Hologres は、DAMO Academy によって独自に開発された高性能ベクトル計算ソフトウェアライブラリである Proxima と緊密に統合されており、高性能、低レイテンシ、そして使いやすいベクトル計算機能を提供します。このトピックでは、Platform for AI(PAI)の Elastic Algorithm Service(EAS)と DeepSeek を使用して Retrieval-Augmented Generation(RAG)ベースのチャットボットをデプロイし、このチャットボットを Hologres インスタンスに関連付ける方法について説明します。また、RAG ベースのチャットボットの基本的な機能と Hologres の高性能ベクトル機能の概要についても説明します。
背景情報
LLM の制限
分野の知識の制限:ほとんどの場合、大規模言語モデル(LLM)は大規模な汎用データセットを使用してトレーニングされます。この場合、LLM は専門的な分野の深く的を絞った処理に苦労します。
情報の更新の遅延:トレーニングデータセットの静的な性質により、LLM はリアルタイムの情報や知識の更新にアクセスして組み込むことができません。
誤解を招く出力:LLM はハルシネーションを起こしやすく、もっともらしいが出鱈目な出力を生成します。これは、データのバイアスやモデル固有の制限などの要因によるものです。
RAG テクノロジー
AI テクノロジーの急速な発展に伴い、生成 AI はテキスト生成や画像生成など、さまざまな分野で目覚ましい成果を上げています。LLM の制限に対処し、LLM の機能と精度を高めるために、RAG テクノロジーが登場しました。
テクノロジーの特徴:外部のナレッジベースを統合することで、RAG は LLM で架空のコンテンツを生成するという問題を大幅に削減し、最新の知識にアクセスして適用する能力を向上させます。これにより、LLM のよりパーソナライズされた正確なカスタマイズが可能になります。
RAG ベースのチャットボットのコアコンポーネント
コンポーネント | 説明 |
Hologres | Hologres は、Alibaba Cloud によって開発されたワンストップのリアルタイムデータウェアハウスサービスです。大量データのオンライン分析処理(OLAP)と、高並列性と低レイテンシのオンラインデータサービスをサポートしています。また、Hologres は、DAMO Academy によって独自に開発された高性能ベクトル計算ソフトウェアライブラリである Proxima と緊密に統合されており、高性能、低レイテンシ、そして使いやすいベクトル計算機能を提供します。詳細については、「Proxima ベースのベクトル処理」をご参照ください。 |
PAI の EAS | PAI の EAS は、シナリオ固有のデプロイ方法を提供します。パラメーターを設定して、LLM と統合された RAG ベースのチャットボットをデプロイできます。これにより、サービスのデプロイ期間が大幅に短縮されます。チャットボットを使用してモデル推論を実行すると、チャットボットはナレッジベースから関連情報を効果的に取得し、取得した情報を LLM からの回答と組み合わせて、正確で有益な回答を提供します。これにより、Q&A の質と全体的なパフォーマンスが大幅に向上します。チャットボットは、特定のナレッジベースに依存する Q&A、要約、その他の自然言語処理(NLP)タスクに適しています。 |
DeepSeek | DeepSeek は、DeepSeek 社が Mixture of Experts(MoE)アーキテクチャに基づいて開発した LLM です。効率的な推論と取得タスクをサポートするように設計されており、ユーザーは LLM アプリケーションを迅速に構築およびスケーリングできます。現在、PAI の EAS は DeepSeek のワンクリックデプロイをサポートしています。 |
ケース効果
Hologres、DeepSeek、PAI の EAS を使用して RAG ベースのチャットボットを構築することで、さまざまな戦略を使用して会話を実施できます。次の表に、さまざまな戦略の質問と回答を示します。
戦略 | 質問 | 回答 |
| Serverless Computing | ベクトルデータベース内の Serverless Computing に関連するコンテンツが項目ごとに返されます。 |
| 固定プランは Hologres Serverless Computing を使用して高速化できますか。 | 固定プランは通常、Hologres Serverless Computing による高速化などの高度な機能を含まない基本プランです。Hologres Serverless Computing を使用して高速化する必要がある場合は、通常、より多くの機能とより高いパフォーマンスを提供する上位層のプラン(Pro プランまたは Enterprise プランなど)にアップグレードすることをお勧めします。他に質問や詳細情報が必要な場合は、お気軽にお問い合わせください。 |
| Hologres Serverless Computing は、固定プランのポイントクエリなど、固定プランのオンラインサービスシナリオを直接高速化することはできません。これは、Serverless Computing の計算リソースが共有されており、リアルタイムのオンラインサービスシナリオをサポートできないためです。固定プランのポイントクエリなどの遅延の影響を受けやすいシナリオでは、専用の計算リソースを使用することをお勧めします。 |
LLM によって強化された RAG ベースのチャットボットは、Hologres のベクトルデータベースの専門情報を活用することで、同じ質問に対して、ナレッジベースから関連情報を効果的に取得し、LLM の応答と組み合わせることができます。これにより、正確で情報量の多い回答を生成し、応答の質と全体的なパフォーマンスを大幅に向上させることができます。
RAG ベースのチャットボットの構築における Hologres の主な利点:
リアルタイムベクトル取得機能
Proxima と緊密に統合された Hologres は、効率的なベクトル類似検索をサポートします。
統合マルチモーダルデータ処理
Hologres は、従来の構造化データとベクトルデータの結合クエリをサポートし、ナレッジベースでのハイブリッド検索を可能にします。
超大規模ナレッジベースのサポート
Hologres は、企業レベルの超大規模ナレッジベースのストレージと取得ニーズを処理でき、ビジネスの急速な成長に適応するために動的にスケーリングできます。
エンタープライズレベルの信頼性
Hologres は、分散トランザクションを通じてナレッジベースの更新の原子性と一貫性を確保し、高可用性を確保し、本番環境での SLA 要件を満たします。
シームレスなエコシステム統合
Hologres は、PAI の EAS と緊密に統合されており、Alibaba Cloud PAI とシームレスに接続して、エンドツーエンドの RAG パイプライン構築をサポートします。
前提条件
仮想プライベートクラウド(VPC)、vSwitch、およびセキュリティグループが作成されています。詳細については、「IPv4 CIDR ブロックを使用して VPC を作成する」および「セキュリティグループを作成する」をご参照ください。
Hologres インスタンスと RAG ベースのチャットボットは、同じ VPC にデプロイする必要があります。
手順
ステップ 1:Hologres ベクトルデータベースを準備する
Hologres インスタンスを購入し、データベースを作成します。詳細については、「Hologres インスタンスを購入する」および「データベースを作成する」をご参照ください。
説明アカウントを作成した後、アカウントにデータベース関連の権限を付与する必要があります。詳細については、「Hologres 権限モデル」をご参照ください。「HoloWeb に接続してクエリを実行する」の手順に従って、権限が付与されているかどうかを確認できます。
簡易権限モデル(SPM)を使用して、開発者レベル以上の権限をアカウントに付与することをお勧めします。
ステップ 2 で必要な Hologres インスタンスエンドポイントを取得します。
Hologres コンソール にログインします。
左側のナビゲーションウィンドウで、[インスタンス] をクリックします。
表示されるページで、目的のインスタンスを見つけ、インスタンスの名前をクリックします。[インスタンスの詳細] ページの [ネットワーク情報] セクションで、[VPC の選択] を見つけ、[エンドポイント] 列の [コピー] をクリックして Hologres インスタンスエンドポイントをコピーします。
ステップ 2:DeepSeek を使用する RAG ベースのチャットボットをデプロイする
PAI コンソール にログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。
[ワークスペース] ページで、[ワークスペースの作成] をクリックします。[ワークスペースの作成] ページで、パラメーターを設定してワークスペースを作成します。詳細については、「ワークスペースの作成と管理」をご参照ください。
左側のナビゲーションウィンドウで、 を選択して、[Elastic Algorithm Service (EAS)] ページに移動します。
[推論サービス] タブで、[サービスのデプロイ] をクリックします。[サービスのデプロイ] ページで、[シナリオベースのモデルデプロイ] セクションの [RAG ベースのスマートダイアログデプロイ] をクリックします。
[RAG ベースの LLM チャットボットのデプロイ] ページで、パラメーターを設定します。次の表に、パラメーターを示します。
パラメーター
説明
基本情報
[バージョン]
デプロイバージョン。有効な値:
LLM 統合デプロイ:LLM と統合された RAG サービスをデプロイします。
LLM 分離デプロイ:RAG サービスのみをデプロイします。RAG サービスにより、LLM に簡単に接続し、柔軟に置き換えることができます。このデプロイバージョンは、より高い柔軟性を提供します。
この例では、[LLM 統合デプロイ] が選択されています。ビジネス要件に基づいてデプロイバージョンを選択できます。
[モデルタイプ]
この例では、[DeepSeek] シリーズモデルが使用されています。ビジネスシナリオに基づいてオープンソースモデルを選択できます。
リソースのデプロイ
リソース構成
システムは、選択されたモデルタイプに基づいて適切なリソース仕様を推奨します。他のリソース仕様を使用すると、モデルサービスが起動に失敗する可能性があります。
ベクトルデータベース設定
[ベクトルデータベースタイプ]
[Hologres] を選択します。
[呼び出し情報]
指定された VPC のホスト情報。 Hologres コンソールのインスタンス詳細ページに移動します。 [ネットワーク情報] セクションで、[VPC を選択] を見つけ、エンドポイント列の [コピー] をクリックしてインスタンスエンドポイントをコピーします。ホスト情報は、末尾から
:80を除いたインスタンスエンドポイントを指します。[データベース名]
Hologres インスタンス内のデータベースの名前。データベースの作成方法の詳細については、「データベースを作成する」をご参照ください。
[アカウント]
作成したカスタムアカウント。詳細については、「ユーザー管理」をご参照ください。
[パスワード]
作成したカスタムアカウントのパスワード。
[テーブル名]
テーブルの名前。新しいテーブル名または既存のテーブル名を入力できます。この例では、
feature_tbという名前のテストテーブルが使用されています。新しいテーブル名を入力することをお勧めします。これにより、PAI-RAG は Hologres に対応するテーブルを自動的に作成します。存在しないテーブル名を入力すると、PAI-RAG は対応するベクトルインデックステーブルを自動的に作成します。
既存のテーブル名を入力する場合、テーブルスキーマは PAI-RAG の要件を満たしている必要があります。たとえば、以前に EAS を使用して RAG ベースのチャットボットをデプロイしたときに自動的に作成された Hologres テーブルの名前を入力できます。
VPC
[VPC (VPC)]
プライベートネットワークを使用してアクセスすることをお勧めします。プライベートネットワークを使用してアクセスするには、EAS で構成された VPC が Hologres インスタンスがデプロイされている VPC と同じであることを確認する必要があります。VPC、vSwitch、およびセキュリティグループの作成方法の詳細については、「VPC の作成と管理」および「セキュリティグループを作成する」をご参照ください。
[vSwitch]
[セキュリティグループ名]
パラメーターを設定した後、[デプロイ] をクリックします。サービスステータスが [実行中] に変わると、RAG ベースのチャットボットがデプロイされます。
ステップ 3: Web UI でモデル推論を実行する
RAG ベースのチャットボットがデプロイされた後、[Elastic Algorithm Service (EAS)] ページの [推論サービス] タブをクリックします。サービスを見つけ、[サービスタイプ] 列の [Web アプリの表示] をクリックして Web UI を起動します。
次の操作を実行して、Web UI でサービスをデバッグします。
ベクトルデータベースと LLM に関連するパラメーターを設定します。
[設定] タブで、埋め込み関連のパラメーターと LLM 関連のパラメーターを変更できます。パラメーターを設定した後、[インデックスの更新] をクリックして構成を保存します。
埋め込み関連のパラメーター
パラメーター
説明
インデックス名
システムは既存のインデックスを更新できます。[インデックス名] ドロップダウンリストから [新規] を選択し、[新しいインデックス名] フィールドにインデックス名を指定して、異なるナレッジベースのデータを分離できます。詳細については、「RAG サービスを使用してナレッジベースデータを分離する方法」をご参照ください。
埋め込みタイプ
huggingfaceモデルとdashscopeモデルがサポートされています。この例では、huggingface モデルが選択されています。huggingface:システムは、選択できる組み込みの埋め込みモデルを提供します。dashscope:Alibaba Cloud Model Studio でサポートされているモデルを使用できます。デフォルトでは、text-embedding-v2 モデルが使用されます。詳細については、「埋め込み」をご参照ください。説明dashscopeを選択した場合は、EAS のパブリックネットワーク接続を設定し、Model Studio の API キーを設定する必要があります。Model Studio でサポートされているモデルの呼び出しには、別途課金されます。詳細については、「課金対象項目」をご参照ください。
埋め込み次元
出力ベクトルの次元。次元設定はモデルのパフォーマンスに直接影響します。埋め込みモデルを選択すると、システムはこのパラメーターを自動的に設定します。手動操作は必要ありません。
埋め込みバッチサイズ
バッチ処理サイズ。
LLM 関連のパラメーター
RAG ベースのチャットボットをデプロイするときに、[バージョン] で [LLM 統合デプロイ] を選択した場合、LLM は RAG サービスに統合されます。この場合、LLM 関連のパラメーターを設定する必要はありません。
[バージョン] で [LLM 分離デプロイ] を選択した場合は、次の手順を実行してエンドポイントとトークンを取得します。次に、必要なパラメーターを設定します。
[Elastic Algorithm Service (EAS)] ページの [推論サービス] タブで、デプロイしたサービスの名前をクリックします。
[概要] タブで、[基本情報] セクションの [エンドポイント情報の表示] をクリックします。
[呼び出し方法] ダイアログボックスで、接続方法に基づいてエンドポイントと [トークン] を取得します。
ビジネスデータファイルをアップロードします。
[アップロード] タブで、意味ベースのチャンキングパラメーターを設定し、ビジネスデータファイルをアップロードできます。システムは自動的に埋め込みを完了し、埋め込まれたデータを Hologres ベクトルデータベースに保存します。
意味ベースのチャンキングパラメーターを設定します。
次のパラメーターを設定して、チャンクサイズを指定し、
Q&A情報を抽出できます。パラメーター
説明
チャンクサイズ
各チャンクのサイズ。単位:バイト。デフォルト値:500。
チャンクの重複
隣接するチャンク間の重複部分。デフォルト値:10。
マルチモーダルで処理
マルチモーダルモデル処理を使用するかどうかを指定します。オプションを選択すると、PDF、Word、Markdown ファイル内の画像を処理できます。この例では、TXT 形式のファイルが使用されています。したがって、このオプションを選択する必要はありません。
OCR で PDF を処理
OCR モードで PDF ファイルを解析するかどうかを指定します。
ビジネスデータファイルをアップロードします。
この例では、テストファイル rag_hologres.txt が使用されています。
次のファイル形式がサポートされています:TXT、PDF、XLSX、XLS、CSV、DOCX、DOC、MD、HTML。
ローカルファイル、ローカルディレクトリ、または OSS からのオブジェクトをアップロードできます。
ビジネスデータファイルをアップロードすると、システムはデータクレンジングと意味ベースのチャンキングを実行し、データを Hologres ベクトルデータベースに保存します。データクレンジングには、テキストの抽出とハイパーリンクの置き換えが含まれます。
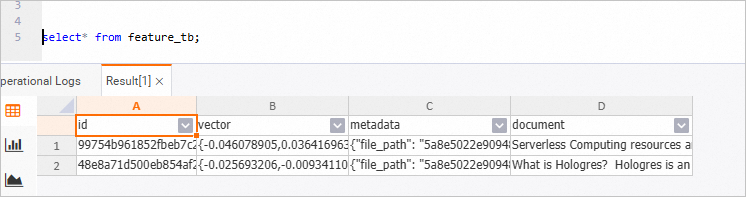
次の図は、Hologres ベクトルデータベース内のデータを示しています。HoloWeb コンソールにログインして、データをクエリできます。詳細については、「HoloWeb に接続してクエリを実行する」をご参照ください。
モデル推論パラメーターを構成します。
[チャット] タブで、ベクトル検索とモデル推論のパラメーターを設定できます。
ポリシーパラメーター
パラメーター
説明
検索
ベクトルデータベースから上位 K 件の関連結果を返します。
LLM
LLM からの回答を使用します。
チャット(Web 検索)
ユーザーの質問に基づいてインターネット検索が必要かどうかを判断します。インターネット検索が必要な場合、チャットボットは検索結果とユーザーの質問の両方を LLM にインポートします。インターネット検索をサポートするには、EAS の パブリックネットワーク接続を設定 する必要があります。
チャット(ナレッジベース)
ベクトルデータベースから取得した結果をユーザーの質問とマージし、選択したプロンプトテンプレートに入力してから、プロンプトを LLM に送信して回答を生成します。
一般パラメーター
パラメーター
説明
ストリーミング出力
ストリーミングモードで結果を生成するかどうかを指定します。デフォルトでは、[ストリーミング出力] が選択されています。
引用が必要
回答に引用を含めるかどうかを指定します。
マルチモーダル LLM での推論
マルチモーダル LLM を使用するときに画像を表示するかどうかを指定します。
ベクトル検索パラメーター。次のベクトル検索方法がサポートされています。
埋め込みのみ:ベクトルデータベースベースの検索を使用します。
キーワードのみ:キーワードベースの検索を使用します。
ハイブリッド:ベクトルデータベースベースの検索とキーワードベースの検索のマルチチャネルリコールフュージョンを使用します。
LLM 関連のパラメーター
温度:生成されるコンテンツのランダム性を制御します。温度の値が低いほど、決定論的で固定された出力が得られ、温度が高いほど、多様で創造的な結果が得られます。
モデル推論を実行します。
注: 特定のスタックの可用性は、選択した App Service プラン レベルとオペレーティング システムによって異なる場合があります。
検索:キーワード
Serverless Computingを質問として入力します。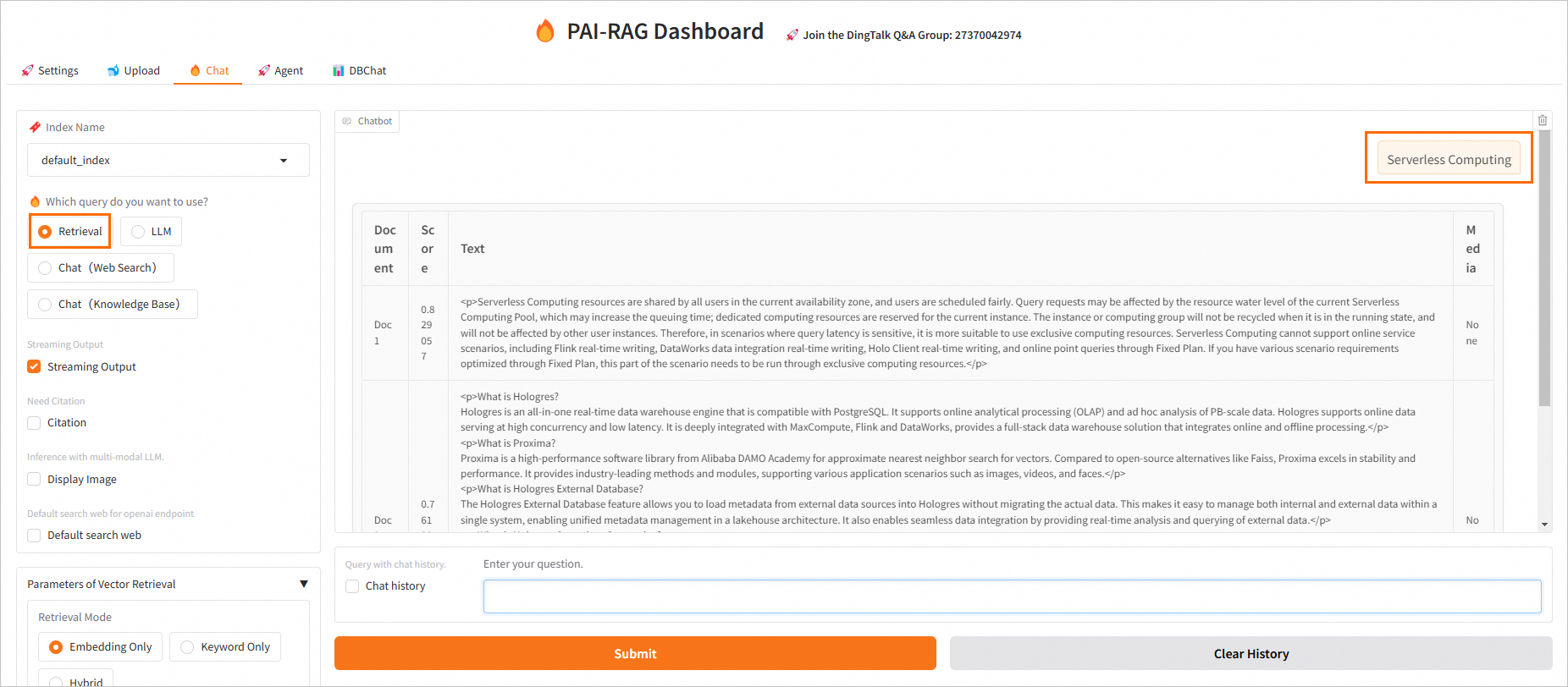
LLM:
固定プランを使用しているときに Hologres Serverless Computing を使用してクエリを高速化できますか。を質問として入力します。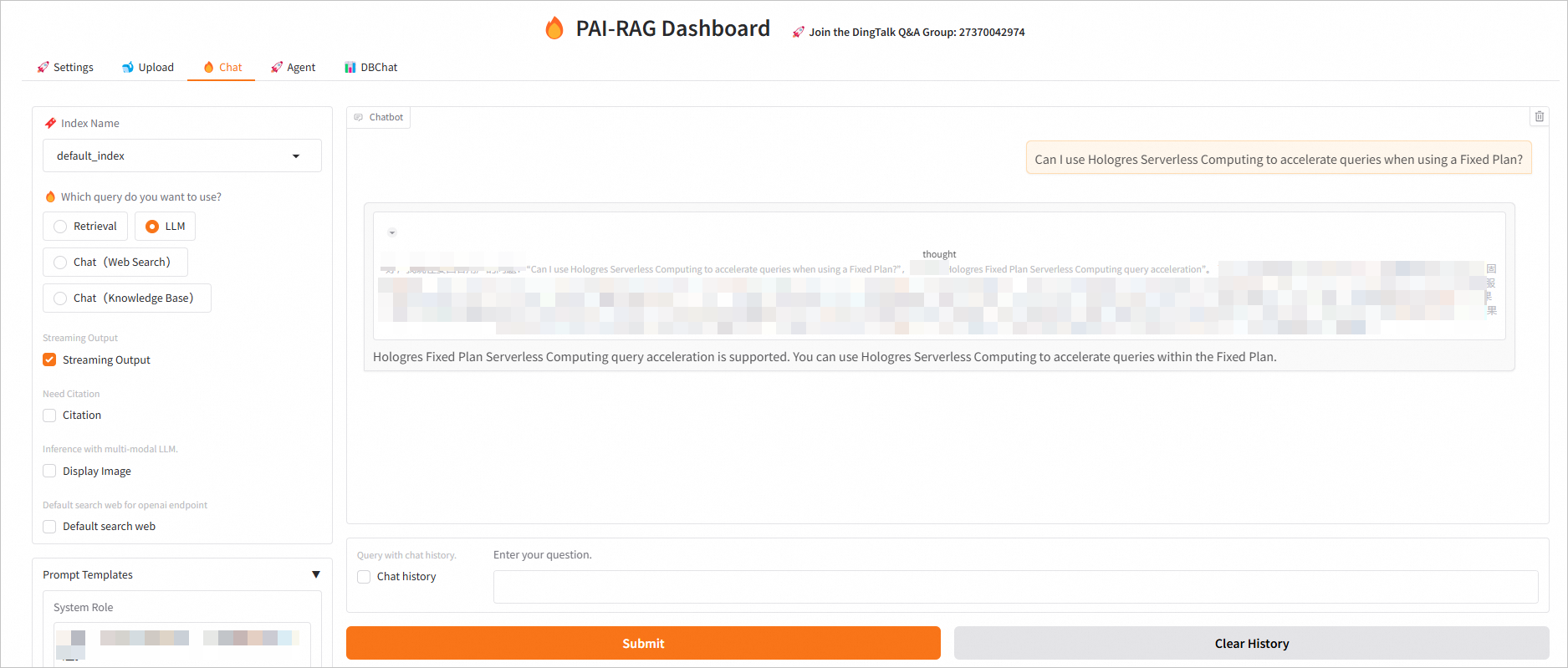
チャット(ナレッジベース):
固定プランを使用しているときに Hologres Serverless Computing を使用してクエリを高速化できますか。を質問として入力します。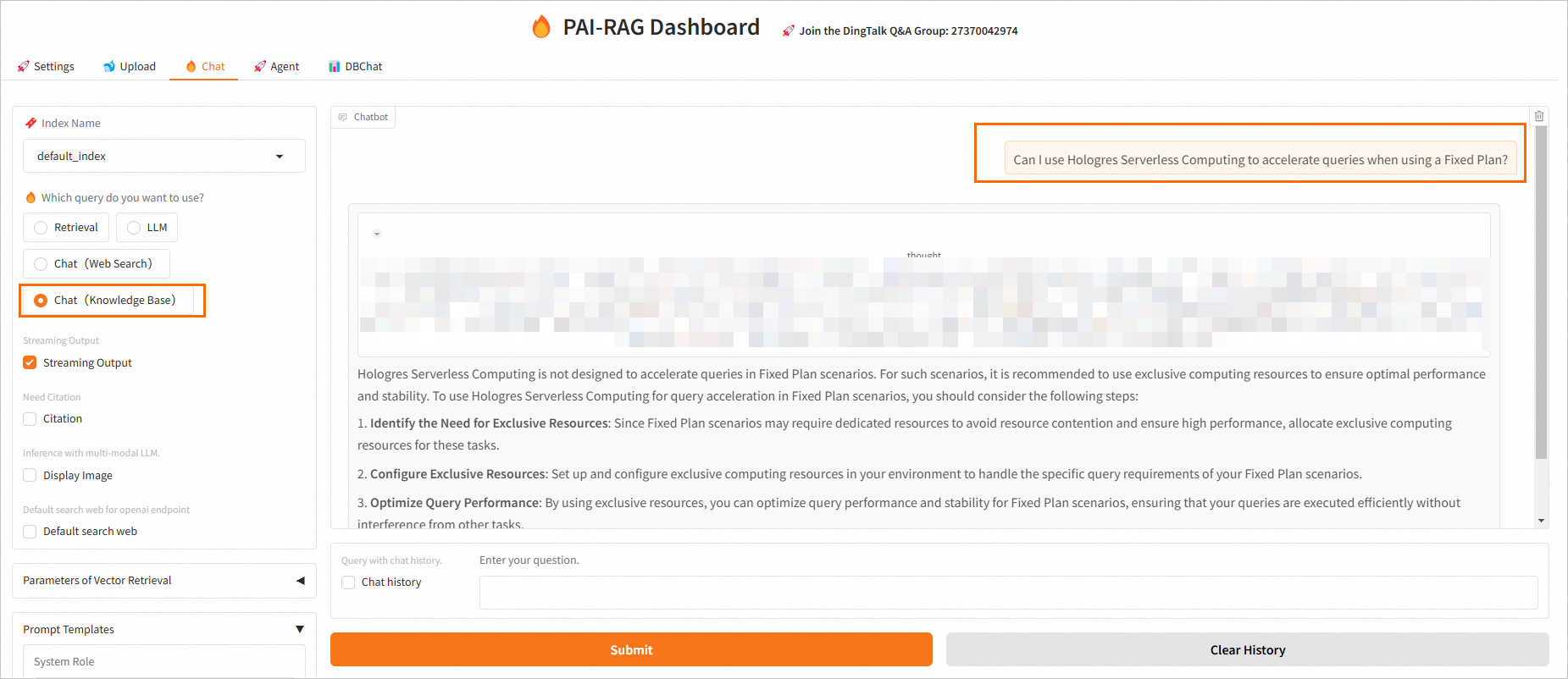
ステップ4:API 操作を呼び出してモデル推論を実行する
Web UI で RAG ベースのチャットボットの Q&A パフォーマンスをテストした後、次の手順を実行して PAI が提供する API 操作を呼び出し、RAG ベースのチャットボットを業務システムに適用できます。
RAG ベースのチャットボットの呼び出し情報を取得します。
前提条件
[基本情報] セクションで、[エンドポイント情報を表示] をクリックします。
呼び出し方法[呼び出し方法] ダイアログボックスで、ネットワーク環境に基づいてモデルサービスのエンドポイントとトークンを取得します。
API 操作を呼び出します。詳細については、「RAG ベースの LLM チャットボットの API を呼び出す」をご参照ください。
参照資料
RAG ベースの LLM チャットボットの詳細については、「RAG ベースの LLM チャットボット」をご参照ください。
Hologres のベクトル計算機能の詳細については、「Proxima ベースのベクター処理」をご参照ください。