このトピックでは、Hologresでシャードレベルレプリケーション機能を使用する方法について説明します。
概要
Hologres V1.1以降では、テーブルグループの各シャードのレプリカ数を指定して、テーブルグループに対するクエリの同時実行性と可用性を向上させることができます。 シャードレベルレプリケーション機能を有効にするには、テーブルグループの作成時にレプリカ数を明示的に指定するか、既存のテーブルグループのレプリカ数を変更します。 新しいレプリカは、メモリを占有するランタイムレプリカであり、ストレージコストは増加しません。
各シャードのレプリカ数を指定または変更する場合は、次の点に注意してください。
Hologresインスタンスのデータは、シャードによって分散されます。 各シャードは異なるデータを管理します。 データは異なるシャード間で重複しません。 すべてのシャードのデータが完全なデータセットを形成します。
デフォルトでは、各シャードには 1 つのレプリカしかありません。 この場合、
replica_countパラメーターの値は 1 です。 このレプリカはリーダシャードとして機能します。 replica_count パラメーターを変更して、各シャードのレプリカ数を増やすことができます。 リーダシャード以外のシャードレプリカは、フォロワーシャードとして機能します。リーダシャードはすべての書き込みリクエストを担当します。 読み取りリクエストは、リーダシャードとフォロワーシャードの間で均等に分散されます。 クエリがフォロワーシャードにルーティングされた場合、クエリに 10 ~ 20 ミリ秒のレイテンシが発生する可能性があります。
replica_countパラメーターのデフォルト値は 1 で、シャードレベルレプリケーション機能が無効になっていることを指定します。 1 より大きい値は、シャードレベルレプリケーション機能が有効になっていることを指定します。 値が大きいほど、必要なリソースが多くなります。 アンチアフィニティ機能のため、1 つの計算ノードにデプロイできるレプリカは 1 つだけです。 replica_countパラメーターの値は、計算ノードの数以下である必要があります。 Hologres V1.3.53以降では、replica_countパラメーターの最大値はワーカーノードの数です。 上限を超えると、エラーメッセージが報告されます。 さまざまなインスタンス仕様の計算ノード数の詳細については、インスタンス管理をご参照ください。
計算ノードの計算能力のバランスをとるには、各シャードのレプリカ数を増やすときに、シャードの数を減らす必要があります。 最適なパフォーマンスを実現するには、次の式が満たされていることを確認してください。
shard_count パラメーターの値 × replica_count パラメーターの値 = インスタンスの推奨シャード数。Hologres V1.3.45以降では、高可用性モードでのクエリがサポートされています。
次の図に示す CPU 使用率の問題が、Hologresインスタンスで発生する可能性があります。 Hologresコンソールの監視情報ページで、Hologresインスタンスの CPU 使用率情報を確認できます。

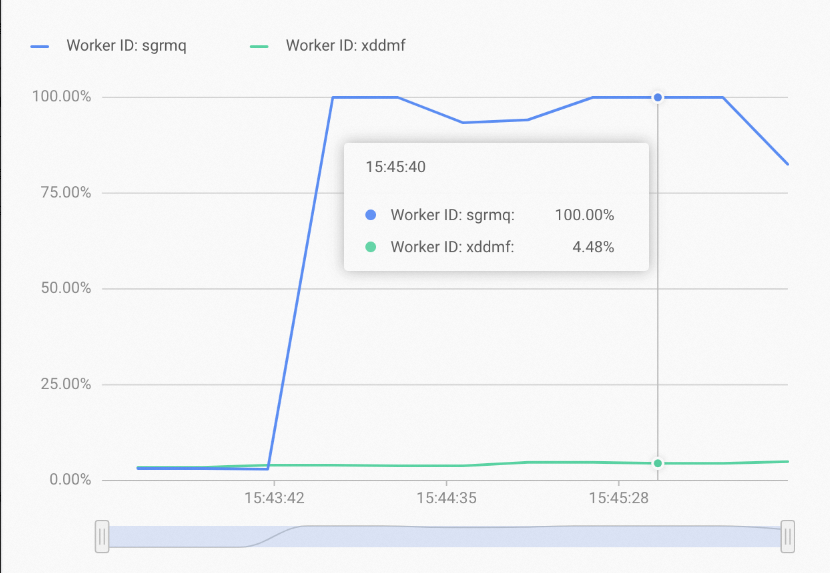
上記の図は、インスタンスの CPU 使用率が中程度であることを示していますが、1 つのワーカーノードの CPU 使用率が過度に低く、もう 1 つのワーカーノードの CPU 使用率が過度に高くなっています。 これは、ワーカーノードでのクエリの分散が不均一であることが原因である可能性があります。 ほとんどのクエリは、少数のシャードのみにルーティングされます。 この場合、シャードレプリカの数を増やすことで、より多くのワーカーノードがシャードレプリカを持つことができるようにすることができます。 これにより、リソース使用率と 1 秒あたりのクエリ数 (QPS) を効果的に向上させることができます。
説明リーダシャードとフォロワーシャード間のメタデータ同期はリソースを消費します。 多数のシャードレプリカは、データ同期に大量のリソースを消費します。 ワーカーノード間の CPU 使用率の不均一がクエリの不均一な分散によって引き起こされている場合にのみ、シャードレプリカの数を増やすことによって QPS を向上させることをお勧めします。
リーダシャードまたはフォロワーシャードでのデータクエリのレイテンシはミリ秒レベルです。
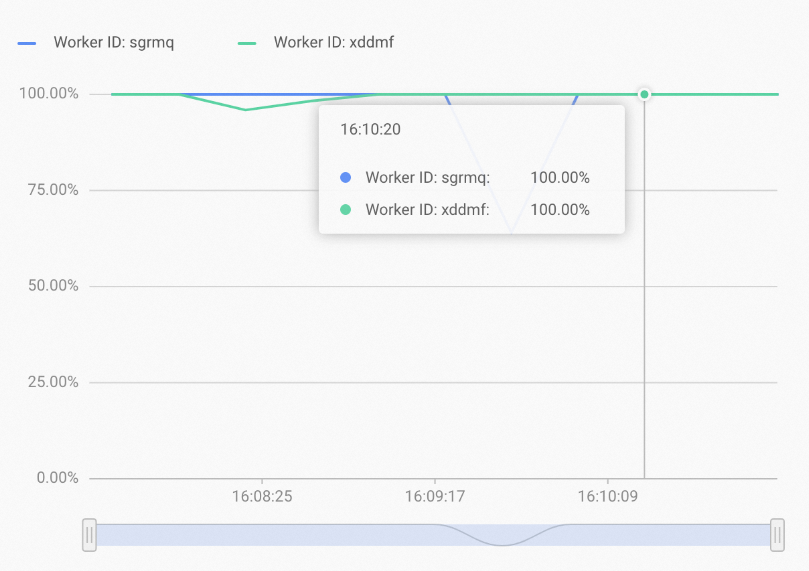
シャードレプリカの数を増やすと、次の図に示すように、各ワーカーノードのリソースが完全に活用されます。
制限
Hologres V1.1以降でのみ、シャードレベルレプリケーション機能がサポートされています。
説明Hologresコンソールのインスタンス詳細ページで、Hologresインスタンスのバージョンを確認できます。 Hologresインスタンスのバージョンが V0.10以前の場合は、インスタンスを手動でアップグレードするか、Hologres DingTalkグループに参加してエンジニアにインスタンスのアップグレードを依頼できます。 詳細については、インスタンスのアップグレードの「手動アップグレード」セクションとHologresのオンラインサポートを受けるをご参照ください。
replica_countパラメーターの値は、計算ノードの数以下である必要があります。 Hologresコンソールのインスタンス詳細ページで、Hologresインスタンスの計算ノードの数を確認できます。
構文
データベース内のテーブルグループをクエリする
現在のデータベース内のテーブルグループをクエリするには、次のステートメントを実行します。
select * from hologres.hg_table_group_properties ;テーブルグループの各シャードのレプリカ数をクエリする
サンプルステートメント
select property_value from hologres.hg_table_group_properties where tablegroup_name = 'table_group_name' and property_key = 'replica_count';パラメーター
パラメーター
説明
table_group_name
クエリするテーブルグループの名前。
replica_count
クエリするプロパティ。 値を replica_count に設定します。
シャードレベルレプリケーション機能を有効にする
サンプルステートメント
テーブルグループの各シャードのレプリカ数を変更することで、シャードレベルレプリケーション機能を有効にできます。
-- テーブルグループの各シャードのレプリカ数を変更します。 call hg_set_table_group_property ('<table_group_name>', 'replica_count', '<replica_count>');パラメーター
パラメーター
説明
hg_set_table_group_property
テーブルグループの replica_count パラメーターを変更します。
table_group_name: 変更するテーブルグループの名前を入力します。
replica_count: テーブルグループのレプリカ数。 値は計算ノードの数以下である必要があり、通常は 2 に設定されます。
レプリケーションを有効にするかどうか: デフォルト値は 1 で、レプリケーションが有効になっていないことを示します。 1 より大きい値は、レプリケーションが有効になっていることを示します。
シャードレベルレプリケーション機能を無効にする
サンプルステートメント
-- replica_countパラメーターを変更して、シャードレベルレプリケーション機能を無効にします。 call hg_set_table_group_property ('table_group_name', 'replica_count', '1');パラメーター
パラメーター
説明
hg_set_table_group_property
テーブルグループの各シャードのレプリカ数を変更するために使用される関数。
table_group_name: 管理するテーブルグループの名前。
replica_count: テーブルグループの各シャードのレプリカ数。
replica_countパラメーターをデフォルト値 1 に設定すると、シャードレベルレプリケーション機能が無効になります。 1 より大きい値は、シャードレベルレプリケーション機能が有効になっていることを指定します。
各ワーカーノードにロードされているシャードメタデータを確認する
各シャードに複数のレプリカを設定した後、次の SQL ステートメントを実行して、各ワーカーノードにロードされているシャードメタデータを確認できます。
SELECT * FROM hologres.hg_worker_info;説明シャードのメタデータがワーカーノードにロードされる前は、このワーカーノードの worker_id パラメーターの値が空の場合があります。
次の図は、返された結果を示しています。
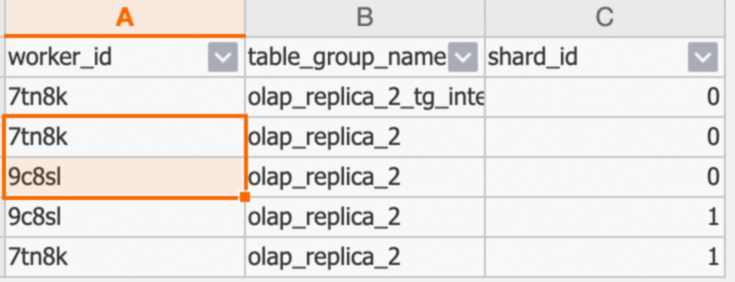
olap_replica_2テーブルグループのテーブルのデータは、シャード 0 とシャード 1 という名前の 2 つのシャードに分散されます。 シャード 0 とシャード 1 のメタデータは、7tn8kワーカーノードと9c8slワーカーノードにロードされます。
シャードポリシーを設定してクエリの高可用性と高スループットを実現する
説明
この例では、1 つのシャードに複数のレプリカが設定されています。 シャードレプリカは複数のワーカーノードにロードされます。 クエリは、次の図に示すように、ワーカーノードのシャードレプリカにランダムにルーティングされます。

ポイントクエリがタイムアウトした場合、システムはポイントクエリを別のワーカーノードのシャードレプリカにルーティングできます。 これにより、ポイントクエリの結果が返されます。 ポイントクエリは、固定プランを使用して処理されます。
パラメーター
hg_experimental_query_replica_mode: クエリのルーティングに使用されるシャードポリシー。シナリオ
デフォルト値
値のタイプ
有効な値
例
すべてのクエリ
leader_follower
TEXT
leader_follower: クエリは、特定の比率に基づいてリーダシャードとフォロワーシャードにルーティングされます。 これはデフォルト値です。leader_only: クエリはリーダシャードのみにルーティングされます。 この場合、replica_countパラメーターの値が 1 より大きくても、スループットと可用性は向上しません。follower_only: クエリはフォロワーシャードのみにルーティングされます。 この場合、replica_countパラメーターを 3 より大きい値に設定する必要があります。 これにより、2 つ以上のフォロワーシャードが存在し、スループットと可用性を向上させることができます。
-- セッションレベルの設定 SET hg_experimental_query_replica_mode = leader_follower; -- データベースレベルの設定 ALTER DATABASE <database_name> SET hg_experimental_query_replica_mode = leader_follower;hg_experimental_query_replica_leader_weight: クエリのルーティングに使用されるリーダシャードの重み。シナリオ
デフォルト値
値のタイプ
有効な値
例
すべてのクエリ
100
INT
最大値: 10000。
最小値: 1。
デフォルト値: 100。
-- セッションレベルの設定 SET hg_experimental_query_replica_leader_weight = 100; -- データベースレベルの設定 ALTER DATABASE <database_name> SET hg_experimental_query_replica_leader_weight = 100;オンライン分析処理 (OLAP) ポイントクエリの場合、データのクエリ元のテーブルのテーブルグループの
replica_countパラメーターを 1 より大きい値に設定すると、クエリはhg_experimental_query_replica_modeパラメーターとhg_experimental_query_replica_leader_weightパラメーターの値に基づいて、リーダシャードとフォロワーシャードにルーティングされます。 例:例 1: データのクエリ元のテーブルのテーブルグループの
replica_countパラメーターを 1 より大きい値に設定し、hg_experimental_query_replica_mode=leader_follower構成を追加すると、システムはhg_experimental_query_replica_leader_weightパラメーターの値に基づいて、クエリをリーダシャードとフォロワーシャードにルーティングします。 デフォルトでは、hg_experimental_query_replica_leader_weight パラメーターの値は 100 で、各フォロワーシャードの重みも 100 です。replica_countパラメーターを 4 に設定すると、各シャードに 1 つのリーダシャードと 3 つのフォロワーシャードを使用できます。 この場合、リーダシャードと各フォロワーシャードには、クエリにヒットする確率が25%あります。例 2: データのクエリ元のテーブルのテーブルグループの
replica_countパラメーターを 1 より大きい値に設定し、hg_experimental_query_replica_modeパラメーターを leader_only に設定すると、システムはクエリをリーダシャードのみにルーティングします。例 3: データのクエリ元のテーブルのテーブルグループの
replica_countパラメーターを 1 より大きい値に設定し、hg_experimental_query_replica_modeパラメーターを follower_only に設定すると、システムはクエリをフォロワーシャードのみにルーティングします。 デフォルトでは、各フォロワーシャードの重みは 100 です。replica_countパラメーターを 4 に設定すると、各シャードに 1 つのリーダシャードと 3 つのフォロワーシャードを使用できます。 この場合、クエリは 3 つのフォロワーシャードにルーティングされ、各フォロワーシャードにはクエリにヒットする確率が 1/3 あります。
hg_experimental_query_replica_fixed_plan_ha_mode: ポイントクエリのルーティングに使用される高可用性ポリシー。 ポイントクエリは、固定プランを使用して処理されます。シナリオ
デフォルト値
値のタイプ
有効な値
例
ポイントクエリ (固定プランを使用して処理)
any
TEXT
any: クエリは、hg_experimental_query_replica_modeパラメーターとhg_experimental_query_replica_leader_weightパラメーターの値に基づいて、シャードレプリカにルーティングされます。 これはデフォルト値です。leader_first: この値は、hg_experimental_query_replica_modeパラメーターがleader_followerに設定されている場合にのみ有効になります。 この値は、クエリが優先的にリーダシャードにルーティングされることを指定します。 タイムアウトなどの理由でリーダシャードが使用できない場合、クエリはフォロワーシャードにルーティングされます。off: クエリは 1 回だけルーティングされます。
-- セッションレベルの設定 SET hg_experimental_query_replica_fixed_plan_ha_mode = any; -- データベースレベルの設定 ALTER DATABASE <database_name> SET hg_experimental_query_replica_fixed_plan_ha_mode = any;hg_experimental_query_replica_fixed_plan_first_query_timeout_ms: 高可用性シナリオでの初回ポイントクエリのタイムアウトを決定するしきい値。 タイムアウトしきい値に達するか超えると、ポイントクエリは別の使用可能なシャードにルーティングされます。 ポイントクエリは、固定プランを使用して処理されます。 たとえば、hg_experimental_query_replica_fixed_plan_first_query_timeout_ms=60は、60 ミリ秒以内にクエリで結果が返されない場合、システムがクエリを別のワーカーノードのシャードにルーティングすることを指定します。シナリオ
デフォルト値
値のタイプ
有効な値
例
すべてのクエリ
60
INT
最大値: 10000。
最小値: 0。
デフォルト値: 60。
-- セッションレベルの設定 SET hg_experimental_query_replica_fixed_plan_first_query_timeout_ms = 60; -- データベースレベルの設定 ALTER DATABASE <database_name> SET hg_experimental_query_replica_fixed_plan_first_query_timeout_ms = 60;
さまざまなシナリオの推奨事項
シナリオ 1: 高スループットのためのマルチレプリカ
シナリオの説明: 監視情報は、インスタンスの CPU 使用率が中程度であることを示していますが、1 つのワーカーノードの CPU 使用率が過度に低く、もう 1 つのワーカーノードの CPU 使用率が過度に高くなっています。 これは、ワーカーノードでのクエリの分散が不均一であることが原因である可能性があります。 ほとんどのクエリは、少数のシャードのみにルーティングされます。 この場合、シャードレプリカの数を増やすことで、より多くのワーカーノードがシャードレプリカを持つことができるようにすることができます。 これにより、リソース使用率と QPS を効果的に向上させることができます。
手順
シャードレプリカの数を増やす:
この例では、tg_replica という名前のテーブルグループがデータベースに存在します。 次の SQL ステートメントを実行して、レプリカの数を 2 に設定します。
-- tg_replica テーブルグループのテーブルのレプリカの数を 2 に設定します。 call hg_set_table_group_property ('tg_replica', 'replica_count', '2');システムには次のデフォルト設定があります。
hg_experimental_query_replica_mode=leader_follower
hg_experimental_query_replica_leader_weight=100
レプリカの数を増やすと、システムはクエリをリーダシャードとフォロワーシャードに対応するワーカーノードにランダムにルーティングします。 これにより、ホットデータクエリの場合でも QPS を増やすことができます。
シャードレプリカが各ワーカーノードにロードされているかどうかを確認する:
次のステートメントを実行して、シャードレプリカが各ワーカーノードにロードされているかどうかを確認します。
SELECT * FROM hologres.hg_worker_info WHERE table_group_name = 'tg_replica';次の図は、返された結果を示しています。

上記の図は、1 つのシャードレプリカが複数のワーカーノードにロードされていることを示しています。 設定が有効になります。
シナリオ 2: 高可用性のためのマルチレプリカ
シナリオの説明: クエリが実行されるシャードに障害が発生した場合にクエリが失敗するという問題を解決したいと考えています。
手順:
シャードレプリカの数を増やす:
この例では、tg_replica という名前のテーブルグループがデータベースに存在します。 次の SQL ステートメントを実行して、レプリカの数を 2 に設定します。
-- tg_replica テーブルグループのテーブルのレプリカの数を 2 に設定します。 call hg_set_table_group_property ('tg_replica', 'replica_count', '2');システムには次のデフォルト設定があります。
hg_experimental_query_replica_mode=leader_follower
hg_experimental_query_replica_fixed_plan_ha_mode=any
hg_experimental_query_replica_fixed_plan_first_query_timeout_ms=60
レプリカの数を増やすと、システムはさまざまなシナリオでさまざまな操作を実行します。
OLAP シナリオでは、システムはクエリをリーダシャードとフォロワーシャードに対応するワーカーノードにランダムにルーティングします。 データをクエリすると、マスターノードは各シャードレプリカが使用可能かどうかを定期的にチェックします。 システムは使用できないシャードレプリカを削除し、クエリを使用可能なシャードレプリカにルーティングします。 使用できないシャードレプリカが再び使用可能になると、システムはクエリをシャードレプリカにルーティングできます。 システムは、シャードレプリカが使用可能かどうかを検出するのに 5 秒、使用できないシャードレプリカがロードされているワーカーノードに対応する FE ノードを削除するのに 10 秒かかります。 合計で、システムは問題を検出してクエリを再開するのに 15 秒かかります。 15 秒後、クエリは想定どおりに実行できます。
固定プランシナリオでは、システムは再試行メカニズムを提供します。 ワーカーノードに障害が発生した場合、クエリは別のワーカーノードのシャードレプリカにルーティングできます。 クエリは完了できますが、応答時間が長くなります。
データが書き込まれた直後にデータをすぐにクエリする必要があるいくつかの固定プランシナリオでは、
hg_experimental_query_replica_fixed_plan_ha_modeパラメーターをleader_firstに設定して、フォロワーシャードの長いレイテンシを防ぐことができます。 この構成では、クエリは優先的にリーダシャードにルーティングされます。 リーダシャードでのクエリがタイムアウトした場合、クエリはフォロワーシャードにルーティングされます。説明この場合、ホットデータクエリの QPS を増やすことはできません。
シャードレプリカが各ワーカーノードにロードされているかどうかを確認します。
次のステートメントを実行して、シャードレプリカが各ワーカーノードにロードされているかどうかを確認します。
SELECT * FROM hologres.hg_worker_info WHERE table_group_name = 'tg_replica';次の図は、返された結果を示しています。
上記の図は、1 つのシャードレプリカが複数のワーカーノードにロードされていることを示しています。 設定が有効になります。
FAQ
問題の説明: シナリオ 1 の説明に従ってパラメーターを設定した後、クエリがフォロワーシャードにルーティングされません。 Hologresコンソールの監視情報は、負荷の高いワーカーノードの設定後も負荷が高いことを示しています。
原因: Hologres V1.3 より前のバージョンでは、Grand Unified Configuration (GUC) パラメーター
hg_experimental_enable_read_replicaが提供されており、クエリをフォロワーシャードにルーティングできるかどうかを指定します。 デフォルト値は off です。 次の SQL ステートメントを実行して、GUC パラメーターが on に設定されているかどうかを確認できます。 値 on は、クエリをフォロワーシャードにルーティングできることを指定します。 値 off は、クエリをフォロワーシャードにルーティングできないことを指定します。SHOW hg_experimental_enable_read_replica;解決策:
hg_experimental_enable_read_replicaパラメーターの値が off の場合は、次の SQL ステートメントを実行して、データベースレベルで GUC パラメーターを on に設定できます。ALTER DATABASE <database_name> SET hg_experimental_enable_read_replica = on;database_name をデータベース名に置き換えます。