でプロジェクトに適用します。
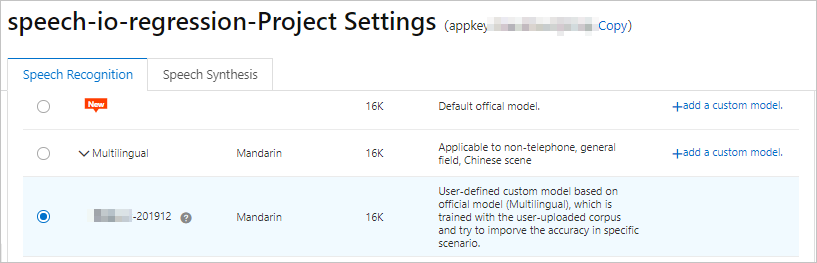
左側のナビゲーションウィンドウで、[マイプロジェクト] をクリックします。 対象のプロジェクトを見つけ、[操作] 列の [プロジェクト設定] をクリックします。
[音声認識] タブで [シーンの切り替え] をクリックし、カスタム言語モデルを選択します。
[公開] をクリックします。