Hologres V4.0 以降は、仮想ウェアハウスインスタンスのマルチクラスターとAuto Scaling をサポートしています。仮想ウェアハウスは複数のクラスターにスケールアウトでき、ロードに基づいてクラスター数を自動的にスケーリングします。この機能は、高同時実行リクエストシナリオに対応し、仮想ウェアハウス内でリソース分離を提供します。
アーキテクチャの原則
-
マルチクラスターが有効になっていない場合、仮想ウェアハウスのすべての計算リソースは単一のクラスターに属します。この仮想ウェアハウスに送信されるすべてのリクエストは、これらの計算リソースを共有します。マルチクラスターが有効になっていない場合の仮想ウェアハウスインスタンスのアーキテクチャの詳細については、「仮想ウェアハウスインスタンスのアーキテクチャ」をご参照ください。
-
マルチクラスターが有効になっている場合、仮想ウェアハウス内に複数のクラスターが作成されます。計算リソースはクラスター間で物理的に分離されます。仮想ウェアハウスに送信されるリクエストは、アクセスノード FE によって自動的に負荷分散され、実行のためにクラスターにスケジュールされます。
-
マルチクラスター機能に加えて Auto Scaling を有効にすると、仮想ウェアハウスは、リソース使用量とキューイングを含むロードに基づいて、弾性計算リソースを自動的にスケジュールします。高負荷時には新しいクラスターを起動して、より高い同時実行ロードに対応します。低負荷時には、弾性クラスターを自動的に解放してコストを削減します。

シナリオ
マルチクラスター機能
-
この機能は、小規模から中規模のクエリリクエストを伴う高同時実行シナリオに適しています。クラスターの負荷分離と FE 負荷分散を使用して、より高い同時実行リクエスト容量と自動リクエストグループ化および分離を実現します。
-
この機能は、大規模タスクを伴う低同時実行シナリオには適していません。たとえば、「アーキテクチャ」図の書き込み仮想ウェアハウス 2 は、大容量のオフライン書き込みを処理します。このシナリオでは、単一のクラスターにより多くの計算リソースが必要となるため、手動または時間ベースの弾性スケールアップなどの仮想ウェアハウスのスケールアップ機能がより適切です。
Auto Scaling 機能
Auto Scaling は次のシナリオに適用されます。
-
小規模から中規模のクエリリクエストを伴う高同時実行シナリオ:これはマルチクラスターシナリオと同じです。
-
予測不能なリクエストピーク:ピークが予測可能な場合は、クラスター数を手動で調整するか、時間ベースの弾性スケールアップを使用して管理できます。
用語集
マルチクラスターの概念、インスタンス、および仮想ウェアハウスレベルの計算リソースの定義については、「リソース弾性概要」をご参照ください。
以下は、インスタンスのリソース使用量の例です。
-
インスタンス
-
インスタンス予約済みリソース:64 CU。これには以下が含まれます。
-
割り当て済みリソース:32 CU。これらは init_warehouse 仮想ウェアハウスの予約済み計算リソースです。
-
未割り当てリソース:32 CU。これらのリソースを使用して、新しい仮想ウェアハウスを作成したり、init_warehouse 仮想ウェアハウスの予約済み計算リソースを増やしたりできます。
-
-
インスタンス弾性リソース:32 CU。これらは、弾性機能を使用して init_warehouse 仮想ウェアハウスによって起動される計算リソースです。
-
-
init_warehouse 計算グループ:
-
予約済みクラスター数:1。
-
単一クラスター仕様:32 CU。
-
予約済みリソース:32 CU (1 × 32)。
-
現在のクラスター数:2。これには、1つの予約済みクラスターと1つの弾性クラスターが含まれます。
-
弾性リソース:32 CU。これらは、Auto Scaling 機能によって起動される計算リソースです。
-
合計計算リソース:64 CU。これには、32 CU の予約済みリソースと 32 CU の弾性リソースが含まれます。
-
課金
-
インスタンス予約済みリソース:これらは仮想ウェアハウスインスタンスによって専用に使用される計算リソースです。インスタンス課金方法 (サブスクリプションまたは従量課金) に基づいて課金されます。
-
Auto Scaling 計算リソース:これらは、Auto Scaling を介して仮想ウェアハウスによって起動される追加の計算リソースです。課金数式は次のとおりです。
Cost = Actual launched elastic resources (CU*hour) * Unit price of resource。特定の単位価格については、「課金概要」をご参照ください。説明-
システムは、インスタンスの現在の弾性リソース使用量を毎分記録します。毎時間、システムは使用量を計算し、単位変換を実行し、時間ごとの請求をプッシュします。その後、料金はご利用のアカウントから自動的に差し引かれます。
-
インスタンス弾性リソースは、未割り当てインスタンスリソースとは独立しています。インスタンスに未割り当ての予約済みリソースがある場合でも、Auto Scaling は未割り当てのリソースを使用する代わりに、追加の弾性計算リソースを起動します。
-
制限事項
-
Hologres V4.0 以降のみが、仮想ウェアハウスのマルチクラスターおよびAuto Scaling 機能をサポートしています。
-
仮想ウェアハウスインスタンスのみがサポートされています。Serverless インスタンスまたは汎用インスタンスはサポートされていません。
-
サポートされているリージョン:
-
マルチクラスター機能:すべてのリージョンでサポートされています。
-
Auto Scaling 機能:
リージョン
Auto Scaling サポート
説明
中国 (杭州)、中国 (上海)、中国 (北京)、中国 (深セン)
サポート済み
このリージョンはパブリックプレビュー中です。ご利用の Alibaba Cloud アカウントを使用してフォームに記入し、トライアルを申請してください。
中国 (成都)、中国 (香港)、シンガポール、ドイツ (フランクフルト)、米国 (シリコンバレー)、米国 (バージニア)、UAE (ドバイ)、日本 (東京)、マレーシア (クアラルンプール)、インドネシア (ジャカルタ)、Finance Cloud China (Shanghai)、Alibaba Gov Cloud China (Beijing)、Finance Cloud China (Shenzhen)
サポートされていません
トライアルを申請できません。
-
注意事項
-
マルチクラスターおよびAuto Scaling 機能を使用するには、次の権限が必要です。
-
Alibaba Cloud アカウントまたは AliyunHologresWarehouseFullAccess 権限が付与された Resource Access Management (RAM) ユーザーを使用する必要があります。この権限には、Hologres Management Console への読み取り専用アクセスと Auto Scaling の構成権限が含まれます。権限付与方法の詳細については、「RAM ユーザーに権限を付与」をご参照ください。
-
アカウントはインスタンス内でスーパーユーザー権限を持っている必要があります。権限付与方法の詳細については、「インスタンスの RAM ユーザーに開発権限を付与」をご参照ください。
-
-
仮想ウェアハウス内のクラスター数を増減すると、パフォーマンスに影響を与える可能性があります。詳細については、「仮想ウェアハウスの管理」をご参照ください。
-
同じ仮想ウェアハウスでは、時間ベースの弾性と Auto Scaling を同時に使用することはできません。
-
Auto Scaling が構成されている仮想ウェアハウスの場合でも、Hologres Management Console で、スケールアップ/スケールダウン、開始/停止、削除など、すべての仮想ウェアハウス管理操作を実行できます。
-
Auto Scaling リソースは従量課金計算リソースであり、正常な起動は保証されません。詳細については、「モニタリングとアラート」をご参照の上、失敗したイベントに対する CloudMonitor アラートを構成してください。
マルチクラスターユーザーガイド
仮想ウェアハウスの「予約済みクラスター数」を変更することで、マルチクラスター機能を有効にできます。この操作の詳細については、「仮想ウェアハウスの管理」をご参照ください。
Auto Scaling ユーザーガイド
仮想ウェアハウスの Auto Scaling スイッチを有効にできます。これにより、仮想ウェアハウスは、予約済みクラスター数に加えて、リソース使用量とキューイングを含むロードに基づいて、弾性クラスターを自動的にスケーリングできます。
アクセス
-
Hologres Management Console にログインします。トップメニューバーの左上隅で、目的のリージョンを選択します。
-
左側のナビゲーションウィンドウで、Instances を選択します。対象の Instance ID/Name をクリックして、Instance Details ページに移動します。
-
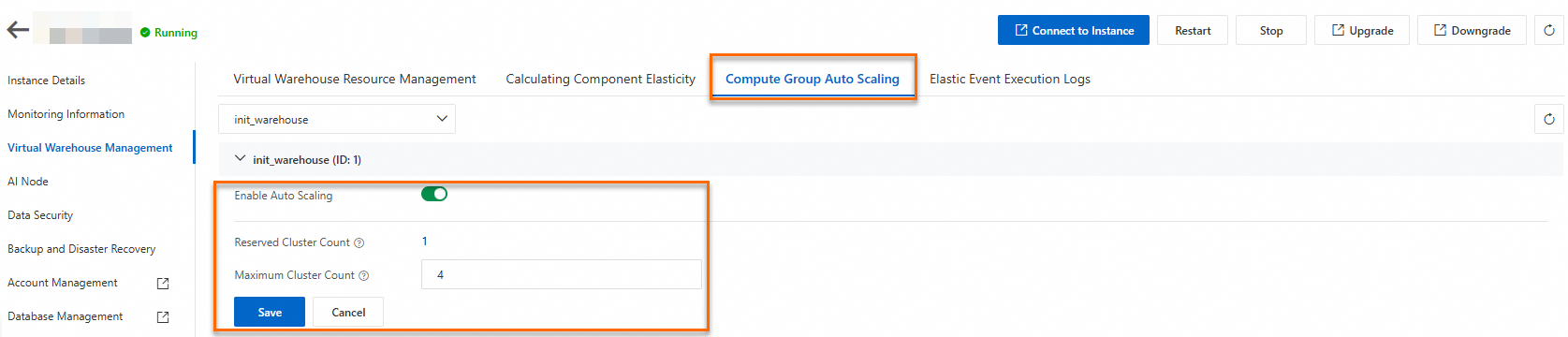
インスタンスの詳細ページで、左側のナビゲーションウィンドウにある仮想ウェアハウスの管理をクリックします。次に、ページ右側で仮想ウェアハウス自動スケーリングタブを選択します。
-
「自動スケーリングを有効にする」をクリックして、オートスケーリング機能を有効にします。「クラスターの最大数」を設定し、「保存」をクリックして設定を適用します。
例
前のセクションで説明したように Auto Scaling を有効にした後 (単一クラスター仕様:32 CU、予約済みクラスター:1、最大クラスター:4)、次の手順に従って Auto Scaling 機能を検証できます。この例では、ネイティブ PostgreSQL 性能テストツールである pgbench を使用します。
-
テストテーブルを作成し、Hologres にデータを書き込みます。
CREATE TABLE tbl_1 (col1 INT, col2 INT, col3 TEXT); CREATE TABLE tbl_2 (col1 INT, col2 INT, col3 TEXT); INSERT INTO tbl_1 SELECT i, i+1, md5(random()::TEXT) FROM generate_series (0, 500000) AS i; INSERT INTO tbl_2 SELECT i, i+1, md5(random()::TEXT) FROM generate_series (0, 500000) AS i; -
ストレステストサーバーで、
select.sqlという名前の SQL ファイルを作成し、次の SQL ステートメントを追加します。EXPLAIN ANALYZE SELECT * FROM tbl_1 LEFT JOIN tbl_2 ON tbl_1.col3 = tbl_2.col3 ORDER BY 1; -
ストレステストサーバーで、パスワードを環境変数として設定します。
export PGPASSWORD='<AccessKey_Secret>' -
次のストレステストコマンドを実行します。パラメーター構成の詳細については、「Hologres への接続と開発」をご参照ください。
pgbench -c 30 \ -j 30 \ -f select.sql \ -d <Database> \ -U <AccessKey_ID> \ -h <Endpoint> \ -p <Port> \ -T 1800次の図は、ストレステスト中の計算グループの監視メトリクスを示しています。
-
クラスター CPU 使用率:
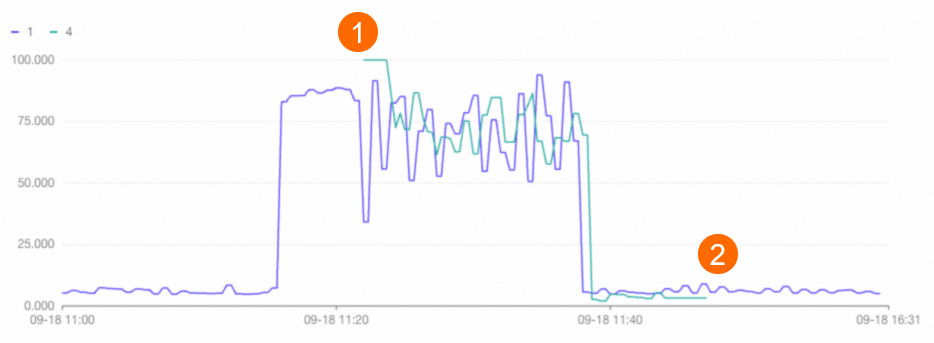
-
クラスター 1 は高負荷が持続し、Auto Scaling (位置 1) をトリガーしてクラスターを1つ追加しました。
-
ストレステスト後、2つのクラスターは低負荷になり、Auto Scaling (位置 2) をトリガーしてクラスターを1つ削除しました。
-
-
仮想ウェアハウス CPU 使用率:
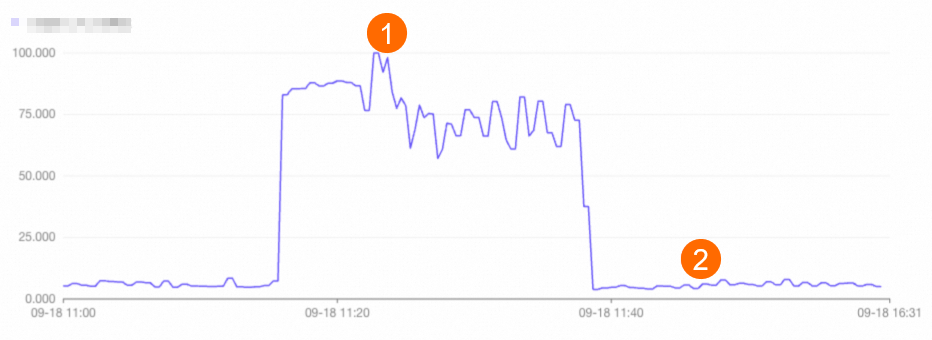
-
クラスターの自動弾性増加は、計算グループの CPU 使用率が継続的に 85% を超えた場合に発生します。
-
クラスターが追加された後、仮想ウェアハウス全体の CPU 使用率は約 70% に低下しました。
-
-
モニタリングとアラート
監視メトリクス
Hologres Management Console で、次の監視メトリクスを表示できます。必要に応じて、これらのメトリクスに対応するアラートルールを構成できます。詳細については、「Hologres コンソールの監視メトリクス」をご参照ください。
-
クラスター CPU 使用率
-
クラスターメモリ使用量
-
仮想ウェアハウスの Auto Scaling によって起動されたコア数
弾性イベント実行ログ
-
「仮想ウェアハウスの管理」ページに移動します。エラスティックイベント実行ログ タブをクリックします。
-
Auto Scaling の時間範囲を選択して、過去の弾性イベントの詳細を表示します。詳細には、実行時間、仮想ウェアハウス、実行ステータス、イベントタイプ、予約済みクラスター数、およびターゲットクラスター数が含まれます。
CloudMonitor イベント
Hologres Auto Scaling がクラスターの水平スケーリングを実行するイベントは、CloudMonitor に記録されます。
-
CloudMonitor イベントセンターに移動します。[システムイベント] ページで、[イベントモニタリング] エリアのプロダクトとして Hologres を選択します。その後、自動スケーリングのアップグレード/ダウングレードイベントをモニターできます。これらのイベントには、以下が含まれます。
-
Instance:Warehouse:AutoElastic:Start:仮想ウェアハウスの Auto Scaling の開始イベントを示します。 -
Instance:Warehouse:AutoElastic:Finish:仮想ウェアハウスの Auto Scaling の完了イベントを示します。 -
Instance:Warehouse:AutoElastic:Failed:仮想ウェアハウスの Auto Scaling の失敗イベントを示します。
-
-
CloudMonitor イベントに基づいて、通知やアラートなどの追加操作を構成できます。詳細については、「システムイベントアラートの使用」をご参照ください。
次の例は、クラスターを追加できなかった失敗した Auto Scaling イベントの CloudMonitor イベントの詳細を示しています。
{
"status": "Failed",
"instanceName": "<instance_id>",
"resourceId": "<instance_resource_id>",
"content": {
"AutoElasticCPU": <cpu_num>,
"ScaleType": "ScaleOut",
"ScheduleId": "xxxxxx",
"WarehouseId": "<warehouse_id>",
"WarehouseName": "<warehouse_name>"
},
"product": "hologres",
"time": 1722852008000,
"level": "WARN",
"regionId": "<region>",
"id": "<event_id>",
"groupId": "0",
"name": "Instance:Warehouse:TimedElastic:Failed"
}ActionTrail
Auto Scaling 構成の編集など、Hologres Management Console で実行された操作、および Auto Scaling によって実行された実際のクラスターのスケーリング操作は、ActionTrail に記録されます。詳細については、「イベント監査ログ」をご参照ください。